- Taylor's Theorem.
Thursday, November 13, 2008
Definition of derivative Repeated.Consequences Differentiability implies continuity. Algebraic combinations of differentiable functions are differentiable. xn is differentiable (when n is a positive integer).
The Chain Rule Proved very slickly by stuffing one linear approximation inside another and realizing that the consequence was, indeed, the Chain Rule.
The beginnings of a gallery
Everyone, young and old, learned and naive, should have a gallery
of functions to be considered when theorems and definitions are
considered. The instructor spent a chunk of time identifying good
initial candidates for such a gallery, from "ugly" to "nice". Of
course, the beauty of the qualities mentioned depend quite a bit on
the observer!
Writing in progress!
- The inverse (?) ruler function
- The characteristic function of the rationals
- The ruler function (Dirichlet?)
- x sin(1/x)
- x2sin(1/x)
- Bumps, etc. (due to Emile Borel)
- The exponential function
Monday, November 10, 2008
Increasing functions
I discussed increasing functions and how often they can be
discontinuous. This is in the textbook. I wrote and gave a warm
advertisement for a book: Functional Analysis by F. Riesz
and Nagy (also known and pronounced as "rees-naje". Reprinted by Dover
and on sale at Amazon for 14.93. A wonderful book!
Mr. Skalit
Discussed several problems in chapter 4 he had prepared with the help
of Mr. Kowalick. In particular, we saw
that metric spaces were normal.
Differentiability
The instructor defined and began a discussion of
differentiability and announced his preference for a definition
written in this form:
f:[a,b]→R is differentiable at c∈[a,b] with derivative Q if
there is a function E defined in a neighborhood of 0 with
limv→0E(v)=0 so that
f(x)=f(c)+(Q)(x-c)+E(x-c). This definition doesn't have any
divisions.
Some simple consequences were mentioned but the Chain Rule will be verified next time.
An exam was announced, to be given in two weeks. Ms. Hood volunteered (??!) to present a problem about differentiation, with the help of Mr. Baldwin.
Thursday, November 6, 2008
The due date for the next homework assignment is Monday's class meeting.
Finishing the proof
We used compactness to verify uniform continuity. I continued with the
attempted (or rather, interrupted) proof. So X is
compact, and we have sequences {pn} and {qn}
with d(pn,qn)<1/n and
d(f(pn),f(qn))≥ε. Now {pn}
is a sequence in a compact metric space. The sequence itself may not
converge, but compactness always guarantees that the existence of a
convergent subsequence, {pnj}. We know that
there is an x so that
limj→∞pnj=x. Notice that
the sequence {qn} is sort of "dragged along" by the
corresponding sequence of pn's. That is, I claim the
subsequence {qnj} also converges, and its limit
is x. Why is that? Well,
d(qnj,x)Δ≤d(qnj,pnj)+d(pnj,x).
The first term on the right is <1/nj. For j large, this
will be small and stay small. And the second term behaves
similarly, because the p-subsequence converges to x. Now f is
continuous at x. Therefore given ε>0, we can find a
δ>0 so that if d(x,y)<δ then
d(f(x),f(y))<ε. But choose J so that for j≥J, both
d(qnj,pnj) and
d(pnj,x) are less than δ/2. Then
d(qnj,x)<δ so
d(f(qnj),f(x))<ε and
d(f(pnj),f(x))<ε. Again the triangle
inequality applies, so
d(f(pnj),f(qnj))<2ε
for j>J. This is a contradiction to how we created the two
sequences initially (that is, it will be a contradiction if you allow
me to relabel 2ε as ε!). So we are done.
A consequence of uniform continuity?
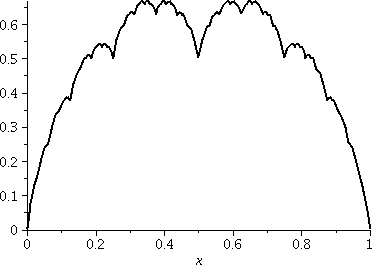 I proved a rather remarkable result, and this will be especially
wonderful in many applications later. I mentioned that a "random" (?)
continuous real-valued function on R can be rather bizarre. One
explicit well-known example is xsin(1/x) on [0,1]. For another example
with even worse behavior, I investigated the Takagi function
graphically in the
9th meeting of the Byrne Seminar on Experimental
Math. A picture drawn there is shown to the right. The Takagi
function (named for Teiji
Takagi (1875--1960)) happens to be an example of a continuous
nowhere differentiable function on [0,1], and it is also a function
which is neither increasing nor decreasing on any subinterval of [0,1] of positive length. So
continuous functions can be weird and wonderful. In view of
that, the result here is almost amazing. If you are willing to
tolerate only a little bit of error (as little as you would like) you
can approximate any continuous function by a piecewise constant step
function with finitely many values. David Tall, an English mathematics
educator, gives a detailed discussion of the properties of this function
(aimed at teachers) here.
I proved a rather remarkable result, and this will be especially
wonderful in many applications later. I mentioned that a "random" (?)
continuous real-valued function on R can be rather bizarre. One
explicit well-known example is xsin(1/x) on [0,1]. For another example
with even worse behavior, I investigated the Takagi function
graphically in the
9th meeting of the Byrne Seminar on Experimental
Math. A picture drawn there is shown to the right. The Takagi
function (named for Teiji
Takagi (1875--1960)) happens to be an example of a continuous
nowhere differentiable function on [0,1], and it is also a function
which is neither increasing nor decreasing on any subinterval of [0,1] of positive length. So
continuous functions can be weird and wonderful. In view of
that, the result here is almost amazing. If you are willing to
tolerate only a little bit of error (as little as you would like) you
can approximate any continuous function by a piecewise constant step
function with finitely many values. David Tall, an English mathematics
educator, gives a detailed discussion of the properties of this function
(aimed at teachers) here.
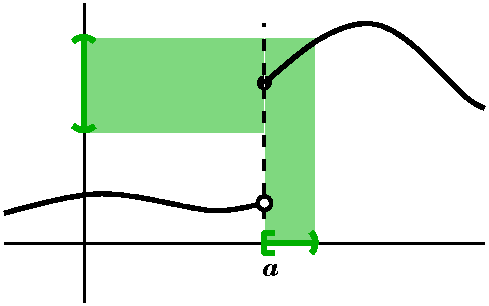
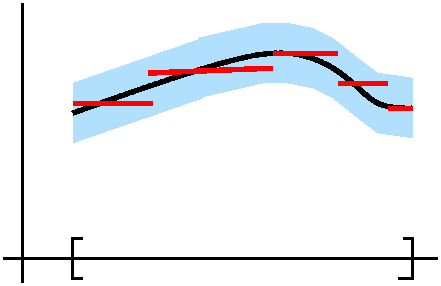 To the right is a possible picture. The graph of a continuous function
defined on a closed bounded interval is shown. The light blue band
around the graph is ±ε deviation from the graph. The red
horizontal lines are the graph of an approximating piecewise constant
function with finitely many values. It "steps" because the values it
assumes are taken on finitely many intervals of positive length. The
result is remarkable to me, because no matter how bad (?) the function
f can be, we can replace it by something with finite data (!) if you
allow me to commit a very small error. In many applications, the step
function is too coarse, and we may want piecewise linear or
differentiable or ... whatever. But this result is the initial
version. So:
To the right is a possible picture. The graph of a continuous function
defined on a closed bounded interval is shown. The light blue band
around the graph is ±ε deviation from the graph. The red
horizontal lines are the graph of an approximating piecewise constant
function with finitely many values. It "steps" because the values it
assumes are taken on finitely many intervals of positive length. The
result is remarkable to me, because no matter how bad (?) the function
f can be, we can replace it by something with finite data (!) if you
allow me to commit a very small error. In many applications, the step
function is too coarse, and we may want piecewise linear or
differentiable or ... whatever. But this result is the initial
version. So:
Theorem Suppose f is a continuous real-valued function on
[a,b], and ε>0. Then there is a function g:[a,b]→R so
that the range of g is finite, g-1(y) is either empty
or a finite set of intervals for all y∈R, and
|g(x)-f(x)|<ε for all x∈[a,b].
Proof [a,b] is compact and f is continuous, so f is
uniformly continuous on [a,b]. Therefore we can find
δ>0 so if |f(x1-x2|<δ, then
|f(x1)-f(x2)|<&epsilon. Now find a positive
integer n so |b-a|/n<δ. For all integers j between 0 and n-1,
we know that |f(a+j(b-a)/n)-f(x)|<ε for x between
a+j(b-a)/n and a+(j+1)(b-a)/n. Define g by this "rule": if x is
between a+j(b-a)/n and a+(j+1)(b-a)/n, g(x)=f(a+j(b-a)/n). Then we're
done!
Advertisement This is magic, and you should realize it. We have
developed a considerable amount of technique, and now many results,
including what's in this lecture, are "easy" to verify. Once we have
the step function, we can (approximately) integrate f, find its
(approximate) mean and standard deviation, etc.
d) implies our first inverse function theorem
There are a collection of results which are referred to as inverse
function theorems, including, especially, a result about
differentiable mappings between open subsets of Rk. This
wonderful result will be proved in 412. One of its standard proofs
uses the following result, which is also very frequently invoked in
algebraic topology. So:
Theorem Suppose f:X→Y is a bijection (1-1 and onto -- basically,
X and Y are the same as sets!, f is continuous, and X is
compact. Then f–1 is continuous.
Proof We will use d). To show that f–1 is
continuous, we will investigate if (f–1)–1=f
has the following property: if C is closed in X, then f(C) is closed
in Y. But X is compact, so C, a closed subset, is compact. f(C), a
continuous image of a compact subset, is compact in Y. But compact
subsets of metric spaces are closed, so f(C) is closed in Y. And we
are done!
Advertisement This is magic. There is hardly any effort
to verify a result which is used constantly. Be aware, if you know
what a topological space is, that the result is true if only X is a
compact Hausdorff space.
[0,1)
As I mentioned, NJ State Law QD 324-17 (a math regulation)
requires that this example be presented immediately after the
statement and proof of the previous theorem.

Consider [0,1) with its usual topology. This is 1 point away (?) from being compact. The mapping f:[0,1)→R2 given by f(t)=(cos(2πt),sin(2πt)) is continuous. Considering the picture is more fun. The range of f is x2+y2=1, a closed and bounded subset of R2, so the range is compact. But f–1 is not continuous. Why? The picture shown to the right gives some idea. Take the magenta colored dots in the range, which approach the image of 0 from the wrong way. These dots have a limit, the image of 0. But pulled back to [0,1), we get the green dots which have no limit in the domain of f. Thus f–1 takes a convergent sequence to a sequence which does not converge, and a continuous function can't do that.
A major result used in calculus
If f:[a,b]→R is continuous, then f([a,b])=[c,d]. This result
includes the Intermediate and Extreme Value Theorems. The proof is
(now!) easy. A proof from just the definition of continuity is likely
to be tedious. So why is this result true? [a,b] is compact and
connected, so f([a,b]) is compact and connected. Connected subsets of
R are intervals. The only compact intervals are those which are closed
and bounded. So we're done.
Connectedness
As mentioned, the lecturer thinks that connectedness as defined is a
difficult concept. The definition has a not very prominently
mentioned, so it may be irritating to verify that something is
connected (or not connected). There is a negative (?) aspect about the
logic. So here is a variant.
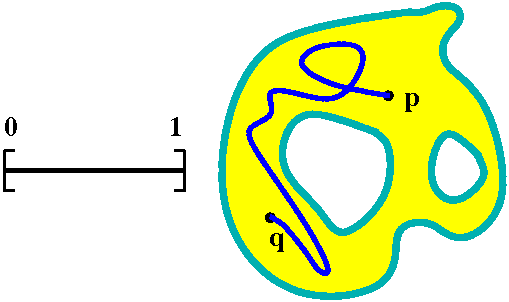 Arcwise connected
Arcwise connected
A metric space X is arcwise connected or pathwise
connected (both phrases are used) if for all pairs of points p and
q in X, there is a continuous function c:[0,1]→X so that c(0)=p
and c(1)=q.
Theorem If X is a pathwise connected metric space, then X is
connected.
Proof If X is not connected, then X=A∪B with A and B open,
non-empty, and disjoint. Take p∈A and q∈B. Then pathwise
connected provides a continuous c as in the definition. Since
0∈c–1(A) and 1∈c–1(B) and c is
continuous, then (using c)!) these are open subsets of [0,1],
disjoint, non-empty. But [0,1] is connected, which is a
contradiction.
Star-shaped subsets of Rn are arcwise connected, because a star-shaped set has a center, v (or, at least one center!), so that given any p in the set, the line segment from p to v is in the set. So we can connect p to q by detouring (?) through v. Convex sets are star-shaped. Open balls are therefore star-shaped.
For open subsets of Rn...
Much, although not all, of analysis in 411-412 will be in open subsets
of Rn. For such subsets, the concepts of arcwise connected
and connected coincide.
Theorem Suppose U is an open subset of Rn. Then U is
connected if and only if U is arcwise connected.
Proof I did not offer a proof in class, but look: suppose U is
connected. I want to show that U is arcwise connected. Fix
p∈U. Take A to be the set of all points q which can be
"connected" to p with a continuous image of [0,1], as in the
definition of arcwise connected. Then A is a connected set, surely. I
claim that A is open. Well, if q∈A, then since U is open, there
is r>0 with Nr(q)⊂U. I can connect from p to any
point in Nr(q) with a detour through q. So A is open. Also,
A is closed, since a limit point of q's, call it v, has a ball
Ns(v)⊂U. At least one q is in Ns(v), so go
from p to that q and then, inside the convex ball, to v. Since A is
open and closed and non-empty, A must be all of the connected set
U. (Or else what is left out is open, also, and makes U disconnected!)
Not the other way!
For unfriendly sets, arcwise connected and connected may be
different. For example, the topologist's
sine curve is connected but not arcwise connected.
There is a purported proof in the linked page, without much details
and also without a picture! Here is
a Wikipedia reference, with a picture, but not even a candidate for a
proof.
I sketched a rather clumsy proof. My effort would involved repeated use of the Intermediate Value Theorem.
Monday, November 3, 2008
Definitions (?) and theorem about continuityHere are a bunch of equivalent statements about a function f:X→Y, where X and Y are metric spaces.
a) For all p∈X, with f(p)=q, and for all ε>0, there is δ>0 so that if d(x,p)<δ then d(f(x),q)<ε.
b) If {xj} is a convergent sequence in X with limj→∞xj=p, then {f(xj)} is a convergent sequence in Y with limj→∞f(xj)=f(p).
c) If U is open in Y, then f–1(U) is open in X.
d) If C is closed in Y, then f–1(C) is closed in X.
All except the last were previously shown as equivalent. The last is an easy consequence of set and function manipulation results, using fact that a set is closed exactly when its complement is open. The great freedom we now have is to investigate and diagnose results about continuous functions (those which satisfy any/all of the previous properties) and use whichever characterization we like. Some are more convenient to use than others in certain situations.
Composition of continuous functions
We're given f:X→Y and g:Y→Z both continuous. Use c). Take U
open in Z, then g–1(U) is open in Y, and
f–1(g–1(U))
is open. Now notice that (gof)–1(U)
is the same as f–1(g–1(U)).
Distance as a continuous function
We saw that
d(x,y1)–d(x,y2)≤d(y1,y2)
because (Δ≤)
d(x,y1)<d(y1,y2)+d(x,y2).
Then, switching y1 and y2, we know
|d(x,y1)–d(x,y2)|≤d(y1,y2).
Therefore if f(y)=d(x,y), f satisfies a Lipschitz estimate, and there
must be continuous. See what follows, please.
Lipschitz and locally Lipschitz
A function f:X→Y is Lipschitz
if there is a constant, A≥0 so that
d(f(x1,x2)≤A d(x1,x2)
for all x1, x2 in X. Such a function must be
continuous. Use, for example, a). Given ε>0, take
δ=ε/A (hey, talk to me if A=0 and you can't figure out
what to do).
We'll say f:X→Y is locally Lipschitz if it is Lipschitz in
a neighborhood of every point. That is, given x∈X, there is
r>0 and A≥0 (A may depend on r and x) so that for all
x1, x2 in Nr(x),
d(f(x1,x2)≤A d(x1,x2).
Such functions are also continuous (same proof!).
Lipschitz conditions are fundamentally important in the standard statement of the existence and uniquenss theorem of ordinary differential equations.
MVT implies Lipschitz
This is jumping ahead a bit, but if f:R→R is differentiable, then
the Mean Value Theorem implies that
|f(b)–f(a)|≤|f´(c)| |b–a| for at least one c in the
interval between a and b. Therefore if we "happen" to know that
f´ is bounded on that interval, then f will be Lipschitz there,
and we know a Lipschitz constant (the sup of the absolute values of
the derivative). Of course, a differentiable function will
automatically be continuous, but this maybe gives some feeling for
what Lipschitz means: the mapping "stretches" distances by no more
than a factor of A, the Lipschitz constant.
Hölder and locally Hölder
Here is a similar idea. Suppose A≥0 and α≥0. Then
f:X→Y satisfies a (uniform) Hölder
condition if d(f(x1,x2)≤A (d(x1,x2))α. For example, the function
f:R→R defined by the formula f(x)=sqrt(|x|) satisfies such a
condition with α=1/2. It does not satisfy a Lipschitz
condition on all of R.
An analogous definition can be made for locally Hölder.
Functions satisfying Hölder conditions are also continuous. For example, take δ=(ε/A)1/α. The "average" continuous function on [0,1] is not differentiable, but I think it does satisfy, in most places, a Hölder condition of order 1/2. So this is important in many fields (e.g., probability, math finance, physics [Brownian motion], etc.).
Algebraic combinations
Sums, products, and quotients of complex-valued continuous functions are
continuous. Probably the simplest way to verify this is by appealing
to similar statements about convergent sequences and using the
criterion in b) above.
Vector-valued functions and their components
Suppose
F=(f1,f2,...,fk):X→Rk.
Then each component, fj, is a function from X to R. And F
is continuous if and only if each of the fj's is
continuous. The easiest way to see this is probably to contrast the
Euclidean metric, L2, in Rk with the
L1 and L∞ metrics, and use the constants
we have previously obtained in problem #3 of Homework #2 to show the
needed implications. This is also in the text, of course.
Perturbing the definition of continuous
Suppose f:X→Y. A version of the official definition of
continuity follows:
∀p∈X∀ε>0∃δ>0 if x∈X with d(x,p)<δ then d(f(x),f(p))<ε.A wonderful thing you could do to yourself is change the order or the type (∀ to ∃ or ∃ to ∀) of the quantifiers and see what that does to the definition. For example:
∀p∈X∃δ>0∀ε>0 if x∈X with d(x,p)<δ then d(f(x),f(p))<ε.I think such functions still are continuous, but additionally there aren't "very many" of them -- they are functions which are locally constant. That is, any function at any point has a neighborhood where it is constant. You might want to prove that such a function on a connected metric space must be actually constant.
What about this?
Here's another change to the definition.
∀ε>0∃δ>0 if x,p∈X with d(x,p)<δ then d(f(x),f(p))<ε.These functions are also continuous. But does every continuous function satisfy this statement? The statement is more mysterious, since, given ε>0, we're making a selection of δ>0 which will "work" for any pair of points in X.
An example
An instructive example is f:R→R defined by f(x)=x2.
We can show that this function does not satisfy the previous
logical statement. We decided that we needed to produce an
ε>0 so that for any δ>0 there are points p, q in X
with d(p,q)<δ with d(f(p),f(q))<ε. Then we quickly
declared that this would be proved if we choose ε=1, say, and
created, for each positive integer n, points pn and
qn so that |pn–qn|<1/n but
|(pn)2–(qn)2|≥1.
The marvelous intervention of Ms. Slusky allowed us to choose pn=n and qn=n+(1/[2n]). We computed |(pn)2–(qn)2| and saw that it was greater than 1. The instructor then drew a picture intending to show that the graph of this f tilted more and more as |x|→∞ so that getting control over |f(x)–f(y)| even if the size of |x–y| was restricted became more difficult. For more pictures, please see the link below.
A definition
f:X→Y is uniformly continuous if
∀ε>0∃δ>0 if x,p∈X with d(x,p)<δ then d(f(x),f(p))<ε.Such functions are extremely important in applications, and even in such basic situations as integration. Please see a digression (or discussion) in Math 503 about uniform continuity in the basic complex variables graduate course.
Some other examples, perhaps elaborate
Example 1 x2 is not uniformly continuous on
R.
Comment about learning stuff Especially in math, when the
defintions get more and more complicated, a very good idea is to find
things which do not satisfy the definition yet are very closely
related to things which do satisfy the definition. The
differences may be useful in understanding the definition and its
consequences.
Example 2 MVT again: conside the function f:R→R defined by
f(x)=(3/[4+x2])+17x+cos(4x). I claim that f is uniformly
continuous. I'll show this by checking that f satisfies a uniform
Lipschitz condition. Then the same δ can be used for any
ε and any x. Well,
f´(x)=–(6x)/[4+x2]2+17–6sin(x). I claim
that each of the "pieces" of this derivative is bounded in all of
R. That should be clear fro 17 and –6sin(x), so let's look at
(absolute value!) 6x/[4+x2]2 for x>0. Uhh
... this is less than 1. Why?
6x≤[4+x2]2: true for x between 0 and 1,
certainly, since the largest that 6x gets there is 6, and the smallest
that the right-hand side gets is 16. And consider the derivatives:
6≤2([4+x2]2x. The right-hand side is always at least
2(5)2=20 on [1,∞) so it is always larger than 6. Therefore the
original functions have the same inequality on [1,∞). This is
too much work! It should be easier.
Example 3 5sqrt(x)+17x on [0,∞). Well, the derivative is 5/(2sqrt(x))+17. Mr. Leven correctly objected here because the derivative is not bounded on [0,∞). O.k.: the derivative is bounded on [1,∞) so the function is uniformly continuous there. What about on [0,1]. Aha! Look ahead.
A major theorem
If f:X→Y is continuous and X is a compact metric space,
then f is uniformly continuous.
Attempted proof
There's a nice proof in the textbook, using essentially problem 5a)
from the first exam. Let me try to give a different proof. What if the
theorem were false? Then we would have some ε>0 and two
sequences of points {pn} and {qn} (remember the
verification of the x2 example above) so that
d(pn,qn)<1/n but
d(f(pn),f(qn))>ε. This alone is not
enough to guarantee a contradiction, because we could have such
sequences in R and not get into trouble. (In class I gave sequences in
R2, pn=(0,n) and qn=(0,n+{1/n}) but
we already had the examples in the x2 verification.) What
will help us here?
Hint Compactness! This guarantees not that a sequence itself converges, but that some subsequence does. This will be enough to get a contradiction. to be continued ...
Thursday, October 30, 2008
Products of absolutely convergent seriesThe ingredients (hypotheses) include the following:
- An absolutely convergent series, ∑j=1∞aj, with ∑j=1∞aj=A and ∑j=1∞|aj|=C.
- An absolutely convergent series, ∑k=1∞bk, with ∑k=1∞bk=B and ∑k=1∞|bk|=D.
- A summation method, that is, a sequence
{Wt}t=1∞, where
- Each Wt is a finite subset of NxN.
- Wt+1⊂Wt.
- ∪t=1∞Wt=NxN.
 Then (the conclusion!) the sequence {st} converges to AB.
Then (the conclusion!) the sequence {st} converges to AB.
I proved this in detail, perhaps too much detail. The process used the convergence definition applied to the infinite series ∑j=1∞aj and the infinite series ∑k=1∞bk, and the Cauchy criterion applied to ∑j=1∞|aj| and to ∑k=1∞|bk|. The proof used the "technique" of problem 7 in the first exam, and was guided by a version of the rather bizarre picture to the right.
♥Love for absolute convergence♥
The rearrangement result and the product summation result declare that
commutativity and associativity are correct when applied in
(essentially) any way to absolutely convergent series and to their
algebraic manipulations.
Other results about products
I stated Merten's Theorem and another result. Please see the text.
Limits and sequences
I stated the ε–δ definition of limit, and proved that it
was equivalent to the sequential statement. This is as in the text.
Mr. Baldwin kept me honest.
Continuity
I defined continuity of a function at a point, if the function mapped
one metric space to another. Then I defined continuity of a
function. I showed that this definition ("Inverse images of open sets
are open") was equivalent to requiring an ε–δ statement
at each domain/range point pair. This is as in the text. All is an
abstract version of the result on real-valued functions defined on the
real line which was stated several weeks ago.
Pictures
Ms. Pritsker suggested that I try to
show some pictures about what was happening, and I thank her for
this.
| In this first example, the function shown (from R to R) has what's called a jump discontinuity. The inverse image of the green open interval is traced (backwards) and the result seems to be a half-open interval. So this example fails the "inverse image open" criterion for continuity. |
 |
| The second example has a more complicated discontinuity. I tried to sketch, in class and here, the function f whose value, f(x), 0 if x≤0 and is sin(1/x) if x>0. Then the inverse image of a small open interval centered around 0 includes (–∞,0] and also includes a countable collection of open intervals, getting smaller and smaller as they "pile up" at 0. Note, though, that although 0 is in the inverse image, there is no open neighborhood (consider the right "half") which is a subset of the inverse image. |
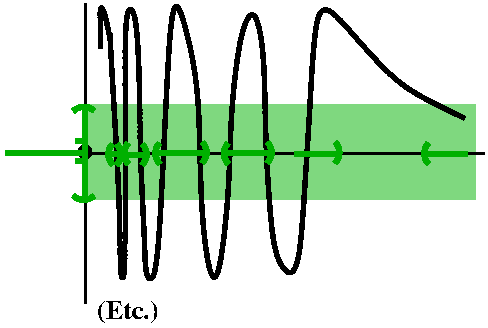
|
The great theorems
Chapter 4 concentrates on precise statements and proofs of some of the
most basic theorems in analysis about continuity. These results seem
to have their historic source (sort of) in the work of Bolzano.
The calculus version of the theorems is the following almost
ludicrously simple statement:
Suppose f:R→R is a continuous function, and a≤b. Then the set of values of f([a,b]) is [c,d] with c<d.This result of course includes the Intermediate Value Theorem and the Extreme Value Theorem. By the way, the converse of this result is not, I believe, correct (that is, continuous functions are not the only functions from R to R which obey the conclusion of this theorem).
Notice that closed bounded intervals in R can be characterized as proper non-empty subsets of R which are both connected and compact. We will prove the result above by showing that continuous images of compact sets are compact, and continuous images of connected sets are connected. Sigh. Both compact and connected are defined in terms of open coverings. So it turns out that the "inverse image open" version of the definition of continuity is exactly suited for quite simple proofs of the results needed. But, please, the apparent simplicity is only superficial. The whole theory is aimed at these results, and 150 years of work have gone into constructing a Definition/Theorem/Proof/Example succession which seems simple and nearly effortless. Historically the results and the ordering involved a great deal of work.
Homework
Please read chapter 4. The top vote-getters in the poll for "Problems
students want to do" are Chapter 3: 6, 10 and Chapter 4: 4, 6,
7, 11. I will add one more problem in a formal assignment on Monday.
Monday, October 27, 2008
Rearrangements of absolutely convergent seriesWe proved this result. How did we do it? Well, we know that ∑j=1∞|aj| converges. And we let A=∑j=1∞aj, since the original series must converge. And σ:N→N is the rearrangement. So we need to analyze the partial sums of ∑j=1∞aσ(j) and look at their differences with A. We used both absolute convergence and the Cauchy criterion for the series with absolute values.
An example
Here is one (delightful?) example of the sort of computation which made people very
uneasy historically. You may remember from the first year of calculus
study (geometric series, Taylor series, remainders, etc.) a fact about
the Alternating Harmonic Series.
ln(2)=1–(1/2)+(1/3)–(1/4)+(1/5)–(1/6)+(1/7)–(1/8)+...That the series converges follows from a version of the Alternating Series Test which we will verify in a few minutes. The specific value of the sum relies on things like Taylor's Theorem.
Now replace each positive term by twice itself minus itself. I hope you can convince yourself this does not change convergence or the sum of the series. Now this is true:
ln(2)=(2–1)–(1/2)+(2/3)–(1/3)–(1/4)+(2/5)–(1/5)–(1/6)+(2/7)–(1/7)–(1/8)+...and now divide this series (and its sum) by 2. I mean (emphasis!) divide everything by 2. Here is the result:
ln(2)/2=1–(1/2)–(1/4)+(1/3)–(1/6)–(1/8)+(1/5)–(1/10)–(1/12)+(1/7)–(1/14)–(1/16)+...It is not difficult to check carefully that what is apparently correct actually is correct. The series on the right-hand side is a rearrangement of the original Alternating Harmonic Series. Wow! This rearrangement converges to half of the original value. We don't really need to know what that value is, but it is (relatively) easy to see that the original value was actually positive. So rearrangements of this series do change the sum!
Riemann Rearrangement Theorem
If a series of real numbers converges yet diverges absolutely
(conditional convergence) then there is a rearrangement which
converges to any real number. I gave a proof of this. This is a weaker
version of the result in the textbook. Please look there.
The better version in the text
Rearrangements can be devised to have the sequence of partial sums
with lim sup and lim inf very arbitrarily specified.
There are versions of the theorem which apply to complex series. The
conclusions then are more complicated, though.
Summation by parts
We went through the discussion of summation by parts. Several students
clearly understood it better than the instructor. Sigh. This was
discussed because summation by parts can be applied to several topics
in Fourier series.
Some consequences (Alternating series test)
We stated and proved the standard alternating series test.
Products of series
Here we began a discussion of products of series, which is a more
complicated undertaking than is immediately apparent. We want to start
with two convergent infinite series, ∑j=1 (or 0)∞aj
and ∑k=1 (or
0)∞bk and then analyze the numbers
ajbk. We'd like to figure out some way to
"assemble" these numbers into an infinite series, whose sum, we might
hope, is AB, the product of the sums of the two series we began with.
Taylor series and Cauchy products
Thinking about Taylor series almost immediately inspires (?) the
definition of the Cauchy product. We "know" from calculus ("know"
means that some examples were shown then!) that if
f(x)=∑j=0∞ajxj
and
g(x)=∑k=0∞bkxk
then a way (?) to organize the product is to suppose it is
F(x)=f(x)g(x), a product of functions. And we would hope that
F(x)=∑t=0∞ctxt
where now
ct=∑q=0taqbt–q.
These formulas are gotten in several ways: first, we rewrite the
product by assuming that manipulations with infinite polynomials work
exactly like those with finite polynomials. Or we can hope that a
Taylor's Theorem is at work behind the scenes, and the summation
exactly reflects the product rule for lth
derivatives. The sum is sometimes called a convolution of the
two sequences. It is unfortunate or, perhaps, interesting, that many
of these hopes are not exactly true all of the time we would hope. Oh
well. In particular,here is no clear relationship between convergence
of the factors and convergence of the Cauchy product. See the example
mentioned below.
Example in the text
A neat example in the text shows that the Cauchy product of a
convergent series (with itself!) need not
converge. Interesting. I have little to add to the account in the
textbook.
Dirichlet series and Dirichlet product
Here I defined Dirichlet series, which are rather useful in number
theory, and some other areas which don't seem to be immediately
related. These are series of the form
f(s)=∑n=1∞(an/ns).
Such series are natural in number theory and complex analysis. The
most famous example occurs when all of the an's are 1. This
is ζ(s)=∑n=1∞(1/ns),
the Riemann zeta
function. Learn more about this, and make a
milliion dollars!. Dirichlet series have a whole theory of their
own. For example, just as power series have a radius of
convergence inside which they converge absolutely, Dirichlet
series similarly (and for much the same reasons!) have an abscissa
of convergence, a line x=Constant in the complex plane. The series
converges absolutely to the right of that line and diverges to the
left of it. For ζ(s), that line is x=1. Or, as we say in the
complex analysis game, Re(s)=1.
If we have another Dirichlet series, say g(s)=∑m=1∞(bm/ms), we might consider F(s)=f(s)g(s) and think about ∑n=1∞(an/ns)·∑m=1∞(bm/ms), and maybe reassemble into another Dirichlet series, so: ∑N=1∞(cN/Ns) and this should be the same as ∑n=1∞∑m=1∞(an/ns)(bm/ms). So we might want cN/Ns to be, well, which terms of the product? To match up (1/ns)(1/ms) with 1/Ns we need nm=N.
Therefore we could define the Dirichlet product of two series (dropping the s stuff) ∑n=1∞an and ∑m=1∞bm to be the series ∑N=1∞cN where cN=∑n·m=Nanbm. Here it is divisors which are important. You can see if factoring integers and primality is interesting, such products might be more revealing than Cauchy products. One can then ask if convergence of the factors always implies convergence of the Dirichlet product. The answer, with no further hypotheses, is no. There are examples which don't have the desired behavior.
Absolute convergence and products
We will briefly discussion summation methods for products of
series. Let me start with 1 in these series, and starting with 0 would
give a similar result. So let's have two series
∑j=1∞aj
and
∑k=1∞bk
which converge and which have sums A and B respectively. Consider the
numbers ajbk which I could think of as "sitting"
each at a lattice point, NxN, of the plane. Now we will
consider
a sequence of finite subsets
{Wt}t=1∞ of NxN, with
the following properties:
1. They are nested: Wt⊂Wt+1.
2.
∪t=1∞Wt=NxN: the
union is "everything".
Examples of such Wt's come from both Cauchy and Dirichlet products. Adding up the terms which come from the Wt's exactly will correspond to the partial sums of each of these products. The easy and natural result (I love absolute convergence!) is the following.
Theorem Suppose that the series
∑j=1∞aj
and
∑k=1∞bk both converge
absolutely and have sums A and B respectively. Then the
sequence of (possibly complex!) numbers
st=∑(k,l)∈Wtajbk
converges, and its limit is AB.
Actually, even slightly more is true and follows from the preceding
result. That is, the sequence whose tth term is
∑(k,l)∈Wt|ajbk|
also converges, and its value is ≤ the product of
∑j=1∞|aj|
and
∑k=1∞|bk|. So any
method of summation of the product series of absolutely convergent
series "works" and gives the correct answer.
Proof?
We began thinking about the proof and will complete it next time.
A volunteer and his coach
Mr. Skalit, helped by the valiant Mr. Kowalick, will present problems 20, 21,
and 22 of chapter 4 in class, probably a week from Thursday.
Problems to be considered
The students in the class will consider Chapter 3: 6, 7, 10; and
Chapter 4: 4, 5, 6, 7, 11, 13, 25. Votes for the best problems will be
counted, and the 6 or maybe 7 highest vote-getters will be assigned as
homework, due on Thursday, November 26.
Thursday, October 22, 2008
So we quickly reviewed some series material after the traumatic first exam. The instructor proved the Root Test as in the text, and them proved the famous Cauchy-Hadamard Formula for the radius of convergence of a power series. This led naturally, through the investigation of the power series of what turns out to be the exponential function (Stirling approximation of factorial) to the Ratio Test, some parts of which were proved. Then we discussed the folklore that, If the Ratio Test applies, then the Root Test applies. (and they'd better give the same answer!) We proved this, even going over part of the proof which is not in the text (!).The article I mentioned in class which taught me new things about the Ratio Test is this: The mth Ratio Test: New Convergence Tests for Series and is written by Sayel A. Ali. It appears in the June-July 2008 issue of the American Mathematical Monthly.
I started to discuss ♥Why I love absolutely convergent series!♥ My first reason was that rearrangements of such series also converge, and converge to the same sum. This is nice. I didn't quite finish the proof, and I will give an interesting example next time, and a result of Riemann's which explains what happens when the series does not converge absolutely.
Thursday, October 16, 2008
There was little added value by the lecturer, who discussed the convergence of some special sequences. However, Ms. Sergel, assisted in her preparation by Ms. Slusky, gave a really nice discussion of the convergence of the very classical algorithm for sqrt(x) (a recursive sequential algorithm known in China and India for about 2500 years, and introduced in Europe only about 500 years ago). This is an algorithm which is very widely used, and the analysis of its convergence is elementary and inspired.The lecturer continued in a more pedestrian fashion. He defined infinite series. He talked about translating various sequence statements to infinite series: the Cauchy criterion, series with non-negative terms, absolute convergence, comparison, p-series via the Cauchy condensation theorem, and a brief anticipation of a version of the ratio test. More next week!
Monday, October 13, 2008
Cauchy and complete againWe rapidly reviewed the results of the Cauchy and completeness discussion last time. Amazingly, students were either apathetic or knew better than to ask for further details about any of the proofs. Sigh.
Inequalities and limits
The only Euclidean space Rk where an order topology
coicides with the usual Euclidean metric topology is R1,
that is, R, the real numbers. Some special results follow from using
the order in R. For example, we have this theorem:
Theorem Suppose {xn} and {yn} are two
real convergent sequences with limits Lx and Ly,
respectively. If for all positive integers n we know that
xn≤yn, then Lx≤Ly.
A proof of this was shown, using contradiction. If
Lx>Ly, then take
Lx–Ly=2ε is positive. Take n large
enough so that |xn–Lx|<ε and
|yn–Ly|<ε. Then
–ε<xn–Lx<ε and
–ε<yn–Ly<ε. So we know
that –ε<Lx–xn<ε (multiply
the first inequality by –1)
so that
xn–ε<Lx<xn+ε.
Similarly,
–yn–ε<–Ly<–yn+ε
so that
(xn–ε)+(–ε–yn)=(xn–yn)–2ε<Lx–Ly<(xn–yn)+2ε=(xn+ε)+(–yn+ε).
This is already a problem since
Lx–Ly=2ε.
The instructor asked if a converse to this result was true, and was greeted with scorn. Indeed, no, since 0<0 but the first 0 could be the limit of the sequence {–1/n} and the second 0 could be the limit of the sequence {1/n}. Huh. But how about this:
Theorem Suppose Lx is the limit of the sequence {xn} and Ly is the limit of the sequence {yn}. If we know that Lx<Ly, then there is a positive integer N so that if n>N, xn<yn.
The proof of this is that (taking 2ε=Ly–Lx) if |xn–Lx|<ε and |yn–Ly|<ε again, then unroll the absolute values as before, you will see that the result quoted is true.
Comment about SUBTRACT INEQUALITIES?
Notice that 1<2 and 1<5 but 1–1<2–5 means 0<–3 which is
certainly false! Generally, you cannot subtract
inequalities and be sure that the result is correct.
More subtle results occur, but we need a few more definitions.
∞ and –∞
Suppose {xn} is a real sequence which has the following
property: for all M∈R, there is a positive integer NM
so that if n≥ NM, then xn>M. Then we will
say that limn→∞xn=∞.
If we changed "xn>M" in what's above to
"xn<M" then we will write
limn→∞xn=–∞.
lim sup and lim inf
Suppose {xn} is a real sequence. Define S to be the set
of all subsequential limits of this sequence. This is a collection of
numbers in R*, which I guess is
R∪{∞}∪{–∞}, and we will think of
R* as an ordered set with the (more or less) obvious
ordering. I asked if we could find examples of sequences with
S=∅ and S=R*. Well ...
NO!
How to think about this: a sort of bisection method. Now consider
[–∞,∞] and split it into two parts,
[–∞,0]\cup;[0,∞]. Look at N: let's call an integer n
left if xn∈[–∞,0] and call it
right. Hey, if it is both left and right call it both. In any
case, N is now the union of a set of left and right sets, so one of
them has infinitely many elements. Let's suppose it is the right
one. Then consider [0,∞]=[0,1]\cup;[1,∞]. Hey: left/right
again. If left triumphs (has infinitely many!) then split up [0,1]
into [0,1/2]\cup[1/2,1] ETC.. If right wins, then
split [1,∞] into [1,2]\cup[2,∞] ETC.
Eventually we will get a finite limit or a subsequence which is pushed
to infinity. In either case, S≠∞. Whew! So there must be at
least one subsequential limit.
YES!
There is a sequence with S=R*. Take {xn}
to be any "enumeration" of the rationals: so this refers to a function
f:N→R which is 1–1 and whose range is Q. Then S is
R*. Why? Because in any real interval of postive
length there are infinitely many rationals, so given any such
interval and given any integer J, there is always j>J with
xj inside the designated interval. It is not difficult to
use this observation to verify that S is indeed R*.
Question Is there a sequence which has S=R? You think about this, please.
lim sup and lim inf
Given {xn} consider S, the set of all subsequential
limits. Then lim sup is the sup of S (considered as a subset of
R*) and lim inf is the inf of S.
Some special sequences
The sentence "And now we begin." ends the novel, "Portnoy's
Complaint", by Philip Roth. This sentiment could be echoed by many
analysts at this point in the course. We now start looking at some
concrete examples of sequences and then series.
The examples
We saw as a consequence of our study of the Archimedean property, that
- {1/n} converges and its limit is 0.
- If |x|<1, then {xn} converges and its limit is 0.
The lecturer falls, and no student picks him up!
We tried to consider the sequence {a1/n} for a>0. This
sequence does converge, and its limit is 1. After some
confusion regarding the Bernoulli inequality, little progress was made
towards the verification of the convergence and limit claim. Sigh. Deferred
to Thursday's class, I suppose!
Thursday, October 9, 2008
We resumed with subsequences. The lecturer stated a theorem which Ms. Slusky observed was trivial. The lecturer was embarassed.
Writing in progress!
He continued with a clumsy proof that the set of subsequential limit
points of a sequence in a metric space is always a closed set. There
is a tiny bit of diagonalization needed in this proof. The lecturer
obfuscated this as much as he illuminated it.
Cauchy sequences
A major discussion was started with the definition of Cauchy sequence, a very important concept in
analysis and, indeed, in all of mathematics. Given {xn} in
the metric space (X,d), we call this sequence Cauchy if given
any ε>0, there is a positive integer Nε
so that if n and m are integers ≥Nε, then
|xn–xm|<ε.
Cauchy seuqences are candidates for convergent sequences. They are
defined, though, only with "internal", self-referencing criteria, so
that knowing such a sequence must converge (as it must, under
certain circumstances!) is neat. In R and Rn Cauchy
sequences must converge. The convergence of many algorithms is
guaranteed using the Cauchy criterion (that is, by proving that the
sequences produced using the algorithm are Cauchy). We looked at some
examples in R and some conditions in R.
Example If {xn} is a real sequence and we know that
|xn–xn+1|<1/n, then such a sequence need not
converge and such a sequence need not be Cauchy. Here the example
(reaching for our knowledge of calc 1) is
xn=∑j=1n1/j, the sequence of
partial sums of the harmonic series. This sequence does not converge
(hey: x2n≥1+[(n–1)/2] with an easy argument,
so the sequence is not even bounded). Why is this sequence not
a Cauchy sequence? Well, we need to compare xn and
xm when n and m are both "free" and large. If we make n
large with m>n, the triangle inequality will only provide a bound
like this:
|xn–xm|≤|xn–xn+1|+...+|xm–1–xm|<∑j=nm1/j,
and that sum is not bounded.
Example The metric space Q has Cauchy sequences which do not
converge. Any convergent sequence in a metric space is Cauchy (we'll
state that formally in a few microseconds). Now take a rational
sequence which converges to sqrt(2) in R. It is Cauchy in R, and hence
in Q (the metric is the same). But it can't converge in Q since there
is nothing for it to converge to. (If it converge to w in Q, the same
inequalities would make it converge to w in R. But then since the
limits are unique, sqrt(2) would be in Q!)
Example Look at (0,1), the open unit interval in R. The
sequence {1/n} is in (0,1). In R it converges to 0, and thus it must
be Cauchy, but it can't converge to anything in (0,1) since otherwise
it would converge to w>0. But the sequence converges to 0 in R, so
(just as before) this is impossible.
A convergent sequence is Cauchy
Use a triangle inequality argument.
If a subsequence of a Cauchy sequence converges, then the original
sequence converges.
Use a triangle inequality argument.
A Cauchy sequence is bounded
Indeed, take ε=1. Then the whole "infinite tail" of the
sequence after the Nε term is within distance 1 of
xNε. Now take a ball big enough to
enclose also the finitely many other points left out.
The Direichlet problem, a historical digression
This is a problem in partial differential equations which originated
in classical mathematical physics. Attempts to solve this problem in
the late 19th centuries led to recognition that "closed and
bounded" is not enough to guarantee convergence in many natural
"function spaces", specifically function spaces which were used to
analyze the Dirichlet problem. This failure or, rather, perhaps, perceived deficiency led
to recognition of the importance of compactness, and to the invention
of the notions and methods that we are currently discussing.
We went on ...
The lecturer really deliberately tried to investigate the connection
between Cauchy and compactness in a rather diffuse non-linear
way. This is often how new mathematics develops!. The sequence
of ideas went like this:
- Suppose {xn} is a candidate Cauchy sequence in a metric space. I would like to understand why it should (or should not!) converge. So I said that convergence is actually not affected by any "initial segment" of the sequence. It is a property of the collection of "infinite tails". So let KN be the set {xN,xN+1,xN+2,...}. If the sequence converges to some limit L, then L might not be in KN -- that would be too much to hope for. But certainly if a sequence has a limit, say L, then the limit will be in the closure of any tail of the sequence. Why? Because any ε ball around the limit will have infinitely many terms of the sequence. If these terms are equal to L, then the limit is in KN. If none of the terms are L, then indeed the limit is inside the closure of the tail.
- Let's call LN the closure of the tail,
KN. Well what do we know? Certainly, these sets are
nested: Ln+1⊂Ln. And how about
their sizes? I will measure size with diameter, the sup of the
distance between pairs of points of the subsets involved. There are
two lemmas:
- Given ε>0, there is N so that diam(Kn)<ε for n≥N. This is true because of the definition of Cauchy.
- If S is a subset of a metric space, the diameter of the closure of S is the same as the diameter of S. This is true with a mostly standard sup argument. I hinted at this in class, and it is in the text.
- Now consider the intersection of the Ln's. Suppose that
this intersection is not empty. Then the following is true:
- The intersection has at most 1 point. Because if it has two distinct points, these points have a positive distance between them. We can choose ε>0 smaller than that distance. Then for large enough n (preceding remark!) the Ln will not be able to have both of the points in it.
- If the intersection is non-empty, the unique point (by the previous observation) in it is the limit of the sequence. This is because given ε>0, we can take n large enough so that the diameter of Ln and Kn is less than ε. But then the points in Kn, an infinite tail of the sequence, are all within ε of the limit, since L is in all of the Ln's.
- Why should the intersection of the Ln's not be empty?
In R we could consider Ln=[n,∞), a nested collection
of closed sets with empty intersection. Or we could consider (0,1/n),
a nested collection of open sets with empty intersection and getting
smaller. But these are the same examples we used before when we were
considering compactness. In fact, we need to use the fact that in a
compact set, the nested intersection property holds. So if all of the
Ln's are in a compact set, the intersection of all of them
is non-empty. We proved that. Therefore,
Theorem Any Cauchy sequence in a compact metric space converges. (A direct result of the finite intersection property.)
Theorem Any Cauchy sequence in Rk converges. (Because any such sequence is bounded, and is therefore inside a very big (maybe!) compact set, and therefore can be consider to be in a compact set, and we are done.)
The textbook has a much more linearly ordered and careful presentation.
Monday, October 6, 2008
We gave some examples of convergent and divergent sequences. I mentioned the fact that writing "limn→∞xn=x" already seems to incorporate the idea (a theorem, darn it!) that if {xn} converges to both w and v, then w=v.We then proved (as in the text) that sums of complex-valued convergent sequences are convergent to the sums of the respected limits. Also, if a sequence converges to a non-zero complex number, then "eventually" the sequence is non-zero, and that the sequence obtained by taking reciprocals of the elements of that tail of the original sequence converges, and the limit is the reciprocal of the limit of the original sequence. These techniques are basic and must be part of all mathematicians' subconscious.
I looked at the product of two metric spaces. We put a metric on this
product, defined in a way very similar to the Euclidean metric in
R2 from d(x,y)=|x–y| in R1. I observed, very
briefly, that metrics giving the same topology on the cartesian
product are the analogues of the L1 and L2 and
L∞ metrics mentioned in the last homework
assignment. Then we saw that a sequence in the product converged if
and only if the components in each factor (X and Y, respectively)
converges. The same is true in any finite product, but with infinitely
many factors things get much more complicated. (The last part of the
second problem of the Entrance Exam deals with similar obstacles.).The
metrics which we considered here (L1 and L2 and
L∞) and which give, in finite dimensions, the same
topologies and the same notion of sequence convergence, all
turn out to be different in infinite dimensions. This is either
distressing and bewildering, or wonderfully enriching!
We will use the observations about products of metric spaces almost
always with Rk (where k is a positive integer).
We then moved on to subsequences. I tried to be very careful about defining a subsequence, and admitted my occasional confusion between a sequence (a mapping from the ordered set N to X) and the image of the mapping, a subset of X. Here is a weird example.
Example
Since Q, the rationals, are countable, there is a bijection
F:N→Q. Fix any such bijection for this discussion. Now fix
any x∈R. I claim there is a subsequence G:N→Q of F so
that G converges to x. Why? Well, we must write G as FοI where
I:N→N is strictly increasing. I will create I inductively as
follows.
- What is I(1)? Consider (x,x+1), an interval of positive length. I(1) is a positive integer n so that F(n) is in (x,x+1). This is true since the rationals are dense.
- Now we specify I(n) for n>1 inductively. We assume that I(1),I(2),...,I(n–1) have already been defined, with I(1)<I(2)<...<I(n–1). Consider the interval (x,x+(1/n)). There are infinitely many rationals in this interval, else we can easily get a contradiction to the density of the rationals (please: you can and should describe how to get in that case an interval of positive length with no rationals). Since there are infinitely many rationals, there will be a rational q with F(j)=q and j larger than I(n–1). Let I(n) be equal to that j. This inductively defines a subsequence, and clearly, if m≥N, |G(m)–x|<1/n. So the subsequence converges to x.
So the "structure" of subsequences can be quite complicated. I don't think this should be too surprising since there are, after all, uncountably many subsequences.
We stated a result something like this:
Theorem Suppose {xn} is a sequence in a metric
space. The following are equivalent:
- {xn} converges to x.
- All subsequences of {xn} converge to x.
- All subsequences of {xn} converge, and they all must converge to the same x.
Thursday, October 2, 2008
Professor Nussbaum was the guest lecturer and did an excellent job. His definition of connected was equivalent to the textbook's definition. For him, X is connected if it can be written as the union of two disjoint non-empty open sets U and V. That the sets should be non-empty is avioding the silly (?) description of X as the disjoint union of X and ∅, of course. If U and V are given, then since each is the complement of the other, both U and V are closed, and the closure of V, say, is closure(V). So we have written X as needed in Rudin's definition of a separation.He began chapter 3, defining convergence of sequences in metric spaces. He showed that a convergent sequence was bounded, etc. He proved that the product of convergent sequences of complex numbers converged, and its limit was the product of the limits of the factor sequences.
Monday, September 29, 2008
Compactness of k-cells, a proof using bisectionThis is the method of bisection. The proof was more or less as in the text, except that the instructor, to avoid being confused, drew a picture for k=2 to guide his statements. The reason for doing everything in the last lecture or so is the following fantastic theorem.
The Heine-Borel Theorem
If E is a subset of Rk, then the following statements are
equivalent.
- E is closed and bounded.
- E is compact.
- Every infinite subset of E has a limit point in E.
A counterexample (not really!)
This is a rather simple but still instructive example.
Suppose X is any set, and d is the discrete metric. That is,
d(x,y) is 1 when x≠y and is 0 when x=y. Every subset of X is an
open set always (and every subset is a closed set!). The compact
subsets of X are exactly the finite subsets. The diameter of every
subset of X is at most 1. So if X is infinite, there are certainly
many closed and bounded subsets which are not compact. So the H-B
theorem is not true in all metric spaces.
I note that most "infinite-dimensional" situations which arise in analysis (and, indeed, even in certain areas of algebra) naturally many subsets do not satisfy the H-B Theorem. Certainly compactness implies closed and bounded in a metric space, and several textbook homework problems show that the third condition implies compactness in any metric space. But generally the friendly hypothesis of "closed and bounded" will not imply compactness.
Proof of H-B
This was very much like what's in the textbook, with only minor
variations introduced by the instructor to ... uhhhh ... challenge the
students. Yeah, that's right: challenge the students.
Perfect sets are uncountable
Thanks to Ms. Pritsker and Ms. Hood. Here is her writeup.
The most wonderful perfect set, the Cantor set
I tried to analyzed this set informally. It is an uncountble set. The
intervals taken out of it from [0,1] have total length equal to
1, so maybe it should have total length 0. The points in the Cantor
set are those whose ternary (base 3) expansions have no 1's. The
Cantor set and variations of it are used as the foundation for many
disturbing and unintuitive examples in analysis and topology.
It would be nice to tell you that the Cantor set and its relatives are unnatural, etc., except that certain dynamical systems which closely model physical and biological systems have certain types of behavior closely tied to the Cantor set!
Homework due on Thursday, October 9
The third homework assignment is due a
week from Thursday.
Out of town
I will be away from Thursday, October 2, to Sunday, October 5.
Thursday, September 25, 2008
The 411 build-a-vocabulary projectToday's word is exegesis. One definition is "Analyzing passages from a document - often the Bible - to understand what it meant to its author and others in the author's culture."
Compact
Define of open cover and compact using a finite
subcover.
Compactness turns out to be of fundamental importance in many numerical computations. This is not at all clear from the definition and discussion we're about to do. We are beginning at the tail end of a century of struggle with how to handle compactness and related notions, and the "perfection" shown is a bit difficult for a novice to grasp and certainly to understand in a meaningful way.
Examples
We verified from the definition that
[0,1] is compact.
Here's how Suppose {Gα} is an open cover of
[0,1]. Let S={s∈[0,1] : [0,s] has a finite subcover by elements
of {Gα} }. Then:
- S≠∅ since 0∈S because 0 is in one of the Gα, and that one open set itself is a finite subcover of [0,1].
- S is bounded above, since S⊂[0,1] shows that 1 is an upper bound.
- If w=sup S, then w∈S. This is true because w is in some Gα, and for some ε>0, (w–ε,w+&epsilon)⊂Gα. If w=sup S, there must be an element of S in (w–ε,w+&epsilon) or else w is not a least upper bound. Let v be that element. Then [0,v] has a finite subcover, and so by including Gα in the subcover also, [0,w] has a finite subcover. So w∈S,
- The sup of S must be 1. Just as in the previous section, we see if w=sup S<1, take Gα, and for some ε>0 with (w–ε,w+&epsilon)⊂Gα. If w<1, then including this Gα with the cover tells us that [0,max(1,w+(1/2)ε)] also has a finite cover, which contradicts that w is an upper bound of S.

So here are a bunch of rainclouds, maybe infinitely many, raining on the unit interval. Compactness declares that only a finite number of them are needed for each point of [0,1] to be rained on. (This is a metaphor, darn it!)
We verified from the definition that
(0,1) is not compact.
And why this is true As Mr. Baldwin suggested, cover
(0,1) by (1/n,1) for each positive integer n. Then the Archimedean
property implies this is an open cover (every positive number is
greater than some 1/n) and the union of every finite subcover
is exactly its "highest" element, and none of the (1/n,1)'s is equal
to (0,1).
Balls are enough to check compactness
We need only use open balls instead of open sets in the covers we use
to test for compactness.
2.33
Suppose K⊂Y⊂X. Then K is compact relative to X if and only if
K is compact relative to Y.
I think we used balls here, which might be slightly nicer than the
proof of the text.
Suppose X=R2 and Y=R1 (considered as a subset of
R2 with y∈Y ↔ (y,0)∈X) and with both sets
having topologies determined by the usual metric. Notice that the
metric in R2 defined by sqrt((a1–a2)2+(b1–b2)2) is just |a1–a2| when we
consider points on the horizontal axis. K should be a subset of Y.
| Now suppose we have a cover of K by open balls in Y and
we know that K is compact in X. The picture to the right is an effort
to illustrate the situation. I drew a collection of green intervals. I
had to lift them up a little bit ("up" means vertical motion) to show
them and not have them overlay and conceal K. If we use the same
centers and the same radiuses and create open balls in X, then, since
the green intervals cover K, the resulting magenta discs will also
cover K. This is because the intersection of each magenta disc exactly
equals the green interval which it specified. If we know that K is
compact in X, then a finite union of the magenta discs will have K as
a subset. The related green intervals will have K as a subset, also,
since a point in K is in a magenta disc exactly when it is in the
related green interval. We have proved that if K is X compact then it is Y compact. |
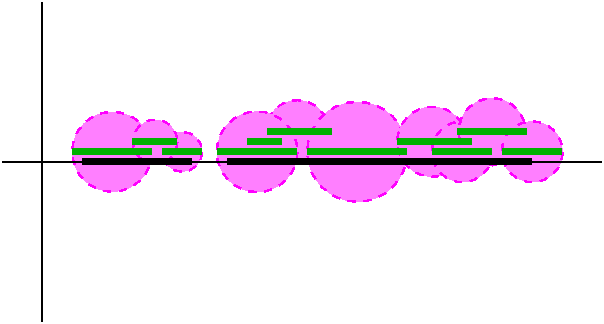
|
| Now suppose we have a cover of K by open balls in X and
we know that K is compact in Y. So K is in a union of magenta
discs. Take one such disc. Its intersection with Y is not
necessarily an open ball in Y. It must be an open subset of Y,
because each point in the disc is an interior point (we proved that
open balls are open!). Therefore each point in the intersection of a
magenta disc with Y is contained in a green interval -- that is, an
open disc in Y with center in Y and positive radius. This may
be a big collection of green sets, but I don't care: the collection of
all of these green intervals, for all of the magenta discs, is an open
cover of K in Y. Since K is compact in Y, there's a finite subcover by
the green intervals. Each green interval comes from one of the magenta
discs. So for each green interval in the finite subcover, take the
associated magenta disc. The resulting collection of magenta discs is
a finite subcover in X of K. We have proved that if K is X compact then it is Y compact. |
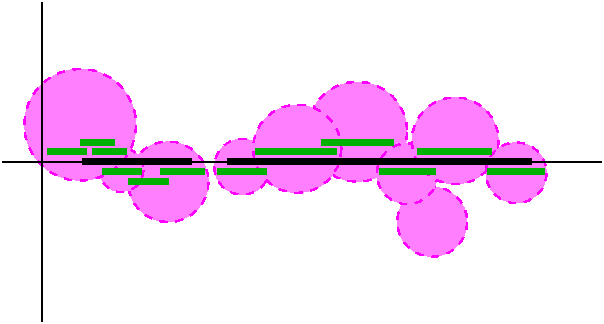
|
2.34
Compact subsets of metric spaces are closed.
Proof as in the text. This is a brief and clever proof and the ideas
are used elsewhere.
2.34
Closed subsets of compact sets are compact.
Proof as in the text.
Corollary
If F is closed and K is compact, then F∩K is compact.
2.36
If {Kα} is a collection of compact subsets of a
metric space X such that the intersection of every finite
subcollection of {Kα} is nonempty, then
∩Kα is nonempty.
What's written in the hypothesis is called the Finite Intersection
Property. One of my colleagues remarked that this result is no
more than DeMorgan's Laws. I have always found this confusing. So,
with the help of many charitable students, I tried to state the
compactness definition carefully and logically. I then wrote the
contrapositive. I then used DeMorgan's Laws to translate the
statements we obtained. If we consider everything as a subset of one
of the given Kα's, we proved the theorem.
This is the
proof in the text, where it is given not so histrionically.
Bonus vocabulary word: histrionic Of, or relating to actors or
acting; Excessively dramatic or emotional.
Corollary
If {Kn} is a sequence of nonempty compact sets such that
Kn⊃Kn+1 (n=1,2,3,...), then
∩1∞Kn is not empty.
Proof as in the text. People sometimes say "the Kn's are
nested" instead of "Kn⊃Kn+1".
2.37
If E is an infinite subset of a compact set K, then R has a limit
point in K.
Proof as in the text.
2.38
If {In} is a sequence of intervals in R1 such
that In⊃In+1 (n=1,2,3,...) then
∩1∞In is not empty.
Useful and relevant examples
- Suppose In is (0,1/n). Then these intervals are non-empty and nested, and their intersection is ∅. But these intervals are open.
- Suppose In is [n,∞). Then these intervals are non-empty and nested and closed, but unbounded. Their intersection is ∅. But these intervals are unbounded.
slightly restated 2.38
Make the intervals both closed and bounded. Then
the result is true. This phrase has great "resonance" historically.
If In=[an,bn], then
an<bm when n and m are positive integers. If
α is sup{an :n∈N} and if β is
inf{bm: m∈N} then (not totally easy exercise)
α<β, and then [α,β] is
∩1∞In, and certainly the
interval is not empty.
Proof as in the text.
2.39
Let k be a positive integer. If {In} os a sequence of
k-cells such that In⊃In+1 (n=1,2,3,...) then
∩1∞In is not empty.
We briefly discussed what "k-cells" were.

Here are pictures of 1- and 2- and 3-cells. A k-cell is the Cartesian
product in Rk of k closed and bounded intervals, one in
each factor.
The proof as in the text.
Monday, September 22, 2008
A metric space has a topology, but not all topologies come from
metrics. By "come from" I mean the following process: given a metric, we can
define open balls. Given open balls, we can define open sets. The
collection of open sets is a topology. One can ask if, given a
topology, is there a metric which manufactures this topology using
this process. (Thanks to Mr. Baldwin for asking me to clarify what I
meant by the informal phrase, "come from" in asking whether all
topologies come from metrics.)
This question is more suitably part of Math 441, but we briefly discussed certain desirable (?) properties possessed by metric spaces but not by "random" topological spaces. More generally in the history of topology, a great deal of effort went into discovering which topological spaces occured as a result of a metrics. This is called metrizability and the theorems are intricate.
Uniqueness of limits/Hausdorff
If a topology comes from a metric, then the topology has the following
property, which may initially seem rather strange.
Property H Take two distinct points x and y of the space
X. Then there are open sets U and V of X with x∈U and y∈V
with U∩V=∅.
To see why this is true in a metric space, let
q=d(x,y) which must be a positive number since x and y are
different. Then put r=(1/2)q, and consider Nr(x) and
Nr(y). If z is in both of those sets, then d(z,x)<r and
d(z,y)<r, so (triangle inequality and symmetry of d)
q=d(x,y)≤d(z,x)+d(z,y)<(1/2)q+(1/2)q=q which is a contradiction
since q is positive.
A silly example of a topology which does not have Property H is
the following: take X to be a two-element set, say
{♣,♦}. The topology on X (which must a set of subsets of
X, don't sink into the sea of abstraction here) to consider is {∅,{♣,♦}}. This
sure is a topology (called the indiscrete topology, the
smallest topology -- the largest topology is called the discrete
topology) and it does not have "enough" open sets to separate the
two points, ♣ and ♦.
Comment The number of
topologies on a finite set is interesting and there's no known
exact pattern. Note, oh combinatorists, that most (!!) of them do not
have Property H above.
A topology which has Property H is called Hausdorff (the points can be "housed off" from each other [sorry]). This property is already evident in calculus, because we tell people there the following result: if {xn} is a sequence and if limn&rarrow;∞xn=A and limn&rarrow;∞xn=B, then A=B. This "uniqueness of limits" property is exactly a consequence of Property H or Hausdorffness. There are important examples of non-Hausdorff topological spaces which seem less "artificial" than what I gave, but their descriptions are somewhat complicated.
Countable sequence of open sets
A topology which comes from a metric has the following property:
Sequence of neighborhoods
If x∈X, then there is a
sequence of open sets, {Un} so that if V is open and
x∈V, there must be a positive integer N so that
x∈UN⊂V. Actually, we can even ask that these sets
be "nested", so that Un+1⊂Un for all n.
Proof A proof is very brief. If d is the metric, take
Un to be the ball of radius 1/n centered at x, that is,
Un=N1/n(x). If V is as described, there is some
r>0 with Nr(a)⊂V. Then the Archimedean property
guarantees the existence of N with 0<1/N<r, so that
UN⊂V.
This idea will be used again and again in this course. It plays an important part of the "a implies c" proof and you should look at that now if you already haven't. We will use the idea to "create" suitable sequences. But let me show you a somewhat intricate example of a topological space which does not satisfy the preceding result.
R∞
As a set, R∞ is "just" the collection of all real
sequences. So if x∈R∞, then
x=(x1,x2,...,xn,...) with all of the
xn's elements of r. For the purposes of this paragraph,
I'll call such an x positive exactly when all of the
xn's are positive real numbers. I want to define the box
topology on R∞. I will first begin by defining
box neighborhoods.
Suppose x=(x1,x2,...,xn,...) is a
point in R∞ and
ε=<ε1,ε2,...,εn,...)
is a positive element of R∞. Then I will tell you
what is in the subset Mε(x) of
R∞. A point
y=(y1,y2,...,yn,...) of
R∞ is in Mε(x) if and only if, for
all positive integers n,
|xn–yn|<εn. The sets
Mε(x) play a role similar to what the balls
Nr(x) do in the case of metric spaces, but there's no
metric visible (indeed, there is no metric possible, as we will
see!). Now I will tell you what an open set. A subset W of
R∞ will be open in the box topology if:
for all x∈W, there is a positive ε in R∞
so that Mε(x)⊂W.
We should check that the rules for a topology are satisfied. If you
wish to do this, you should begin by verifying that
Mε(x) is itself open (analogous to verifying that
an open ball is open). This is not too difficult, and, indeed, nost of
the other verifications are easy. One thing needs to be said, I
think. If
Mεa(x) and
Mεb(x) are two of the defining
neighborhoods, and if we put
εc;=(min(εa1,εb1),min(εa2,εb2),...,min(εan,εbn),...)
(take minimums in each coordinate) then
M&epsilon3(x)⊂Mεa(x)∩Mεb(x). This
result is needed to prove that intersections of box open sets are box
open.
Now suppose that x∈R∞. What if there were a qualifying sequence of box open sets {Un} behaving nicely as in the Sequence of neighborhoods proposition above? Then there must be (definition of box open) a sequence of positive εn's so that x∈M&epsilonn(x)⊂Un. I will create a specific Mη(x) which is not contained in any of the M&epsilonn(x)'s.
Let me begin by looking at a specific example, because that will help us understand the general case. Take Un to be M(1/n,1/n,...,1/n,...)(0). So this is a neighborhood of 0 whose "polyradius" is 1/n in each coordinate or direction. Certainly, there is no point other than 0 in all of the Un's, so they seem to "shrink down" to 0. As a response to this choice of a sequence of Un's, I ask you to consider V=M(1,1/4,...,1/n2,...)(0). I claim that none of the Un's can be included inside V. Why? Well, let's look at a point pn in Un. Define pn to be (2/(3n),2/(3n),...,2/(3n),...) so it is 2/(3n) in each coordinate. This is certainly inside Un since 2/(3n)<1/n. But it is not in V, because 1/n2 is eventually less than 2/(3n).
Now let's try something similar in general. You "challenge" me with a
list of Mεn(0)'s.
My Mη(0) will be constructed so that its sequence of
coordinates →0 faster (eventually!) than any of the
sequences of coordinates of the εn's. Here is one
possible recipe:
Take
ηj=(2/3)min(1/j,ε1j,ε2j,...,εjj)
Then what do I know? I know that &etaj is much smaller than
the jth coordinates of ε1,
ε2, ..., εj. The element of
R∞ defined by two-thirds of &epsilonn is
in Mεn(0), surely (I just mean, multiply
the components of &epsilonn each by 2/3). But it is
not in V. Why? Because for j>n, ηj is less
than (2/3)εnj. This "tail" restriction
prevents the element of Un from being in V.
What's going on?
Given a sequence of sequences of positive numbers, we have
created a sequence whose limit is 0 and which approaches 0 eventually
faster than any of the sequences. The "eventually" is that it
is smaller than the given sequences at a variable starting place, of
course. This is again the diagonal process applied in a more
complicated way.
Please note that in class I used a much simpler prescription to create η which won't necessarily prove what is needed. I am sorry. I also owe emphatic thanks to Ms. Slusky whose persistant inquiries and messages made me think a bit more about this. It is more subtle than what I hurriedly did in class.
First countable
A topology which does satisfy the Sequence of neighborhoods
proposition is called first countable. I showed that a topology
obtained from a metric space is first countable, and gave an example
of a topological space which is not first countable. There are simpler
examples but the example given is also Hausdorff, and the underlying
set, R∞ is neither artificial nor unimportant, but
arises naturally in probabilistic reasoning (select a random sequence
of real numbers). The box topology is not used in probability because
it has other defects besides lack of first countability. In a first
countable space, sequential reasoning is adequate to determine what is
and is not an open set.
Metric spaces are Hausdorff and first countable, and I likely never refer to these terms officially again in this course, but I will use the properties they define frequently.
More definitions
Now for the actual progress of the course. We return to metric spaces,
Interior point; interior of a set
We defined interior point and the interior of a set. We prove that the
interior of a set is equal to the union of all the open sets which are
a subset of the set. We investigated some examples.
Closed set
A closed set is the complement of an open set. Some sets are neither
open nor closed. We investigated some examples. The closure of a set
is the intersection of the closed sets containing the set. We
characterized this using the idea of limit points, and considered
(rapidly!) some examples. A closed set is one which contains its limit
points.
Perfect set
A perfect set is a set which is its own limit points. Ms. Pritsker,
with the help of Ms. Hood, volunteered to prove, some time, that a
perfect set in a metric space is uncountable. Thanks to them in
advance.
Dense
I did not define "dense" and will need to begin next time with that
definition. Sigh.
Thursday, September 18, 2008
A few more remarks about cardinalityI reviewed what we "knew" so far. Perhaps the most interesting additional remark I made concerned the Schroeder-Bernstein Theorem which says, roughly, if }A|≤|B| and |B|≤|A|, then A~B. More precisely, it states that if there is an injection (1-1 mapping) from A and B and if there is an injection (1-1 mapping) from B to A, then A~B (A and B have a bijection, so they are "the same size"). I will not prove this here -- the proof is "elementary" but it is not part of Math 411. If you are curious, take a course or read.
The real numbers are uncountable
Here is what I said. This is, more or less, Cantor's second (!)
proof of this assertion (more later). Suppose R were a countable
set. Then, since subsets of countable sets are countable, the interval
[0,1] would be countable. Now supponse [0,1]~N, the positive
integers. Then there would be an "enumeration", that is, a way of
listing the elements of [0,1] according to their image under a
hypothetical bijection with N. So let us enumerate the elements
of [0,1], listing each one according to its decimal expansion address.
First element <---> .a11a12a13a14... Second element <---> .a21a22a23a24... Third element <---> .a31a32a33a34... Fourth element <---> .a41a42a43a44... ....Now we define a number b in [0,1] by giving its decimal expansion address:
b=.b1b2b3b4...
where bj=7 if ajj is not 7 and ajj=4 if j=1. This is silly but effective, really. Notice that b can't be equal to any of the "elements" listed in the enumeration because the decimal expansion address is different. So we are done.
Criticism of this Cantorial proof
Well, the problem is that the decimal "address" is not unique. What do
I mean? By analogy, if we talked about a building at the intersection
of Fourth Avenue and Avenue A, it is logically possible that the
building would have two distinct addresses. It could be called,
say, 47 Avenue A and 222 Fourth Avenue. Certainly that occurs with
decimals. For example, I know (?) that .379999999...(9's repeating) is
a decimal address for a number which also has the decimal adress
.38000000...(0's repeating). Well, hw many numbers have that problem?
The problems are those numbers with decimal expansion "ending" in an
infinite string of 9's. Well, golly, how many such problematic numbers
are there? For any finite string of integers,
.c1c2c3...cL I could end
with 9's repeated or subtract 1 fron cL. (This is not
exactly correct, since cN could be 0 but I'm getting
tired.) So this countable set of reals has maybe two addresses. Throw
them out and apply the Cantor proof (the "Cantor diagonal
process"). The result will be an unenumerated real number. So the
proof works. Let's follow Professor Rudin's text, though. This will
mean using the diagonal process you have already seen at least two
more times, and maybe even more. This is not a bad thing, since the
idea is really inspired, first-class, etc.
Really, a set which is not countable
Let's consider the sequences whose values are 0 or 1. That is, such a
sequence is a function, f:N (the positive integers)→{0,1}. Or, if
you are a traditionalist, it is {an}n in N where
the an's are 0 or 1. What if this set (let us call it,
temporarily, S) is countable? We enumerate the sequences in S. That
is, S consists of f1, f2, f3,
f4, ... and we "diagonalize" to create a sequence which is
not enumerated. So g(n) is 1-fn(n). I wrote this equation
and knew this was sort of being exhibitionistic -- I just wanted to
show you I could. Sign. What the heck is g? At the positive
integer n, is is 1-fn(n). So (work it out, I have, darn
it!) this "switches" the values. That is, if fn(n) is 1,
then g(n) is 0, and if fn(n) is 0, g(n) is 1. So g
can't be any function already counted. The set S cannot be
enumerated, and it is not countable.
Hash [huh?]
Let me now try to create an injective function I:S→R. I
will be wrong, but, I will try! First, as preface, I will assert the
following wonderful fact:
If n is a positive integer and a is non-negative, then
∑j=1nrj=(r–rn+1)/(1–r).
Now you may know this as the partial sum of a geometric series, but I
know it in Math 411 as a fact which can be confirmed with mathematical
induction if r≠1. Well, if I know this fact, then (with a≥0 and
0≤r<1) any such sum is positive and certainly less than
r/(1–r). for example, if r=1/2, the sums will all be less than 1.
Let's try the following to create an f. If A={an} is a sequence of 0's and 1's, define I(A)=sup{∑n=1Nan/2n : N is a positive integer}.
There's a bunch of things to check. First, does the set indicated
above have an upper bound? The key observation is that
∑n=1Nan/2n≤∑n=1N1/2n≤1.
So the set involved in I(A)'s definition is bounded above, and
therefore it has a sup. Unfortunately, several students pointed out
that the Emperor's clothing is indeed lacking. I is not 1-1. It
is, after all, just the sequence {an} encoded as the binary
expansion of a number. And just as decimals have problems, so do these
expansions. For example, the sequence {1,0,0,0,...(all 0's)} gets
mapped to a set whose only element is 1/2. But the sequence
{0,1,1,1,...(all 1's)}: well, we need the sup of
∑n=2N1/2n={1/2}–{1/2N).
Since we proved that 2N is unbounded, these sums also have
sup equal to 1/2. The mapping I is not injective.
How to fix it
Computer science sometimes calls functions like I by the name, hash
function (this is part of the special Math 411 Vocabulary Building
Project). The hash function classifies elements of a set. Here the set
to be "classified" are the collection of 0-1 sequences, and we will
classify them by real numbers in [0,1]. When its values of the hash
function are the same for different inputs, the result is called a
collision. Can we redefine I to avoid collisions?
One suggestion (from Mr. Kowalik?) was to replace 2 by 3 in the definition of I. This will work. In fact, we will use something similar next week in a slightly different context. I wanted to use a weirder idea, because it leads to a wonderful fact mentioned later. So my "suggestion" was to replace 2n by 2n!. This means that we are filing the sequences into bins (?) of [0,1] which have widths which shrink much more quickly. Let's now consider two different sequences, say A={an} and B={bn}. Let's assume that N is the first time that they disagree. So an=bn for n<N and, to be specific, aN=0 and bN=1. I claim that I, as modified with n! instead of n for the exponent, will have I(A)<I(B): they won't be equal. If I verify this, then I is injective, and, since S is uncountable, we will have verified that R is uncountable. Wow!
Let's make an I(A) as large as possible and an I(B) as small as
possible, and compare them. The initial segments appearing in the sum
are the same, and if I show what follows, then we're done:
∑n=N+1∞1/2n!<1/2N!.
Now consider the sum. Its first term is
1/2(N+1)!=1/(2N!)N+1 (repeated
exponents are subtle!). What about the ratio between successive terms?
Well, the factorials make what's written above not a geometric
series. So let me overestimate what is above by a geometric series
with initial term 1/(2N!)N+1 and ratio between
successive terms equal to 2(N+2)!–(N+1)! (this is just the
ratio between the first and second terms -- all the other ratios are
much less because the exponents are even larger). The exponent is at
least 4. So the series given above is less than a geometric series
whose first term is 1/2(N+1)! and whose ratio is 1/4. The
sum of that series is [1/(2(N+1)!]/(1–{1/4}) which is
1/(3·2(N+1)!–2). Now let me ask about this
inequality:
2N!<3·(2(N+1)!–2)
When N=1, this is
2<3·20 which is true.
When N=2, this is
22<3·24 or 4<48 which is true.
When N=3, this is
26<3·222 which is very true (heh, heh:
64<125,582,912: silly).
The desired inequality is always true, and can be "left to the
student" (factorials grow very fast!). So we are done, and we
know the reals are not countable. We will see other proofs of
this fact, but now let's use it.
Transcendentals ...
Mr. Ratner discussed problems 2 and 3 in chapter 2. He defined
algebraic numbers and showed that they were countable, and therefore
concluded that the transcendentals, the "other" real numbers, were
uncountable. Here is his writeup.
Note For the algebraists among you, please realize that the
algebraic numbers are a field. This is not totally trivial, but it is
algebra, so I can't prove it, and I don't need to in Math 411.
Opinion and history
I said as I believe, that this sequence of silly trivial observations
is truly remarkable. One consequence is that most real numbers,
if the word "most" is used in almost any sense, are
transcendentals. So a random real number should be transcendental. It
is rather difficult to make sense of the word random in an infinite
setting, which is one of the real difficulties of probability.
Cantor's proof of the existence of transcendental numbers as described above is the only one I knew until fairly recently, but apparently it was his second proof. Earlier in his life, he published a proof which can be described as constructive. A discussion of this proof is in the article Georg Cantor and Transcendental Numbers by Robert Gray, in The American Mathematical Monthly, Vol. 101, No. 9 (Nov., 1994), pp. 819-832. If you are at a Rutgers computer, you should be able to see a copy of this paper using this link.
Yeah, there are lots of them; now show me one!
I know because people have told me that the special numbers e and π
are transcendental. The original proofs of these facts are difficult
and long, and even now, a century later, I do not think there are any
really easy proofs. It would be nice, since most real numbers are
transcendental, to give at least one explicit example of such a
number. Here:
∑n=1∞1/2n!.
The transcendentality of this number is a result of Liouville, whose
name is also attached to other results in math and physics. The
foundation of the rather brief proof is the Mean Value Theorem of one
variable calculus, and the strange statement that algebraic numbers
which are not rational can't be approximated very well by rationals in
a suitable sense. An exposition is here.
We must go on!
The central concerns of the course will frequently be stated in terms
using topology. So we should study a bit of topology. We have a whole
course, Math 441, devoted to this. I've taught it. Let me outline what
my first lecture in that course was about.
How to begin Math 441
My assumption was that not all students were knowledgeable about
advanced math and proofs, but that there would be some recall of
calculus. I "remembered" some definitions and introduced a definition
new to many students.
Definitions
- A sequence of real numbers {xn} converges and has limit the real number L (written as limn→∞xn=L) if, given any ε>0, there is N so that if n≥N, then |xn–L|<ε.
- Suppose f:R→R is a function. f is continuous at a if, given any ε>0, there is δ>0 so that if |x–a|<&delta, then |f(x)–f(a)|<ε.
- A subset U of R is open if, given any w in U, there exists a ρ>0 so that the interval (w–ρ,w+ρ) is inside U.
Theorem Suppose f:R→R is a function. The following logical statements about this function are equivalent.
- If {xn} is any convergent sequence with limn→∞xn=L, then the sequence {f(xn)} also converges, and limn→∞f(xn)=f(L).
- f is continuous at every point.
- If U is any open subset of R, then f–1(U) is an open subset of R.
Proof of b implies c
I will try to verify c, and somewhere I will use b. So suppose U is an
open subset of R, and w is in U. Since U is open, I know there is
ρ>0 so that (w–ρ,w+ρ)⊂U. This interval translates
to the statement: all real y's which satisfy |y–w|<ρ (interval
statement and inequality statement are logically equivalent). Suppose
w=f(a). Then the inequality becomes |y–f(a)|<ρ. Now use b which
declares "there exists" (magic!) δ>0 so that if
|x–a|<δ then |f(x)–f(a)|<ε. But think about this:
it means in turn that the set f–1(U) includes the numbers x
which satisfy |x–a|<δ. But that means (inequality/interval)
(a–δ,a+δ)⊂f–1(U). Think this through: we
have produced an open interval contianing a inside f–1(U),
and we can do this for any a inside f–1(U). Therefore
f–1(U) is open.
There were no other requests until later that afternoon brave Mr. Leven and brave Mr. Kiria came to my office, risking GBH
(in English mysteries, GBH is "grievous bodily harm" but I find to my
horror that GBH is also a text-messaging abbreviation for "great big
hug"). They worked through what I think is a more difficult proof
involving sequences. Let me present their proof here.
Proof of a implies c
I need to convince you that the sequential statement implies the
open/inverse open statement. In fact, here we will proceed by proving
the contrapositive: if the open/inverse open statement is
false, then the sequential statement is false.
Let's suppose I know an open subset U of R so that f–1(U) is not open. Well, this means there's at least one w in U with f(a)=w and one ρ>0 so that (w–ρ,w+ρ)⊂U, so that there is no τ>0 with (a–τ,a+τ) inside f–1(U). Let's use this complicated statement to create a sequence. If n is a positive integer, take τ to be 1/n. The interval (a–1/n,a+1/n) is not a subset of f–1(U), so there must be a number xn in this interval with xn not in f–1(U). That is, |xn–a|<1/n and f(xn) is not in U. Since f(xn) is not in U, it also can't be in the interval (w–ρ,w+ρ) because that interval is a subset of U. Therefore we know that |f(xn)–f(w)|≥ρ.
Putting this all together, we have created a sequence {xn} so that |xn–a|<1/n. Therefore (Archimedean property) this sequence converges to a. But w=f(a), and |f(xn)–f(a)|≥ρ where ρ is some positive number. The sequence {f(xn)} can't converge to f(a)! And a must be false! We have verified if c is false, then a is false. Therefore a implies c.
YOU TOO can try to prove one of the implications guaranteed by the theorem above. Tell me about it, or ask me about it!
So what people then did ...
Historically, people decided that statement c was a neat way of
studying ideas like continuity. It seemed to change inequalities and
complicated implications into "simple set theory" (well, the packaging
was good, but the difficulties are just hidden, not gone!). So a whole
industry was created to understand this sort of approach.
A metric
I defined metric as in the text, commenting that most difficult
rule to verify was usually the triangle inequality. I gave two
examples. The most important example for Math 411 was the Euclidean
metric (square root of the sum of the squares of the differences in
the coordinates). The triangle inequality then is a consequence of the
Cauchy-Schwarz inequality. The silliest example of a metric is the
so-called discrete metric, where d(x,y) is 1 if x≠y and 0 if x=y.
Note that d(x,y) will play the role of |x–y| in arguments similar to
what we just went through.
More definitions
An open ball or open neighborhood was defined as in the
text: Nr(p) is the collection of x's in X with
d(x,p)<r. This plays the part of (p–r,p+r). The open balls in
Rn are "clear". In the discrete metric, an open ball of
radius<1 is just 1 point. If the radius is ≥1, it is
everything.
An open set is one which contains an open ball centered at each
point in the set. The radius, r, of the ball will usually depend on
the point selected! The open sets for the discrete metric are all
subsets of the set!
- An open ball is an open set. I drew a picture so I could remember how to prove this.
- Any open set is a union of open balls. So locally, if we want to understand open sets, just think of a ball.
- The intersection of two open sets is an open set. Take the minimum
of two positive radiuses to get a suitable positive radius. In fact,
this extends to any finite intersection. Generally, an infinite
intersection of open sets need not be open.
Example In R with the Euclidean metric, take Un=(–1/n,1/n). The intersection of this sequence of open intervals (open sets) is just {0} (Archimedean) and a point is not open using the usual metric. - The union of open sets is open.
- The empty set, ∅, and the whole space are open (∅ because there are no points in it to "check"!).
So use these properties to define ...
A topology on a set X is a set of subsets of X, let's call it
Τ, with the following properties:
- ∅ and X are in Τ.
- Finite intersections of elements in Τ are in Τ.
- Any unions of elements of Τ are in Τ.
I'll give some more examples next time, and go through more of chapter 2.
Monday, September 15, 2008
Aim(s) of the courseTo get students comfortable with inequalities and with abstraction, and to encourage a certain self-critical quality when considering one's own proofs (or instructor-critical if nothing else!).
I gave a good proof of the thing I messed up last time.
C
We discussed the complex numbers, C, as
R[i]/(i2+1) and as R2 with vector addition and a
weird kind of multiplication and as 2 by 2 real matrices of a strange
kind (complex conjugation is realized as transpose of matrices in this
guise -- I was, as usual, incorrect!).
I verified a few of the elementary properties of complex numbers, as in the text. I then started to prove the Cauchy-Schwarz inequality. The method I used might have looked a bit different, but was actually the same, as what was in the text. I considered the function f(t)=||A+tB||2 where A and B are vectors in Cn. We knew that f(t)≥0, so when I "expanded" this function using bilinearity, the discriminant of the resulting quadratic was non-positive. This is almost the Cauchy-Schwarz inequality, and I tried to suggest how it would verify the text's version of Cauchy-Schwarz by multiplying one of vectors by the scalar eiθ for suitable choice of θ (to make the appropriate dot product real and positive).
Rn
I discussed enough of Rn to be sure that we could recognize
it as a metric space in a few days. In particular, I got versions of
Cauchy-Schwarz and the triangle inequality.
Sizes of sets (cardinality)
It will be useful to have this language as we discuss certain
examples. So I defined (with help!) the following terms:
- A~B means
A and B have the same cardinality, same size: there is a bijection between them. Then A~A (the identity as a bijection); if A~B then B~A (the inverse of a bijection is a bijection); if A~B and B~C, then A~C (the composition of bijections is a bijection). We will get into serious paradoxes if we consider ~ as an equivalence relation on all sets, however. - A is finite if either A empty or A~{1,2,...,n} for some
positive integer n.
For a fixed non-empty finite set, the integer n is unique (takes some proving!). - A is countably infinite if A~N, where N is the set of all positive integers. Examples of countably infinite sets include N and Z (all integers) and Q, the rationals. There are various sources for an explicit bijection of Q with N (an enumeration) such as Proofs from THE BOOK by Martin Aigner, Günter M. Ziegler, and K.H. Hofmann. However, this follows as a consequence of the fact that the countable union of countably infinite sets is countably infinite. This "fact" uses a Cantor diagonal argument.
- No "biggest" set exists! Given a set A, there is a set B so
that no surjection (onto mapping) exists, and therefore there
is no bijection, so A and B are not the same size. This is proved
using a version of the barber
paradox. Here the following notation is customarily used: if A is
a set, then 2A is the set of all subsets of A. Why this
notation? Well, 2={0,1} (!) and the notation 2A indicates
the mappings from A to {0,1}. A subset T of A corresponds to the
function which is 1 on elements of T and 0 otherwise (the indicator or
characteristic function of T).
Proof: Suppose f:A→2A is a candidate onto mapping. Define T to be the subset of A defined by {x is in A if x is NOT in f(x)}. If T=f(x) for some x, then either x is in T, so x is in f(x) which means x is in T but then (definition of T) x is not in f(x) which is x, or x is not in T, so x is not in T=f(x), so x satisfies the determining property of T and x is in T. Both assumptions lead to contradictions, so no such f exists.
Of course this now means there is no"largest" set, since we can keep taking "subset of ... subset of ...". The universe of sets can be difficult to understand. - A set is countable if it is either finite or countably infinite.
Thursday, September 11, 2008
Again the class began by declaring that the real numbers, R, were a complete ordered field, and, up to field isomorphism, the only such. The construction of R from Q had been incompetently discussed in earlier course meetings.So non-empty subsets of R which have upper bounds will always have least upper bounds, called sups. We verifeid a few standard simple consequences of completeness.
The Archimedian Property
If x>0 and y are real numbers, there is a positive integer N so
that Nx>y.
This was proved last time. To me there is a geometric contect, that if
we lay out a "grating" of width x on the real line, we will always
"trap" y inside the grating. If you believe that the Archimedean
property is somehow intuitive then probably you have not met the long
line which locally looks just like R but is much, much longer. It
is irritatingly unintuitive.
The Archimedean property says that the real numbers can't contain infinities. Take reciprocals, and we see that infinitesimals can't exist either (a pity, because many analysts, me included, frequently think about proofs with them).
Corollary
If x>0, then there is a positive integer N so that 0<1/N<y.
I needed a simple inequality to get a multiplicative version of the
Archimedean property. In some textbooks this is called Bernoulli's
Inequality. Here it is:
If x>1 and n≥2, then xn>1+n(x–1).
This can be proved directly using mathematical induction (verify for
n=2; assume for n, multiply both sides by x and juggle some algebra to
get the statement for n+1). Or if you know the Binomial Theorem, look
at the first two terms of the expansion of
xn=(1+[x–1])n.
A sort of multiplicative Archimedean property
If x>1 and y are real numbers, then there is a positive integer N
so that xN>y.
This is true because we can select N so that 1+(N–1)x>y, and then
use the previous lemma.
These observations will be used again and again.
Then I turned to more ambitious verifications. I said there were three statements which the proved directly from completeness. Here is what they are, in order (to me!) of increasing difficulty and here is what we did (and will do). All of these statements could be quite easily proved once the machinery of one variable calculus has been developed, so these direct proofs, while they are all elementary, all involve some intricate contortions of logic.
- If n is a positive integer, then there always are nth
roots of positive numbers. That is, if y>0, we solve the equation
xn=y with x>0.
This is the easiest, and the proof is laid out in the book, and the instructor will read the book to the class. - If b is a positive real, we can define bx for any real
number x is an algebraically satisfying way, extending and consistent
with our previous uses of the exponentiation notation.
This is more intricate. It is problem 6 in chapter 1. Only an outline is presented there, and a number of irritating, mostly but not all (to me) easy details need to be verified. Ms. Slusky will present this, with her preparation aided by Ms. Sergel. - Logs exist.
This may be even more intricate. It is problem 7, and I asked you to write a solution and hand it in at Monday's class.
Roots exist Given y>0 real and a positive integer n, there
is a unique x>0 so that xn=y.
Proof I won't write out the details, since I basically copied
what was in the text except that I tried to show how a proof of this
result could be discovered. So we consider the set of real numbers,
S={x: xn<y}. The logical outline of the proof follows:
- S is not empty.
- S is bounded above.
- sn<y leads to a contradiction.
- sn>y leads to a contradiction.
I proved 1 as in the text: take y/(1+y) which is a positive number less than 1 and less than y. Integer powers of numbers between 0 and 1 "shrink" so this provides an element of S.
I proved 2 as in the text: take 1+y, larger than both 1 and y. Integer powers increase, so 1+y is not in S, and, because x1<x2 implies (x1)n<(x2)n we know that no number bigger than 1+y is in S, and therefore S is bounded above. Notice that the observation given also implies that nth roots, if they exist, must be unique. Then I tried 3. There is a complete proof, awesomely well-arranged, in the text, so I tried to understand how that proof might have been invented. Well, if sn<y, we can try to kick "up" or increase s and get another number whose nth power is still less than y. So let's look at s+h with h some "small" positive number to be determined. Well, notice that (s+h)n≤sn+STUFF. We'd like this to still be <y. So we need STUFF<y–sn, and y–sn is some random positive number. So how can we choose h? This is the origin of Rudin's specification. You could try to finish this yourself, please, with the book and notes closed. Here is the case n=3.
STUFF=h(3x2+3xh+h2)≤ h[max(3,3,1)x2] if h≤ x. So to get this less than y–x3, take h positive which is also less than (y–x3)/[max(3,3,1)x2], and b is done for n=3.
4 is proved similarly.
I made a very bad mistake
What I did to prove 3 in class was wrong and I was too excited
and went too darn fast to notice. I am sorry. So what did I do and how
did my spurious argument go? I had sn<y and wanted
h>0 so that (s+h)n<y. Then somehow (stupidity!!!) I
used the true observation that
sn<sn+hn<(s+h)n
combined with selesting h so that sn+hn<y to
conclude that I had found a satisfactory s+h (one with
(s+h)n<y). This is an inference which is NOT valid. So:
a<b<c and b<d does not necessarily imply that c<d (find
some numbers, if nothing else, and use that to convince yourself!).
I am sorry. The comments above for n=3 show how I should or could have correctly ended the proof.
Problem 6
The existence of real powers of positive numbers was nicely discussed
by Ms. Slusky. Here is a
pdf she supplied for the class. I thank her for her work.
Monday, September 4, 2008
The lecturer did not do very well at all. He/I attempted to describe certain aspects of the formal verification that Dedekind cuts are a field. I thought this would take 12 to 15 minutes. Hah. I spent more than an hour, and got almost nowhere. "It's all in the book." If that is correct, what is the purpose of the class? Don't ask. The remarkable and wonderful fact that the rational numbers are Archimedean contributes importantly to the proof that some of the field axioms are valid for the real numbers, considered as a set of cuts.I did prove one easy consequence of completeness, the Archimedean property, and the further consequence that there are no positive reals smaller than 1/n where n runs through all positive integers. The Archimedean proof would be an offense to constructivists, and the fact about 1/n would be false to folks who like infinitesimals (that probably includes most analysts!).
Maybe things will go better next time. It can't be worse. We will be treated to Ms. Slusky, coached by Ms. Sergel, giving a beautiful presentation of problem #6 on irrational powers. It's gotta be better than ... well, enough ...
My reasons for volunteering early
- Probably the material is easier.
- The instructor is positively impressed by your enthusiasm.
- Your presentation is more likely to be one of the very best if so far there haven't been many (less competition!) -- later that's more difficult to tell.
Thursday, September 4, 2008
The word gloss has a number of meanings. Some of them include the following:- an explanation or translation, by means of a marginal or interlinear note, of a technical or unusual expression in a manuscript text.
- a series of verbal interpretations of a text.
- a glossary.
- an artfully misleading interpretation.
We investigated the statement
R is a complete ordered field
Field
A field is a set with two "operations", addition and
multiplication, each a functon
from pairs of elements of the set to the set. Each operation is
commutative and associative, and each has an identity. Inverses also
exist (except that 0 doesn't have a multiplicative inverse otherwise
things would be very silly!). And there's a distributive law, relating
multiplication and addition.
With no further elaboration, there are many examples, highly varied, ranging from finite fields to "big" examples such as fields of rational functions. Field theory is rich enough to totally support such intellectual enterprises as linear algebra and investigating the relations between fields is an interesting and worthwhile part of algebra.
We rapidly worked through a few simple consequences of the field axioms (pp.6-7) such as –(–x)=x and 0x=0.
Ordered
An ordered set in the text is a set with a relation, <,
which is transitive (x<y and y<z implies x<z) and has
trichotomy (exactly one of these statements is true: x<y, x=y,
y<z). An ordered field is an ordered set which further obeys
these rules: if x<y then x+z<y+z, and x>0, y>0 implies
xy>0.
In other texts an ordered field is a field which contains a subset P (of "positive" elements) so that one of these is true: x=0 or x is in P or –x is in P; and P is closed under addition and multiplication. We verified that our text's defintion agreed with this one with x<y defined as y–x is in P. Also we checked a few simple consequences of the ordered field rules (p.8). It is true that an ordered field has characteristic 0. I didn't state this, but if you know what characteristic means, you can probably verify it.
An upper bound for a subset W of an ordered set is an element t so that for all w in W, either w<t or w=t (together written as w≤t). A least upper bound of a set W is an upper bound which is ≤ any other upper bound. Trichotomy implies that a least upper bound, if it exists, must be unique. Such an element will be called sup W. The dual notions are lower bound and inf, the greatest lower bound.
Finite ordered sets have sups (they are actually maxes and mins). For a more relevant and interesting example we used Q and its subsets.
The rational numbers, Q
The text assumes known the ordered field of rational numbers, Q,
together with its properties and its representation as quotients of
integers. This information can be deduced from more primitive notions
(see some of the references) but we begin here in 411.
Q itself does not have an inf or a sup.
The important definition that I forgot (at first) in class is of the word complete. An ordered set is complete if every non-empty subset with an upper bound has a sup. The word "non-empty" is important, since the empty subset has many upper bounds but may not have a sup (check this for the empty subset of Q).
Q's major defect from the analysis point of view is that it is not
complete. The usual discussion involves "sqrt(2)". The reason for the
quotes is
There is no rational number whose square is 2.
You should know how to prove this. Does the proof work for 3? Does it
work for 4? Why or why not?
Notice that this statement does not necessarily imply that Q is not complete. A similar statement ("no rational number has square –1") is true for both Q and R, although R is complete. The distressing thing about the statement is that it shows the need for completeness if you want nice calculus. For example, look at the graph of y=x2–2 in the "rational plane", Q2. This graph violates the conclusion of the Intermediate Value Theorem!
Suppose C is the collection of rational numbers whose square is less than 2 or which are negative. This is a silly looking set, an infinite half-line. The reasons for considering this particular set will become clear later. Then:
- C is bounded above (by, say, 3).
- If v is a rational upper bound of C, there is a rational upper bound w with w<v.
- If a rational number v is in C, there is a rational number w in C with v<w.
A major achievement, possible to do in a number of ways, is to show the following:
- There is a complete ordered field. I'll discuss this but not verify all the details since that would probably take 3 or 4 class meetings!
- All complete ordered fields are "order field isomorphic". That is, given any two such, there is a bijection F which "preserves" addition and multiplication and order: F(x+y)=F(x)+F(y) and F(xy)=F(x)F(y) and F(x)<F(y) whenever x<y.
This is a really nice fact. I will not go through the proof in detail, since we won't need any of these techniques later in this course. It is certainly a part of "mathematical literacy" to know something about these ideas, and similar ideas are used in other mathematical fields. I hope to show you enough so that you can see how clever it is, and also so that you can see the difficulties.
"Construction" of R from Q using Dedekind cuts
Our complete ordered field, which we will call the real numbers, R,
will be a collection of subsets of Q. This is a rather sophisticated
notion. The subsets are called Dedekind cuts or just cuts. So: a
subset C of Q is a cut if
- C is neither the empty set nor all of Q.
- If w is in C and v<w, then v is in C.
- If w is in C, then there is v in C with w<w.
References
The text describes this whole setup, with proofs, in less than 5 pages
of the Appendix to Chapter 1. A more leisurely (25 pages!) discussion
is available in Spivak's Calculus book which you can borrow
from me.
I won't go through all details because that would probably take 3 or 4 lectures. I will try to do enough so that you can appreciate the cleverness and also understand the intricacy of certain verifications. I won't need the techniques of these proofs later in this course, but I will remark that knowing about the setup is certainly part of everyone's mathematical literacy, and also analagous constructions are used in other fields with great success.
Cuts and <
If C1 and C2 are cuts, then we define
C1<C2 to mean: C1 is a proper
subset of C2. (Cute!)
Completeness of the set of cuts
It turns out with all of these definitions, completeness is easy. Since this is what is usually quite difficult,
maybe the payoff is right here, upfront. So what do we do? Suppose
{Ca} for a in A is some non-empty set of cuts which is
bounded above by the cut D. This means that each Ca is a
subset of D. Let C be the union of all the cuts Ca. I claim
that D is the sup of the set of Ca's. We need to
verify:
- C is a cut. This is usually the most irritating part, as you will see. Here it is not difficult. So: since D is a cut, D is not all of Q, and therefore the union of the Ca's is a subset of D and is not all of Q. It is also not empty, since the set A is not empty by assumption. Also, if w is in C then w is in some Ca. So all v's less than w are in that Ca and these v's must be in D. Similarly, if w is in C and thus in some Ca we can find v larger than w in that Ca and thus in C.
- C is an upper bound of the Ca's. True since each Ca is a subset of C, so each is either < or = to C.
- C is a least upper bound. If E is another upper bound, then for each a, Ca≤E, so the union of the Ca's is a subset of E. And that's exactly C≤E.
This method makes verifying completeness easy. Some of the extensive details involving the algebra are difficult. Let me just discuss addition.
Addition of cuts
If C and C' are cuts, we will define a subset of Q to be called
C+C'. So z is in C+C' if z=x+y for some x in C and y in C'.
We now need to verify that C+C' is a cut, we need to check
commutativity and associativity, identify and check an additive
identity, and look for additive inverses. I'll do some of this next
time.
Maintained by greenfie@math.rutgers.edu and last modified 9/5/2008.