| Date | What happened |
|---|
| 4/14/2003
| The review session on Tuesday evening, April 15, will be in
Hill 425 at 6:10 PM.
I began by doing problem #2 in section 5.4 Suppose
f(x)=1/x2. Show that f is uniformly continuous on
A=[1,infinity) and is not uniformly continuous on B=(0,infinity).
We first try to "link" f(x)-f(y) and x-y. Since f is given by a fairly
simple algebraic formula, this works well:
f(x)-f(y)=(1/x2)-(1/y2)=(y2-x2)/(x2y2)=(y+x)(y-x)/(x2y2).
If we knew that |f(x)-f(y)|<2,304|x-y|, then we could verify the
definition of uniform continuity by taking delta=epsilon/(2,304). So
the "art" here is one of getting a useful overestimate of the other
factors:
(y+x)/(x2y2). Here let's be in A, so that
y>=1 and x>=1. Then
(y+x)/(x2y2)<=y/(x2y2)+x/(x2y2)=1/(x2y)+1/xy2<=1+1=2
because 1/(stuff>=1) is <=1. So if x and y are in A, then
|f(x)-f(y)<=2|x-y|. Therefore, given epsilon>0, we can take
delta=epsilon/2. The 2's will cancel, and if |x-y|<delta, we know
that |f(x)-f(y)|<epsilon.
On B we must show that f is not uniformly continuous. That is,
we must show that there is an epsilon>0 so that for any delta>0,
there are x and y in B satisfying |x-y|<delta and
|f(x)-f(y)|>=epsilon. This f is a simple function and simple
choices will work. We can take epsilon=1. We will find sequences
(xn) and (yn) in B so that
|xn-yn|<1/n but
|f(xn)-f(yn)|>=1. The suggestion was made
that we take xn=1/(n+1) and yn=1/n. Then
xn-yn=(n-(n+1))/(n(n+1))=1/(n(n+1)), and this is
certainly less than 1/n. Also
f(xn)-f(yn)=(n+1)2-n2=n2+2n+1-n2=2n+1,
which is certainly greater than 1. So we have verified that f is
not uniformly continuous. Notice that as n-->infinity, the points
of the sequences go towards the "edge" where f becomes more
"tilted".
We have now the following examples:
1. f(x)=x2, domain [0,1], is uniformly continuous.
2. f(x)=x2, domain [1,infinity) is not uniformly
continuous.
3. f(x)=1/x2, domain [1,infinity), is uniformly
continuous.
4. f(x)=1/x2, domain (0,infinity), is not uniformly
continuous.
These examples might seem to support some sort of conjecture that if
the range is "big" (unbounded) then a continuous function is not
uniformly continuous, while if the range is "small" (bounded) then a
continuous function is uniformly continuous. Neither of those
statements is correct.
If f(x)=x and the domain is R, then f is uniformly
continuous. (We can take delta=epsilon.) The range of this f is all of
R, an unbounded set.
If f(x)=sin(1/x) and the domain in (0,1), then f is not uniformly
continuous. This is because the function sin(1/x) oscillates back and
forth between +1 and -1 "faster" and "faster": that is, take
epsilon=2. sin(1/x) is +1 when x=1/(2nPi+Pi/2) and sin(1/x) is -1 when
x=1/(2mPi+3Pi/2) and n and m are any integers. Notice that
|1/(2nPi+Pi/2)-1/(2nPi+3Pi/2)|<=Pi/[(2nPi+Pi/2)(2mPi+3Pi/2)]<1/n.
Therefore given any delta>0, we can find n so that these two values
of x are less than 1/n apart, and their values of sin(1/x) still
remain 2 apart. I certainly should have discussed this in
more detail in class! The range of this function is [-1,1], certainly
bounded.
Our conjecture was untrue. Here's the most important result.
Theorem (Continuous functions on closed, bounded intervals are
uniformly continuous) Suppose f:[a,b]-->R is
continuous. Then f is uniformly continuous.
Proof: We proceed by contradiction. Suppose that f is not
uniformly continuous on [a,b]. Then there must be an epsilon>0 and
sequences (xn) and (yn) in [a,b] so that
|f(xn)-f(yn)|>=epsilon with
|xn-yn|<1/n. Wow! Quite a lot of
information.
Since (xn) is a sequence in [a,b] we may apply the
Bolzano_weierstrass Theorem: there must be a subsequence
(xnk) which converges to some number q. And
since all of the xnk's satisfy the inequality
a<=xnk<=b the limit, q, must also satisfy
the inequality, so q is in [a,b]. Now we know that
|xnk-ynk|<1/nk
and since we are dealing with a subsequence, nk>=k, so
that nk>=k. This means that
|xnk-ynk|<1/k: so the
two subsequences are squeezed to the same limit, q. Now we are almost
done.
(xnk) converges to q in [a,b] and
(ynk) converges to q in [a,b]. The function f is
continuous at q, so therefore the sequence
(f(xnk)) converges to f(q) and the sequence
(f(ynk)) converges to f(q) also.
That means the distance between corresponding terms must -->0. But
this contradicts |f(xn)-f(yn)|>=epsilon
for all n. So we are done because we found a contradiction.
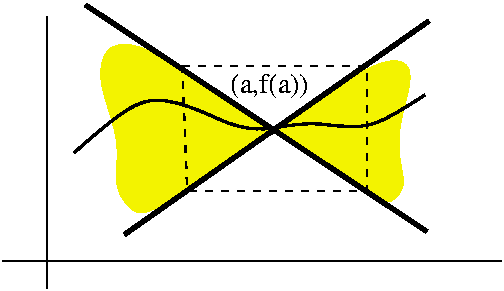
The most common way that an effective connection between epsilon and
delta is found uses what is called a Lipschitz condition.
f:A-->R satisfies a Lipschitz condition with positive constant K if
for all x and y in A we know that |f(x)-f(y)|<=K|x-y|. What does
this condition "mean"? Well, first, in terms of epsilon and delta, if
we are given epsilon>0, we could take delta=epsilon/K. The
implication "If |x-y|<delta then |f(x)-f(y)|<epsilon" would be
true. Geometrically, the inequality |f(x)-f(y)|<=K|x-y| is the
same as "the slope from (x,F(x)) to (y,F(y))" is between -K and
K. This would imply that if (x,F(x)) were on the graph, then the graph
would be caught between lines of slope K and -K going through
(x,F(x)). And then we could certainly put a rectangular box centered
at (x,F(x)) on the graph so that the graph escaped out the "vertical"
sides of the box. The box here is supposed to match the one drawn in
the last lecture illustrating the delta-epsilon box for uniform
continuity.
If we knew more about calculus, then we could assert the following: if
f is differentiable on the interval [a,b], and if |f'(w)|<=K for
all w in [a,b], then the Mean Value Theorem would imply
|f(x)-f(y)|<=K|x-y|, because (f(x)-f(y))/(x-y)=f'(w) for some w in
the interval between x and y. This is actually the way people
frequently get estimates relating to uniform continuity. It is much
more constructive than using the Bolzano-Weierstrass Theorem as part
of a proof by contradiction!

|
Boxes don't imply butterflies
|
The function sqrt(x) is continuous on [0,1], and by the theorem proved
just above, it must be uniformly continuous on [0,1]. However, there
is no K so that |sqrt(x)-sqrt(y)|<=K|x-y|. To see this, just take
y=0. Then the inequality becomes sqrt(x)<=Kx or (dividing by
sqrt(x)) just 1<Kx3/2. As x-->0, the right-hand side
goes to 0 while the left stays at 1. So there is no "butterfly" of any
angle which can sit anywhere on y=sqrt(x) and always have the graph
within its wings. There is, however, a box which works: that is the
meaning of uniform continuity.
The picture displayed essentially attempts to show that a box which
works at the origin for sqrt(x) will be satisfactory elsewhere. A
"butterfly" won't "fly" too well at the origin, basically because the
tangent line becomes perpendicular there.
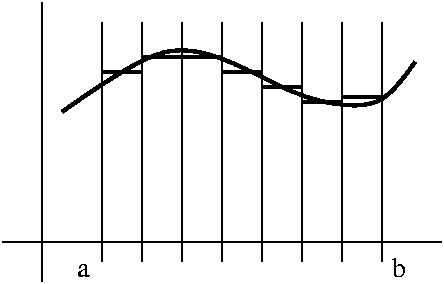 Uniform continuity will let us integrate continuous functions. Here is
what we will do (this is essentially theorem 5.4.10 of the text). A
step function will be defined by the following requirements: a
"partition" of the interval [a,b] of this
type:a=x0<x1<...<xn-1<xn=b,
and selection of n numbers y1,...,yn. Then we
will define S(x) to be yj if x is in the interval
[xj-1,xj). (If you are paying very close
attention, you should see that the last interval needs special
treatment, when x=b.) The idea is to approximate a continuous function
f very closely by a step function. The steps of the step function and
the boxes used in uniform continuity should seem to be related. The
integral of a step function is easy: it will just be a sum of areas of
rectangles. So this will approximate the integral of the continuous
function. And if we can show that this approximation works well with
area, then we will have defined the integral of a continuous
function. Theorem 5.4.10 essentially describes one approach to this
approximation. I will return to this later, and discuss it in more
detail when we do integration.
Uniform continuity will let us integrate continuous functions. Here is
what we will do (this is essentially theorem 5.4.10 of the text). A
step function will be defined by the following requirements: a
"partition" of the interval [a,b] of this
type:a=x0<x1<...<xn-1<xn=b,
and selection of n numbers y1,...,yn. Then we
will define S(x) to be yj if x is in the interval
[xj-1,xj). (If you are paying very close
attention, you should see that the last interval needs special
treatment, when x=b.) The idea is to approximate a continuous function
f very closely by a step function. The steps of the step function and
the boxes used in uniform continuity should seem to be related. The
integral of a step function is easy: it will just be a sum of areas of
rectangles. So this will approximate the integral of the continuous
function. And if we can show that this approximation works well with
area, then we will have defined the integral of a continuous
function. Theorem 5.4.10 essentially describes one approach to this
approximation. I will return to this later, and discuss it in more
detail when we do integration.
|
| 4/10/2003
| I did some problems in the textbook and made some other
comments.
Section 5.3, problem #1 If I=[a,b] and f:I-->R is
continuous, and if f(x)>0 for all x in [a,b], then there is
alpha>0 so that f(x)>=alpha for all x in [a,b].
Proof: Use the Extreme Value Theorem (Theorem B from the last
lecture). Then we know there is v in [a,b] so that f(v)<=f(x) for
all x in [a,b]. Take alpha=f(v), and since all values of f are
positive, this alpha will serve.
Comment Consider [a,b]=[0,1] and f(x)=x if x>0 and
f(0)=1. This f fails to be continuous at only one point (x=0) and its
values are positive for all x. But the inf of f's values is 0
so there is no positive lower bound.
Section 5.3, problem #3 If I=[a,b] and f:I-->R is
continuous, and if for every x in [a,b] there is a y in [a,b] so that
if |f(y)|<=(1/2)|f(x)|, then f has a root in [a,b]: there must be r
in [a,b] with f(r)=0.
Proof: Suppose f has no root in [a,b]. Then (using the Intermediate
Value Theorem, that is, Theorem C from the last lecture) either all of
f's values are positive or all of f's values are negative. (If f has
both positive and negative values, then it must have a root.) We will
consider here the case that f(x)>0 for all x in [a,b]. The other
case can be proved by considering, say, -f(x).
Now we have f(x)>0 for all x in [a,b]. By the preceding problem, f
has a positive minimum value, f(v). But take "x=v" in the hypotheses
to this problem. We then see there must be y in [a,b] such that
f(y)<=(1/2)f(v)<f(v) (no absolute value signs are needed since
we know in this case all function values are positive). But then f(v)
isn't the minimum value of f, which is a contradiction.
Section 5.3, problem #4 Show that every polynomial of odd
degree with real coefficients has at least one real root.
Discussion: Here I began by considering an example, something like
P(x)=x5+44x4-403x3+22x-9. Let me call
the terms less than the "top" term J(x). So here
J(x)=44x4-403x3+22x-9. Essentially the odd
degree term, x5, "dominates" J(x) when x is large positive
or negative (this is a version of the statements that the limit of
P(x) as x goes to +/-infinity is +/-infinity). What do I mean? Well,
|J(x)|=|44x4-403x3+22x-9|<44|x|4|+403|x|3+22|x|+9<=(44+403+22+9)x4
when |x|>1. In fact, if, say, x=+/-109 (this was the
value suggested by students) then |J(x)|<|x|5. Since the
inequality is < this means that the sign of P(x) is the sign
of x5 for these two values of x. Since 5 is odd, this means
that P(+/-109) has +/-signs. So on the ends of the interval
[-109,+109], P(x) changes sign. And P(x) must
have a root inside this interval by the Intermediate Value
Theorem.
The general case proceeds analogously. The highest degree term is the
dominating term for x's which are large enough positive and negative,
and since the degree of the dominating term is odd, the signs differ
for positive and negative x's. So we know that functions like
x17+808x4cos(x4+98) must have at
least one real root.
Section 5.3, problem #6 f:[0,1]-->R and f(0)=f(1). Then
there is c in the interval [0,1/2] so that f(c)=f(c+1/2).
Proof: Here the (non-obvious!) way to get c is to consider another
function: g(x)=f(x)-f(x+1/2). g is continuous on the interval [0,1/2]
by results on algebra and composition of continuous
functions. g(0)=f(0)-f(1/2) and g(1/2)=f(1/2)-f(1)=-g(0). If g(0)=0,
we are done (take c=0). If g(0)>0, then g(1/2)<0, so the
Intermediate Value Theorem guarantees a c in [0,1/2] with g(c)=0 and
again we are done. Finally, if g(0)<0, then g(1/2)>0, so we can
get g(c)=0 again, etc.
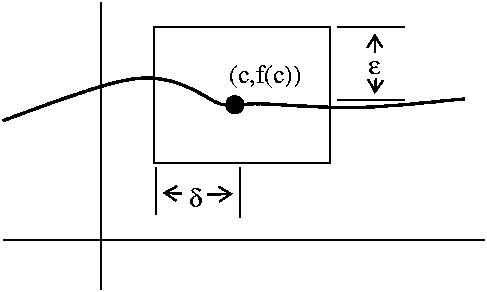 Now I restated the definition of continuity:
Now I restated the definition of continuity:
f:A-->R is continuous at c in A when: given
epsilon>0, there is delta>0 so that for all x in A satisfying
|x-c|<delta, we know |f(x)-f(c)|<epsilon.
In geometric terms, this means we have a rectangular box with center
at (c,f(c)) and with horizontal sides +/- epsilon from y=f(c) and with
vertical sides +/-delta from x=c. The graph of y=f(x) is only
"permitted" to "escape" from the box through the vertical sides. So
when epsilon is specified, we can construct some box satisfying these
geometric constraints.
Here's another definition:
f:A-->R is uniformly continuous in A when: given
epsilon>0, there is delta>0 so that for all x and c in A satisfying
|x-c|<delta, we know |f(x)-f(c)|<epsilon.
Therefore in this case, the same sized box will work for all points on
the graph. We then considered the function f(x)=x2 and
tried to slide boxes around on the graph. We came up with some
conjectures which we then verified.
Example 1 (uniform continuity satisfied) f(x)=x2 is
uniformly continuous in A=[0,1]. Geometrically, this is because we can
slide the "box that works" from its center at (1,1) down the graph to
(0,0) and it will always "work". Let's see:
|f(x)-f(c)|=|x2-c2|=|x+c|·|x+c|<=(|x|+|c|)·|x-c|.
If both x and c are in [0,1], then we know
|f(x)-f(c)|<=2|x-c|. Therefore, if epsilon>0 is given, we could
take delta=(1/2)epsilon, and this will satisfy the definition of
uniform continuity for this f and A=[0,1].
Example 2 (uniform continuity not satisfied) f(x)=x2
is not uniformly continuous in all of R. Geometrically, this is
because the function "wiggles" or "tilts" too much as |x| gets
large. If we take any box and move it so that its center is on the
graph, if the box is moved far enogh to the right or to the left,
eventually the graph will start poking out the top or the bottom of
the box.
We need to verify that the definition is not fulfilled in
the style of Math 311. So we must show that there is some epsilon>0
so that for all delta>0 there are x and c with |x-c|<delta with
|f(x)-f(c)|>=epsilon. In fact, this is nicely done with a
sequential approach. We can do this for any delta exactly when we can
do it for 1/n (for any n in N) -- this uses the Archimedean
property. So we will find epsilon and xn and cn
so that the following is true:
epsilon>0
|xn-cn|<(1/n)
|xn2-cn2|>=epsilon.
We debated how to find these. The instructor suggested
xn=n, and then we were happy: cn=n+(1/(2n))
makes everything work with epsilon=1. This is verified by direct
computation:
|xn-cn|=1/(2n)<1/n and
|xn2-cn2|=|n2+1+1/(4n2)-n2|>=1.
Next time we will use a proof by contradiction to verify:
Theorem A function which is continuous on a bounded, closed
interval must be uniformly continuous.
This will be a vital ingredient when we integrate continuous
functions.
|
| 4/9/2003
| Propositions I and II and III are already known, and are
stated here in order to help people understand the lecture.
Proposition I If (xn) is a convergent sequence and
if, for all n in N, xn is in [a,b], then
lim(xn) is in [a,b].
Comments: This is an easy consequence of such sequential limit facts as:
if L=lim(xn) with xn>=0 for all n, then
L>=0. Just compare the xn's with a and with b
(look at b-xn and xn-b).
Proposition II Suppose (xn) is a sequence with
xn in [a,b] for all n in N. Then there's a
subsequence (xnk) which converges.
Comments: This is the Bolzano-Weierstrass Theorem. It is generally
impossible (or at least difficult!) to discover the subsequence.
Proposition III If (xn) converges and f is
continuous, then the sequence (f(xn)) converges, and its
limit is f(lim(xn)).
Comments: This is the sequential statement which is equivalent to
continuity.
Theorem A (continuous functions on closed bounded intervals are
bounded) If f is continuous on [a,b], then there is M>0 so that
|f(x)|>M for all x in [a,b].
Comment: The phrase "f is continuous on [a,b]" means f is continuous
at each x in [a,b].
Example A1 A function not continuous at one point of a closed
bounded interval and the function is not bounded: take [a,b]=[0,1] and
f(x)=1/x for x>0 and f(0)=0. f is not bounded, since f(1/n)=n for n
in N and we have the Archimedean property.
Example A2 A function continuous on an open interval which is
not bounded: take (a,b)=(0,1), and f(x)=1/x.
Proof of Theorem A: Suppose f is not bounded. Then for n in N,
there exists xn in [a,b] with |f(xn)|>=n. By
Proposition II, the sequence (xn) has a subsequence
(xnk) which converges. Also,
|f(xnk)|>=nk>=k. By Proposition
I, the limit of the subsequence is in [a,b]. We have assumed that f is
continuous at all points of [a,b], so it must be continuous at the
limit of the subsequence, and therefore by Proposition III,
(f(xnk)) converges. But a convergent sequence of
real numbers is bounded, and this sequence is not bounded since
its kth element is at least k. This is a contradiction.
Theorem B (Extreme Value Theorem) If f is continuous on [a,b],
then there are elements v and w of [a,b] so that
f(v)<=f(x)<=f(w) for all x in [a,b].
Comment: So the function "achieves" its maximum and minimum
values. And the range of the function must be a subset of the interval
[f(v),f(w)].
Example B1 A function which is continuous at all but one point
of a closed bounded interval and the function is bounded and the
function does not "achieve" its sup and its inf: we decided that if
[a,b]=[-1,1] and f(x)=x+1 for x in [-1,0), f(0)=0, and f(x)=x-1 for x
in (0,1], then the range of f is the open interval (-1,1). f is
discontinuous only at 0. The sup of f's values is 1 and the inf of f's
values is -1, and f never attains either 1 or -1: a fairly weird
example.
Proof of Theorem B: Since f is continuous on [a,b], Theorem A
applies and f must be bounded. Therefore the set S={f(x): x in [a,b]}
(the set of values of f) is non-empty (f(a) is in S) and is
bounded. By the Completeness Axiom, S has both a sup and an inf. We
will work with the sup, which will produce f(w). Parallel work with
the inf will get f(v). Let q=sup S. Then given n in N, there is
an element yn of S so that q-(1/n)<yn<=q
(this is the alternative characterization of sup). But since
yn is in S, there is xn in [a,b] with
f(xn)=yn.
By
Proposition II, the sequence (xn) has a subsequence
(xnk) which converges. Also,
q<=|f(xnk)|>q-(1/(nk))>=q-(1/k).
By Proposition
I, the limit of the subsequence is in [a,b] and is a point, w. We have assumed that f is
continuous at all points of [a,b], so it must be continuous at the
limit of the subsequence, and therefore by Proposition III,
(f(xnk)) converges to f(w). But f's values on
this subsequence are squeezed to q, and therefore f(w)=q, the sup of
the values of f([a,b]).
Corollary Values of continuous f on [a,b] always lie inside
some closed bounded interval: f([a,b]) is a subset of [min value of f
on [a,b],max value of f on [a,b]].
Theorem C (Intermediate Value Theorem) If f is continuous on
[a,b], and if f(a)<0 and if f(b)>0, there is a element r of
[a,b] with f(r)=0.
Example C1 A function not continuous at only one point, with
only two values, which doesn't have any roots: here [a,b]=[0,1] and
f(x)=-1 for x=0 and f(x)=1 for x>0. This is a silly example, but it
works.
Example C2 How many roots can such a function have? We saw that
such a function can actually have any finite number of roots, and it
even can have an infinite number of roots.
Proof of Theorem C: The text uses the bisection method which leads
naturally to an algorithm used for root-finding. Please look at the
text and see if you like that proof. I'll try another
technique here.
Let T={x in {a,b]: f(x)<0}. Now T is not empty since a is in T. T
is bounded, since T is a subset of [a,b] and b is an upper bound of
T. Therefore the completeness axiom applies, and T must have a least
upper bound, which we will call r. So r=sup(T). Either f(r)<0 or
f(r)>0 or f(r)=0 by Trichotomy. We will "eliminate" (proof by
contradiction) the first two alternatives, so that the last must be
true.
What if f(r)<0? Then r<b (since f(b)>0). By continuity of f
at r, there is delta>0 and an interval [r,r+delta) where if x is in
that interval, f(x)<0. But x must be in T, then, and therefore r
cannot be an upper bound of T. Contradiction.
What if f(r)>0? Then r>a (since f(a)<0). By continuity of f
at r, there is delta>0 and an interval (r-delta,r] where if x is in
that interval, f(x)>0. But if r is the least upper bound of T,
there must be an element x of T in that interval, and for that
element, f(x)<0. Contradiction.
Of course the function takes on all "intermediate" values, not just
0. And we have the important:
Interval Mapping Theorem If f is continuous on [a,b], and if
the maximum value of f on [a,b] is M (M is what I called f(w) before)
and if the minimum value of f on [a,b] is m (m is what I called f(v)
before) then the collection of all of f's values is [m,M].
All the results of this class session are almost part of our
subconscious: probably Piaget showed that young babies "learned" them
at a very early age. Is the intellectual structure of the course worth
the difficult trip we have gone through? That is to be judged by each
individual, naturally. I like it.
There will be an exam on Thursday, April 17. Here is information about the exam,
and a collection of review problems.
|
| 4/7/2003
|
Many fine students showed up for class today in the midst of an
unseasonal snow storm. I proved that composition of continuous
functions was continuous.
Theorem (Composition and continuity) Suppose f:I-->R and
g:J-->R, and we know that f(I) is a subset of J. Also suppose
that f is continuous at c and that g is continuous at f(c).
Then the composition of g with f is continuous at c.
Proof: 1Since f is continuous at c we know:
given alpha>0 there is beta>0 so that if |w-c|<beta and w is
in I, then |f(w)-f(c)|<alpha.
2Since g is continuous at f(c) we know: given
gamma>0 there is delta>0 so that if |v-f(c)|<delta and v is
in J, then |g(v)-g(f(c))|<gamma.
3We must prove the following implication: if
epsilon>0, then there is rho>0 so that if |b-c|<rho and b is
in I, then |g(f(b))-g(f(c))|<epsilon.
The "unconventional" letters really help in making readers concentrate
about what's going on (I think so, anyway!). So suppose epsilon>0
is given. Then use 2 with gamma=epsilon. We
then get some delta>0. Then use 1 with
that delta taken as alpha. The beta guaranteed will work as the rho
needed in 3. Why is this? If |b-c|<rho and
b is in I, then 1 guarantees that
|f(b)-f(c)|<delta. Of course, f(b) is in J by the hypotheses of the
theorem. Then 2 guarantees that
|g(f(b))-g(f(c))|<epsilon as desired.
Comments We can't generally drop any of the hypotheses of the
theorem and expect the conclusion to remain valid. For example, if
f(x)=x, any discontinuity of g will be "transmitted" to the
composition. Similarly, if g(x)=x, the composition will have f's
discontinuities.
I then announced that an EXAM would be given on
Thursday, April 17. My current intention is to cover the major results
of section 5.3 on Wednesday, and then the definition and simple
examples about uniform continuity on Thursday (section 5.4). The exam
would include coverage of that material. I hope to give out a review
sheet on Wednesday, and may try to schedule a review session next
week. We mostly did textbook homework problems for the remainder of
today's class.
Section 5.2, #3 Give an example of functions f and g both
discontinuous at c in R such that a) the sum f+g is continuous at c b)
the product f·g is continuous at c.
Solution: We debated whether the example requested by the text needed
to satisfy both a) and b) or whether two examples were being
requested. Mr. Benson cut short the debate by giving an example which
indeed did satisfy both a) and b): f(x)=1 if x=0 and f(x)=0 otherwise;
g(x)=0 if x=0 and g(x)=1 otherwise. One of the first examples we
analyzed in connection with continuity essentially showed that both f
and g were not continuous at 0. But f+g is the function which
is always equal to 1, and f·g is always equal to 0, so both of
these functions are certainly continuous at 0. This is a very neat
example.
Section 5.2, #7 Give an example of a function f from [0,1] to
R which is not continuous at every point of [0,1] but
|f|is continuous at every point of [0,1].
Solution: I have forgotten who gave this nice solution, but take
f(x)=1 if x is rational and f(x)=-1 if x is irrational. Then |f| is
always 1, so |f| is continuous everywhere. I did ask why f was not
continuous -- we need to negate a definition which begins, "for all
epsilon>0 there is delta>0 so that ..." and I asked what epsilon
would have no satisfactory delta, and I was told,
epsilon=1/2.
Section 5.2, #8 Suppose f and g are continuous from R to
R. If f(r)=g(r) for all r in Q (that is, for all
rational numbers r) then show that f(x)=g(x) for all x in R.
Solution: (following suggestions of Ms. Greenbaum and
Mr. Hedberg). Suppose we are given x in R. We know that
Q is dense in R. Therefore, for each n in N,
there is a rational number rn in the interval
(x-(1/n),x+(1/n)). Consider the sequence (rn). Since
x-(1/n)<rn<x+(1/n) and the sequence (1/n) converges
with limit=0, the Squeeze Theorem implies that (rn)
converges and its limit is x. Now the sequential characterization of
continuity implies that (f(rn)) must converge, with limit
equal to f(x) because f is continuous. But also (g(rn))
must converge, with limit equal to g(x) since g is continuous. Since g
and f are equal on rational numbers, the sequences are identical, and
therefore must have equal limits, so f(x)=g(x).
This is the solution we discussed in class, but could we possibly find
another one using the epsilon-delta characterization of continuity?
Here is one way, but using the sometimes cumbersome method of
contradiction. Suppose there is x in R with f(x) not equal to
g(x). Then take epsilon=(1/2)|f(x)-g(x)|, surely positive. Since f is
continuous at x, there is delta1>0 so that if
|x-anything|<delta1 then
|f(x)-f(anything)|<epsilon. Also there is delta2>0 so
that if |x-anything|<delta2 then
|g(x)-g(anything)|<epsilon. Now take
delta=min(delta1,delta2). Density of Q
implies that there is a rational number r in the interval
(x-delta,x+delta). For this r we know |f(r)-f(x)|<epsilon and
|g(r)-g(x)|<epsilon, so that (since f(r)=g(r) by hypothesis)
|g(x)-f(x)|=|(g(x)-g(r))-(f(r)-f(x))|<=|g(x)-g(r)|+|f(r)-f(x)|<(1/2)epsilon+(1/2)epsilon=epsilon. Therefore
epsilon<epsilon which is false. Whew! I think I like the sequence
proof more.
#8 and a half (Not from the text!) Can we find an example of
two functions f and g defined and continuous on all of R so
that the set S of numbers s where f(s)=g(s) is infinite but there are
x's in R where f(x) is not equal to g(x)?
Solution: Again, I have forgotten who suggested this. Take f(x)=0 for
x>=0 and f(x)=x for x<0, while g(x)=0 for x>=0 and g(x)=-x
for x<0. This works. Here S is the set [0,infinity).
#8 and three-quarters Can we find an example like the previous
one where the set of agreement of the two continuous functions is just
(0,infinity)?
Solution: No, we can't. Consider the sequence (1/n) which converges to
0 and which has all positive elements. Then f(1/n)=g(1/n) by
hypothesis, so the sequences (f(1/n)) and (g(1/n)) are identical. But
by the sequential characterization of continuity (used in the same way
as the proof of #8 above) these sequences converge to, respectively,
f(0) and g(0). Since the sequences are identical, the limits must
agree: f(0)-g(0).
#8 and seven-eights (?) Suppose that f and g are continuous on
all of R and that for x>0 we know
|f(x)-g(x)|<33sqrt(x). What can we say about f(0) and g(0)?
Answer, not solution: f(0) and g(0) must be equal (they don't both
have to be 0, though!). How can one "compare" the sequences (f(1/n))
and g(1/n)) in this case? Can they be "squeezed"?
Section 5.2, #12 A function f from R to R is said
to be additive if A f(x+y)=f(x)+f(y) for all x and y in
R. Prove that if f is continuous at one x0 in
R then f is continuous at every point of R.
Solution: I earnestly hoped that everyone would recognize the equation
above, since it is the central object of study in both Math 250 and
Math 350. I first deduced some properties of such f's:
1. If f is additive, then f(0)=0. Proof: Take y=0 in equation
A. Then the left-hand side is f(x+0)=f(x), and the right-hand
side is f(x)+f(0). Since f(x)=f(x)+f(0), we know from early in the
course that f(0) must be the "additive identity", so (by uniqueness of
such, for early in the course) f(0)=0.
2. If f is additive, then f(-x)=-f(x). Proof: Take y=-x in equation
A. Then the left-hand side is f(x+(-x))=f(0)=0 by the previous
observation. And the right-hand side is f(x)+f(-x). Therefore
0=f(x)+f(-x), so that f(-x) is the "additive inverse" of f(x), so (by
uniqueness of such, for early in the course) f(-x)=-f(x).
Before trying the solution of the problem I tried to consider an
example. One example suggested was f(x)=46x. This f is continuous, and
to get |f(x)-f(x0|<epsilon, there is delta>0 the
restriction |x-x0|<delta sufficient. This delta must be
epsilon/(46), and, in fact, the same delta works everywhere. So for
this problem we know that f is continuous at x0: given
epsilon>0, there is delta>0 so that if
|x-x0|<delta, then |f(x)-f(x0|<epsilon. I
bet that the same delta will be sufficient for y0. I thus
assert that if |y-y0|<delta, then
|f(y)-f(y0|<epsilon. Why is this true? I will relate y
and y0 to the x's. So the condition
|y-y0|<delta is the same as
|y-x0+x0-y0|<delta. Take
x=y+x0-y0. This inequality condition is then
exactly |x-x0|<delta. So we know by continuity of f at
x0 that |f(x)-f(x0)|<epsilon. Since
x=y+x0-y0,
f(x)=f(y+x0-y0)=f(y)+f(x0)-f(y0),
and
f(x)-f(x0)=f(y)+f(x0)-f(y0)-f(x0)=f(y)-f(y0). Therefore |f(y)-f(y0)|<epsilon, and we have verified the continuity of f at y0.
In fact, an additive function f, satisfying f(x+y)=f(x)+f(y),
actually has some further properties. For example,
f(2x)=f(x+x)=f(x)+f(x)=2f(x). It isn't hard to verify by math
induction that f(nx)=nf(x) for all x in R and n in
N. Also, if in the equation f(2x)=2f(x) we take x=(1/2)y we get
f(2·(1/2)y)=2f((1/2)y), so that f(y)=2f((1/2)y) and
(1/2)f(y)=f((1/2)y). Again we can verify that if m is in N,
(1/m)f(y)=f((1/m)y). Combining what we have observed, you may see that
we have proved the following result: if f is additive and if r is
rational, then f(rx)=rf(x) for all x in R. That is, f is
linear with respect to the rational numbers, Q. If
c=f(1), the f(r)=f(r·1)=rf(1)=cr. So, when restricted to the
rational numbers, an additive function must be multiplication by a
constant. Combine the results of problems 8 and 12: an additive
function which is continuous at one point must be multiplication by a
constant. This is the content of problem #13.
Weird example It is amazing and almost unbelievable that there
are additive functions which are not of this kind. To see this,
I need to quote some results from linear algebra. Q is a
field. Multiplication of real numbers by elements of Q
establishes that R is a vector space over Q. This is
very very weird to any sane human being, but it is correct. Of course,
students need to know what a vector space is to be sure it is correct,
but it is correct. Actually, the dimension of the vector space
is infinite (!). We can define linear transformations from the vector
space R to itself just by looking at what happens to a
basis. Here is part of a basis: 1 and sqrt(2). They cannot be linearly
dependent over Q because that would imply that sqrt(2) is
rational. So here I will define a "linear transformation": its value
on the basis element sqrt(2) is sqrt(2) (that is, multiplication by 1)
and its value on the basis element 1 is 0 (that is, multiplication by
0). Also its value on all other basis elements is 0. This "linear
transformation" is certainly additive. Can it be continuous? If it is
continuous at any point, then it is continuous at all points. And if
it is continuous at all points, then it multiplies all numbers by the
same number (problem #13) which this additive function does not. So
this function is not continuous at any point (!). Since f(0)=0,
given epsilon>0, there is no delta>0 so that
|x-0|<delta implies |f(x)-f(0)|=|f(x)| is less than
epsilon. Therefore there must be x's in the interval (-delta,delta)
with |f(x)|>epsilon. If one considers closely what this means for
the graph of such an f, it turns out that there are "dots" (points on
the graph) in a dense subset of the whole plane: dots inside every box
of the plane! This is very, very weird to me. Linear algebra is hard.
Today's quote was, of course, from W. Shakespeare (1564-1616). Here is
sonnet #18:
Shall I compare thee to a summer's day?
Thou art more lovely and more temperate:
Rough winds do shake the darling buds of May,
And summer's lease hath all too short a date:
Sometime too hot the eye of heaven shines,
And often is his gold complexion dimm'd,
And every fair from fair sometime declines,
By chance, or nature's changing course untrimm'd:
But thy eternal summer shall not fade,
Nor lose possession of that fair thou ow'st,
Nor shall death brag thou wander'st in his shade,
When in eternal lines to time thou grow'st,
So long as men can breathe, or eyes can see,
So long lives this, and this gives life to thee. ...
|
Just part of the Rutgers effort to educate the whole person.
|
| 4/3/2003
|
We discussed a few more "facts" about limits of functions.
I tried to find a limited converse to Fact 3. That is, if a function
is positive and it has a limit, must the limit also be positive?
Mr. Benson suggested the following example:
f(x)=x2 and c=0. Then for non-zero x, f(x) is certainly
positive, but the limit as x-->0 of f(x) is 0, which is not
positive.
This is similar to examples with sequences (the sequence
xn=1/n, for example).
Positivity is not inherited, but non-negativity is!
Fact 4: non-negativity is inherited by the limit
Suppose c is a cluster point of a set A, and f is defined on
A. Suppose also that the limit of f as x-->c for x in A exists and
is equal to L. If f(x)>=0, then L>=0.
Proof: If L<0, consider Fact 3 with the signs reversed. The values
of f must be negative for x close enough to c. But that contradicts
the assumption about f(x), so the initial hypothesis must be wrong,
and L must be non-negative.
Fact 5: squeeze theorem Suppose c is a cluster point of a set
A, and f and g and h are functions defined on A and, for x in A,
f(x)<=g(x)<=h(x). If the limit of f(x) as x-->c for x in A
exists, and the limit of h(x) as x-->c for x in A exists, and if these
two limits are equal, then the limit of g(x) as x-->c for x in A exists,
and equals the common value of the other two limits.
Proof: The suggestion was made by Mr. Tropeano, I think, that we
try to use the Squeeze Theorem for sequences. I agreed, and therefore
temporarily "adjourned" this proof while I prepared a sequential
equivalence for limits of functions.
Theorem (Cluster points and sequences) c is a cluster point of
a set A if and only if there is a sequence (xn) with the
following properties:
- Each xn is in A.
- None of the xn's are equal to c.
- (xn) converges and its limit is c.
Proof: First let's assume there is such a sequence and try to verify
that c is a cluster point of A. The definition tells us that, given
delta>0, there must be some element w of A satisfying
0<|w-c|<delta. Well, property 3 above assures us that there is
N(delta) so that |xn-c|<delta for n>=N(delta). So w
is one of those xn's, then certainly w is in A and w is not
equal to c by properties 1 and 2. Thus 0<|w-c|<delta, so we have
verified the definition of cluster point.
On the other hand, suppose c is a cluster point of A. Then take
delta=1/n. We know there must be an element of A (which I will call
xn!) satisfying 0<|xn-c|<delta. The first
inequality implies that xn is not c (so property 2 above is
true). And certainly each xn is in A. And we also know
(unrolling the second inequality) that
c-(1/n)<xn<c+(1/n). But the sequence version of the
squeeze theorem then implies that (xn) converges to c. And
we are done.
Theorem (Limits and sequential limits) Suppose that c is a
cluster point of a set A, and f is defined on A. Then the limit of
f(x) as x-->c is L if and only if for every sequence (xn)
with each xn in A and no xn equal to c and
which satisfies lim(xn)=c, then (f(xn))
converges and its limit is L.
Proof: The proof of this was essential done during our discussion of
the logical equivalence of PD#1 and PD#2.
A return to the proof of fact 5: we verify that the limit of g as x-->c
exists by checking on sequences, which is what the previous theorem
allows us to do. So if xn) is a sequence
with each xn in A and no xn equal to c, we know
by the hypotheses of fact 5 that
f(xn)<=g(xn)<=h(xn) for all
n. We also know (using one implication of the theorem above) that
both sequences (f(xn)) and (h(xn)) converge with
a common limit. But then the sequence version of the squeeze theorem
applies, and we know that (g(xn)) converges with the same
limit. But then the other implication of the theorem above
implies that the limit of the function g exists and is as desired.
Notice the logical "dance" back and forth which the theorem above
allows us to do. So there are lots of results about limits of
sequences which imply results about limits of functions relatively
easily.
Informally, we should remember from calculus that a function will be
continuous at a point if it is defined at the point, and if the limit
of the function at that point exists and equals the value of the
function there. This will be quite complicated if I continue using the
setting "c is a cluster point of A", so I won't. From now on (at least
for a while) f will be defined on an interval I. My examples of I
will be R (all of the reals) or [0,1] (a closed interval) or
(0,1) (an open interval). Here is a formal definition of continuity
for our course.
Definition (Continuity) Suppose f:I-->R. If c is an
element of I, then f is continuous at c if, given any
epsilon>0, there is delta>0 so that if |x-c|<delta with x in
I, then |f(x)-f(c)|<epsilon.
One can try to understand this in terms of input and output
tolerances, as I previously explained. One difference between this
definition and the definition of limit is that we just have
"|x-c|<delta" and not "0<|x-c|<delta". This is because we are
assuming that the limit of f at c is actually f(c): it is the "L" in
the previous definition of function limit.
I hope that most of the functions that we think are continuous indeed
will be continuous. Such functions include polynomials, rational
functions (away from where the denominators are 0, of course!) and
roots. Let's compute a few examples straight from the definition.
Example 1, a rational function (I did not do 1/x which I was
assured had been verified in the text!). Let us consider
f(x)=1/(x2+1). I claim that f is continuous for every
number c. Since this function is defined by an
algebraic formula, my first step is to try to get some algebraic
connection between |f(x)-f(c)| and |x-c|. This is easy, but a bit
tedious:
|f(x)-f(c)|=|1/(x2+1)-1/(c2+1)|=|x2-c2|/[(x2+1)(c2+1)]=|x-c|·|x+c|/[(x2+1)(c2+1)].
Wow! What a mess, or maybe there is too much information here. All we
really want is some inequality connecting |f(x)-f(c)| and |x-c|. We
can simplify and lose some information and still retain enough
"control" so that we can prove our desired result. Here is what I will
do: I will "forget" terms on the bottom, and the result will be an
overestimate. Therefore:
|f(x)-f(c)|<=|x-c|·|x+c|.
This looks familiar. We analyzed an example with a similar inequality
last time. So given epsilon>0, we can take delta equal to the
minimum of 1 and epsilon/(2|c|+1).
Example 2, sqrt(x) Here f(x)=sqrt(x) and the domain, I, is
[0,infinity). I claim that f is continuous for every number c in its
domain. Here again I want to find a connection between f(x)-f(c) and
x-c. Now |f(x)-f(c)|=|sqrt(x)-sqrt(c)|=|x-c|/|sqrt(x)+sqrt(c)|. Now
some observations about this equation: first,
|sqrt(x)+sqrt(c)| is the same as sqrt(x)+sqrt(c). Second, the equation
is undefined if both x and c are 0. So I will first analyze what
happens when c>0.
Now
|sqrt(x)-sqrt(c)|=|x-c|/(sqrt(x)+sqrt(c))<=(1/sqrt(c))|x-c|. The
purpose of the inequality is to simplify the connection between
|f(x)-f(c)| and |x-c| so that we can more easily manipulate them. Now
if we wish |sqrt(x)-sqrt(c)|<epsilon, I claim we can take
delta=sqrt(c)epsilon. Then since
|sqrt(x)-sqrt(c)|<=(1/sqrt(c))|x-c|, we know that
|sqrt(x)-sqrt(c)|<=(1/sqrt(c))(sqrt(c)epsilon)=epsilon as desired,
so f is continuous at c when c is not 0.
If c=0, we can be more "direct". |f(x)-f(c)|=sqrt(x). To get this less
than epsilon, just take |x-0|=x (x is always non-negative in the
domain of this f) less than delta=epsilon2. So we are done.
Then all of our work with sequences easily verifies the following
result:
Theorem (some algebra and continuity) If f and g are continuous
at c, so are f+g and f·g and (constant)f.
What about quotients? We need a little additional result.
Proposition (non-zero behavior of continuity)
If f is continuous at c and f(c) is not 0, then there is
delta>0 so that for all x in I (the domain of f) satisfying
|x-c|<delta, f(x) is not zero.
Proof: Take epsilon=|f(c)|, which is a positive number. Then the
definition of continuity assures us of a delta>0 so that if
|x-c|<delta, then |f(x)-f(c)|<delta. If f(x) were equal to 0,
the last inequality would become: |f(c)|<|f(c)| which is surely
false. So these f(x)'s cannot be 0.
Theorem (more algebra and continuity) If f and g are continuous
at c, and if f(c) is not 0, then 1/f and g/f are both defined in some
intervals containing c, and are continuous at c.
Proof: The vital part is making sure that f can't be 0 in the
interval, and that's what the preceding result insures.
The most important result about continuity is composition. The nicest
thing about the definition of continuity that we settled on is that it
makes the following result very easy to prove.
Theorem (Composition and continuity) Suppose f:I-->R and
g:J-->R, and we know that f(I) is a subset of J. Also suppose
that f is continuous at c and that g is continuous at f(c).
Then the composition of g with f is continuous at c.
Proof: To be given next time, but as I explained in class,
the model of input/output tolerances
guides how the proof will be given. (The output tolerance for f turns
out to be the input tolerance for g, I think.)
|
| 4/2/2003
| I wrote again the provisional definitions #1 and #2 from the
last lecture. I copied examples 1 through 4 from the last lecture.
I verified that example 1 (f(x)=x2) is continuous at c
exactly as the textbook does. That is, I wrote
x2-c2=(x-c)(x+c) and stated that I wanted to
"control" |x2-c2| with some restriction on
|x-c|. I first said that maybe we should ask
|x-c|<1. Ms. Guthrie verified that this implied
|x|<|c|+1 (you can see this by "unrolling" the inequality as we
have already done many times). Then |x-c|<=|x|+|c|<2|c|+1.
Therefore if we knew that
|x-c|<epsilon/(2|c|+1), we see
|x2-c2|=|x-c|·|x+c|<epsilon/(2|c|+1)·(2|c|+1)=epsilon.
So take delta to be the minimum of 1 and
epsilon/(2|c|+1). We need the 1 in order to get some bound on the x in
|x-c|.
Feeling silly, I did a similar thing for x5, which is more
than any sane person might do:
x5-c5=(x-c)(x4+x3c+x2c2+xc3+c4).
So if |x|<|c|+1, the multiplier of x-c can be bounded by an
expression not involving x (replace each x by |c|+1). This can
in turn be used to produce a delta given an epsilon. And so it goes
....
I then turned my attention to example 4, and tried to verify that the
f given there was not continuous at any irrational c. After drawing
a picture, Mr. Benson suggested that I try |c|/(327) as my epsilon. If c>0
I needed to show that given delta>0, the implication: if
|x-c|<delta then
|f(x)-f(c)|<|c|/(327) was false some x. If c>0,
I took x to be
a rational number in the open interval (c,c+delta) (possible since the
rationals are dense). Then f(x)=x, and f(c)=0
so that |f(x)-f(x)|=x>c>c/(327) certainly. If c<0, we could
take x rational in the interval (c-delta,c).
A similar analysis would show that f is not continuous at rational non-zero
c's.
Example 5 f(x)=1 if x=0 or if x=1, and f(x)=0 otherwise. This f
is not continuous at 0 and 1 and is continuous at all other x's.
Example 6 The Question of the day!
Find an example of f which is continuous at 0 and at 1, and is not
continuous at other numbers.
A number of correct answers were
given. One such answer is f(x)=x2-x for x rational and f(x)=0
for x irrational. There are many possible answers.
Then I tried to analyze the reasons the text is so "particular" about
domains in its discussion in chapter 4.
We probably want to have the following results true:
Algebraic if f and g are continuous, then f+g and f·g should
be continuous (this seems to be easy with the sequential definition [PD#1]).
As soon as we consider 1/f and f/g, however, we get into questions of
restricting domains.
Composition I think the following result is more subtle, but
should also be true: if f and g are both continuous, then f composed
with g should be continuous. One not so simple example of this has
g(x)=x2(x-1) and f(x)=sqrt(x). Here the "natural domain" of
f composed with g is {0} union [1,infinity). This is probably best
seen by looking at the graph of y=g(x) and seeing where it is
non-negative. But the graph of the composition is then one "isolated"
dot and a piece of a smooth curve. It really isn't clear if the
function "at" the isolated dot can or should be called continuous. We
think that continuity involves the behavior of a function "at" a point
compared to its behavior at nearby points. If there are no nearby
points, then restrictions on comparative behavior are pointless
(pun!).
An element c of a subset A of R is called an isolated
point of A if there is delta>0 so that the only point of A in
(c-delta,c+delta) is c.
c will be a cluster point (almost!) if it is not isolated. I made
mistakes in class on this, and I hope I won't make another here.
A real number c is a cluster point of A if given an delta>0,
there is an element a not equal to c in the interval
(c-delta,c+delta).
So cluster points can be in or not in the set.
Examples:
| Set | Cluster points of the set |
|---|
| (0,1) (open interval)
| [0,1] (closed interval)
|
| [0,1]
| [0,1]
|
| {0}
| empty set (no cluster points)
|
| N (natural numbers)
| empty set
|
| {1/n : n in N}
| {0}
|
| Q (rational numbers)
| R (all of the reals)
|
Another motivating example if the limit of ((f(x)-f(c))/(x-c)) as x-->c.
The "natural domain" of this quotient, well-known for being part of
the definition of the derivative, will always exclude c. So we must
be a bit more careful about limits.
Definition Suppose c is a cluster point of A, and f is defined
on A. Then we say that the limit as x-->c with x in A of f is L
if the following is correct:
given epsilon>0, there is delta>0 so that when
0<|x-c|<delta, then |f(x)-L|<epsilon.
Notice that there are several differences between what we wrote here
and Provisional Definition #2. First we have the additional layer of
"A" and "cluster point of A". In this course, A will almost always be
an interval (closed or open) or a finite union of intervals. Second,
and more interesting, is the additional restriction on x:
0<|x-c|. This is to take care of such situations as the definition
of derivative.
We can now merrily (?) prove a collection of facts.
Fact 1: uniqueness of limits Suppose c is a cluster point of a
set A, and f is defined on A. If L1 and L2 are
both limits of f at c, then L1=L2.
Proof: If L1 is not equal to L2, then take
epsilon=|L1-L2|/2, certainly a positive
number. Then there must be delta>0 so that when 0<|x-c|<delta
and x is in A, then |f(x)-L|<epsilon. Since c is a cluster point of
A, there is an x in A satisfying the restrictions
0<|x-c|<delta. So for this x we can write:
|L1-L2|=|(L1-f(x))-(f(x)-L2|<=(triangle ineq.)|L1-f(x)|+|f(x)-L2|
and each of these pieces is less than epsilon, so we have
2epsilon<2epsilon, which is not possible: contradiction.
Fact 2: limit existence implies local boundedness Suppose c is a cluster point of a set A, and f is defined on A.
Suppose also that the limit of f as x-->c for x in A exists.
Then f is bounded on A near c: there is delta>0 and M>0 so that
if x is in A intersect (c-delta,c+delta), then |f(x)|<M.
Proof: Take epsilon=1. There is some delta>0 so that if
0<|x-c|<delta and x is in A, then |f(x)-L|<1. But then
("unrolling" yet again!) for those x's, |f(x)|<|L|+1. So now we
could take M to be |L|+1 if c is not in A and max(|f(c)|,|L|+1)
if c is in A. This works.
Fact 3: functions locally inherit the signs of their limits
Suppose c is a cluster point of a set A, and f is defined on
A. Suppose also that the limit of f as x-->c for x in A exists. If L
is the limit and L is positive, then f is positive for x in A near c:
there is delta>0 so that if x is in A intersect (c-delta,c+delta)
with x not equal to c, then f(x)>0.
Proof: Take epsilon=L. Since L is positive, this is a "legal"
epsilon. Now if x is in A and 0<|x-c|<delta, we know
|f(x)-L|<L. Unrolling yet again, L-L<f(x)<L+L for those
x's. Since L-L=0, for those x's we see that f(x)>0.
Comment: Notice that if f(x)=37 for x not equal to 0 and f(0)=-5, then
(taking c=0 and L=37) we see that f(c) need not be positive, even if
the limit is positive. This is familiar example (I hope!) from
calculus.
Essentially I am "converting" sequence/limit facts to function/limit
facts. We could continue like this for a while. I will do a few more
tomorrow.
|
| 3/31/2003
|
The lecture primarily dealt with two provisional definitions of
continuity. They were "provisional" or temporary principally because I
wanted to delay thinking about the intricacies of domain questions
involving functions.
Provisional definition #1 A function f:R-->R is
said to be continuous at c if for all sequences (xn)
satisfying lim(xn)=c, then (f(xn)) converges,
and lim(f(xn))=f(c).
Provisional definition #2 A function f:R-->R is
said to be continuous at c if, given any epsilon>0, there is
a delta>0 so that if |x-c|<delta, then |f(x)-f(c)|<epsilon.
#2 is frequently briefly presented in calculus 1. There are various
interpretations of it.
The function as a machine If we think of f as a "black box" turning
inputs, x, into outputs, f(x), then what #2 means is the following: an
output error specification, epsilon, is given. We "want" the output to
be within epsilon of f(c). Can we control the inputs by a small
specification so that this occurs? The control over the inputs is
measured by |x-c|<delta.
The function via its graph Consider the graph of y=f(x). If we draw
horizontal lines y=f(c)+epsilon and y=f(c)-epsilon, then locally near
(c,f(c)) the graph is trapped between the two horizontal lines. When
we look for delta, we are asking if there is an interval centered
around c, an interval of the form (c-delta,c+delta) so that the
portion of the graph over the interval will lie within the horizontal
strip specified.
Perhaps one of these "explanations" helps to comprehend PD#2.
We then proved an essential chunk of the course: PD#1 and PD#2 are
logically equivalent. We had to prove two implications:
I If PD#1 is true, then PD#2 is true.
II If PD#1 is true, then PD#2 is true.
Both of these will be proved using the proof by contradiction
approach.
If PD#1 is true, then PD#2 is true.
Proof: We suppose that PD#1 is true, and that PD#2 is false. PD#2
false is the following statement:
there is epsilon>0 so that for
all delta>0, there exists x with |x-c|<delta and
|f(x)-f(c)|>=epsilon.
We used this to create a sequence. If n is in N, then
xn will be an x satisfying |x-c|<1/n and
|f(x)-f(c)|>=epsilon. Such xn's are guaranteed to exist
using the "PD#2 false" statement. Now consider the sequence
(xn). Since |xn-c|<1/n, we know
c-(1/n)<xn<c+(1/n). By the Squeeze Theorem, since
both c+(1/n) and c-(1/n) --> c, the sequence (xn) converges
and its limit is c. But what about (f(xn))? IF that sequence
converges to f(c), then we would need to know that
|f(xn)-f(c)|<epsilon for n large. But exactly
that statement is always false by the purple statement above. This is a contradiction to
PD#1, which is supposed to be true. Therefore, PD#1 implies PD#2.
If PD#2 is true, then PD#1 is true.
Proof: Now we need to write what "PD#1" is false means. Well, there
exists a sequence (xn) which converges to c such that
(f(xn) does not converge to f(c). We discussed this
last statement a bit. What does it, in turn, mean? It means: there
exists an epsilon>0 so that for all K in N there exists
n>=K with |f(xn)-f(c)|>=epsilon. That is, there is no
way (!) f(xn) eventually gets and stays "epsilon-close" to
f(c). Now to contradict PD#2: we will take the epsilon in PD#2 to be
the epsilon guaranteed by the failure (!) of sequential
convergence of (f(xn). That is, we will use this epsilon as
an output tolerance. Can there possibly be any input tolerance for
this epsilon? Suppose a delta>0 is given. We know that there is N
in N so that for n>=N, |xn-c|<delta. Therefore
the "infinite tail" after xN satisfies this candidate for
an input tolerance. But the failure of convergence says that there is
some n in this infinite tail which has
|f(xn)-f(c)|>=epsilon. That means we have not
controlled the output tolerance as we were supposed to! So we have
contradicted PD#2, and we are done.
I find this pair of proofs logically adequate but somehow lacking in
definiteness. I can only write or discuss this feeling approximately
and awkwardly, but somehow, we contradict these complexly quantified
statements in order to construct a "house of cards" which then, by
design, collapses at the end. To me this seems, emotionally, somewhat
unsatisfactory.
Example 1 f(x)=x2. We saw using PD#1 that this f was
continuous at every c in R. We should also check this
with PD#2.
Example 2 f(x)=1 if x=0 and f(x)=0 otherwise. We saw using PD#1
that f was not continuous at 0. If c is not 0, then f is continuous at
c. Here one can take delta=|c| (the delta will not depend on
epsilon). Then f(x)=0 for |x-c|<delta, since x can't be 0 (for if
x=0, then |x-c|=|c|<|c| which is false. So
|f(x)-f(c)|=|0-0|=0<epsilon for any positive epsilon.
Example 3 f(x)=1 if x is rational and f(x)=0 if x is
rational. This function is continuous nowhere. That is, if c is in
R, we can find an "output tolerance" epsilon which can be
satisfied by no input tolerance. Ms. Guthrie suggested that we
use epsilon=1. The proof naturally divides into two cases.
- c is rational. If c is rational, then f(c)=1. Suppose
we try a proposed delta>0. Then the interval |x-c|<delta is
naturally the open interval (c-delta,c+delta). Since the irrationals
are dense, there must be an irrational number w in this interval. Then
f(w)=0. Therefore |w-c|<delta but |f(w)-f(c)|=|0-1|=1 and this
cannot be less than 1.
- c is irrational. If c is irrational, then f(c)=0. Suppose
we try a proposed delta>0. Then the interval |x-c|<delta is
naturally the open interval (c-delta,c+delta). Since the rationals
are dense, there must be an rational number w in this interval. Then
f(w)=1. Therefore |w-c|<delta but |f(w)-f(c)|=|1-0|=1 and this
cannot be less than 1.
We noted that we could have used any epsilon between 0 and 1 to make
this reasoning work.
Example 4 f(x)=x if x is rational and f(x)=0 if x is
irrational. This function is continuous only at 0. Indeed, we verify
PD#2 at 0: given epsilon>0, take delta=epsilon. Then f(0)=0, and we
must show: if |x-0|<epsilon, then |f(x)-f(0)|<epsilon. There are
two cases: if x is rational, then f(x)=x, so |x-0|<epsilon
certainly implies |f(x)-0|=|x-0|<epsilon; if x is irrational, then
f(x)=0, so |x-0|<epsilon certainly implies
|f(x)-0|=|0-0|<epsilon. Now we wanted to show that f is not
continuous at c which was not 0. If we want to show that PD#2 is not
true, we need to find one epsilon for which no delta will
serve. The suggestion to take epsilon=|c| was made. I think this is
inspired partially by example 3 and even example 2. I first looked at
two specific c's to check the logic.
c=1 Here f(c)=1, and
epsilon=1. If there is delta>:0 with |x-1|<delta with
|f(x)-1|<1 necessarily, then we could take x irrational in the
interval |x-1|<delta (possible since irrationals are dense). Then
for this x, f(x)=0. And the statement |f(x)-1|<1 becomes |0-1|<1
which is false.
c=sqrt(2) This c is irrational, so f(c)=0. But we will try
epsilon=sqrt(2). Now given delta>0 we want to find x satisfying
|x-sqrt(2)|<delta and guaranteed not to have
|f(x)-f(sqrt(2))|<sqrt(2). Here we should certainly take x to be
rational. Then |f(x)-f(sqrt(2))|=|x|. But if |x-sqrt(2)|<delta why
must |x|<sqrt(2) need to be false? In fact, it doesn't "need" to be
false. We could take delta=1, and actually x=1. Then
|1-sqrt(2)|<delta and |1|<sqrt(2). We've got to be a bit
more clever in this case. Take x to be a rational number "to the
right" of sqrt(2): that is, x should be a rational in the interval
(sqrt(2),sqrt(2)+delta). Then |x|>sqrt(2) and
|x-sqrt(2)|<delta. So we do have here what we need.
I'll try
to go over this next time.
Textbook problems due Thursday: 3.7: 8, 9 and 4.1: 2, 12.
Où sont les neiges
d'antan?
| |
Usually translated as: "Where are the snows of yesteryear?" This mournful
refrain of the 15th century French poet, François
Villon (1431-1463?) was correctly identified by Mr. LeDuc.
|
|
| 3/27/2003
|
Absolutely convergent series can be rearranged without changing their
"sums".
Theorem Suppose that
sumj=1infinityaj converges
absolutely. If sumj=1infinityaj
converges with sum L, then any rearrangement of the series,
sumj=1infinityaf(j) will converge
and its sum will be L.
Proof: (A proof of this result appears in section 9.1.) Since
sumj=1infinityaj
converges with sum L, if we define
xn=sumj=1naj we know:
Given epsilon>0, there is K(epsilon) in N so that for
n>=K(epsilon), |xn-L|<epsilon. Now let J(epsilon) be
equal to the maximum of the numbers f(1),f(2),...,f(K(epsilon)). If we
define the partial sums for the "rearranged" series to be
yn=sumj=1naf(j) then when
n is at least J(epsilon), every yn has all the "pieces" of
xK(epsilon). So we could "separate" the yn sum
into
sumf(j) is one of [1,...,K(epsilon)]af(j)+sumthe other termsaf(j).
Now consider |yn-L|. We can use the triangle inequality to
estimate this:
|yn-L|<=|sumf(j) is one of [1,...,K(epsilon)]af(j)-L|+|sumthe other termsaf(j)|.
The first term is less than epsilon because of the specification of
K(epsilon). As for the second term, a different strategy is
needed.
|sumthe other termsaf(j)|<=(Triangle!)sumthe other terms|af(j)|.
Note that each of these |af(j)| is "far out": at least more
than K(epsilon).
Please note that we have not used part of the hypothesis yet, that the
series converges absolutely. So let's use it now. We can label the
partial sums of this series
zn=sumj=1n|aj|. Since
(zn) converges, it must be a Cauchy sequence (here is
that fact again!). Therefore, given epsilon>0, there is
W(epsilon) in N so that for n>m>W(epsilon),
|zn-zm|<epsilon. But each zstuff
is a sum of a bigger chunk of a series with non-negative terms, so
that we now know
sumj=m+1M|aj|<epsilon. In fact,
every finite "chunk" of this series summed up (if you have indices at
least W(epsilon)) will be less than epsilon. In fact, any
finite sum of such terms can be "embedded" into a (maybe larger) sum
of successive terms, so that any such finite sum is less than epsilon,
provided that the indices are all at least W(epsilon). This gives us a
way to control the other terms, the ones in purple above.
In fact, let's take the maximum of both W(epsilon) and K(epsilon) for
the number needed. Then the sum in purple above will be less than
epsilon, and we have estimated |yn-L| by 2epsilon, which is
good enough to me (you can rewrite the proof starting with epsilon/2
if you wish to end up with epsilon).
This theorem helps those new to series from making mistakes. That's
because many if not most of the series these people encounter are
power series,
sumj=1infinityajxj.
Power series have intervals of convergence. Outside these intervals,
the series diverges. Inside these intervals, the series converges
absolutely, so any sort of rearrangement leaves convergence and
the specific sum unchanged. However, Fourier series and series
derived from wavelets typically do not have such behavior, and
so more care is needed to deal with them. Both Fourier series and
especially series derived from wavelets are used in "real life". In
particular, I believe that a few years ago the FBI fingerprint files
were converted to storage based on wavelets.
I further challenged the class to something very specific. If one
believes in the Cauchy criterion, then it should be possible, perhaps
even easily possible, to create a list of infinitely many positive
numbers so that the sum of any finite subset of them is less than
.0001 (1/(10,000)). After some effort, we did create such a "list":
the nth number (for n in N) would be, perhaps,
1/[(10,001)2n]. Since we know that the sum of
1/2n as n goes from 1 to infinity is 1, our example is
complete.
Onward to CALCULUS!
What do we know about continuity, and what can it be used for?
Most nice functions (functions defined by simple formulas) are
continuous, or, at least, are continuous most places. sine, cosine,
polynomials, rational functions, logs, exponentials. You can add,
subtract, etc. and compose such functions to get further continuous
functions.
So graphs of such functions are unbroken: important in curve sketching
and root finding.
And areas "underneath" such curves are defined and maybe computable
or approximable (the definite integral "exists").
If a function models some sort of physical "process", then we can
think of x as input and f(x) as output. f's continuity is roughly
reflected in the fact that small changes in input (x) should imply
small changes in output (f(x)).
Here is a candidate for a Math 311 definition of continuity. I warn
you that it is different from what's at the beginning of chapter 4. So
please let us agree that it is only a preliminary definition of
continuity. Also, in order to avoid annoying technicalities at the
beginning, I will assume that the function f is defined
everywhere and not worry for now about domain questions. We
will need to modify this definition a bit later.
Preliminary definition A function f:R-->R is
said to be continuous at c if for all sequences (xn)
satisfying lim(xn)=c, then (f(xn) converges,
and lim(f(xn)=f(c).
Example 1 Suppose f(x)=x2. Then f is continuous at
every c in R. We can prove this: if (xn) is a
sequence which converges to c, then (theorem about limits and
arithmetic) ((xn)2) must also converge, and its
limit will be c2. So we have shown that (f(xn)
converges, and lim(f(xn)=f(c).
Example sqrt(2) "Jump," said Toad. "No, no, I
won't," said Frog.
Example 2 We define this f piecewise. f(x) will be 1 if x=0 and
will be 0 if x is not equal to 0. Note that the quantifier specifying
the sequences in the
preliminary definition above is universal: "all". That means to
show that f is not continuous at 0, it is sufficient to exhibit
one sequence (xn) which converges to 0 for which the
sequence (f(xn) does not converge to f(0)=1. So the
suggestion was take xn=1/n. Certainly this (xn)
converges to 0, but f(xn)=0, and the sequence (0) does not
converge to 1.
My next "job" will be to contrast this preliminary definition of
continuity with the one given in the text. I will also need to deal
with the complexities which occur when domain problems are included.
Please begin reading chapter 4. If you know a bit about
probability, this paper about random harmonic series may be
interesting to you.
|
| 3/26/2003
| We discussed infinite series. This material is somewhat
contained in sections 3.7 and 9.1 of the text. This is basic material
about infinite series, but we will also cover material which is not in
the text.
Definition The infinite series
sumj=1infinityaj
converges if the sequence of partial sums
xn=sumj=1naj converges. If
L is the limit of
(xn), L is called the sum of the infinite series. You will
see that it is very important to think only about this
definition, and not to get "distracted" by the idea of "adding up
infinitely many numbers". This is rather different.
Theorem If sumj=1infinityaj
converges, then
the sequence (an) itself must converge to 0.
Comment: in some calculus books this is called the nth term
test.
Proof: We know that (xn) converges to L. Then also
(xn-1) converges (only tails matter!) to the same limit,
L. But the difference of convergent series converges to the difference
of the limits: (xn-xn-1) converges to
L-L=0. Since xn=sumj=1ncj
and xn-1=sumj=1n-1cj, the
difference xn-xn-1=an, and we have
the conclusion we wanted.
The converse is false. That is, we can get series
sumj=1infinityaj which do not
converge, but where lim(aj)=0. The best-known example is
probably the harmonic series:
sumj=1infinity1/j, which diverges, but whose
individual terms -->0.
But signs (+/-) can matter. The alternating harmonic series,
sumj=1infinity(-1)j+1/j,
converges. This is a simple consequence of the alternating series
test. So there's another definition.
Definition The series
sumj=1infinityaj converges
absolutely if sumj=1infinity|aj|
converges.
Comment: Absolute convergence is a little bit easier to study, because
when all of the terms are non-negative, the sequence of partial sums
is monotone increasing, and the "theory" of such sequences is fairly
simple (indeed, "dichotomous" -- either one thing [partial sums
bounded and convergent] or another [partial sums unbounded and
divergent]).
Theorem If sumj=1infinityaj
converges absolutely, then it must converge.
Proof: Let (xn) be the sequence of partial sums of
sumj=1infinityaj, and let
(yn) be the sequence of partial sums of
sumj=1infinity|aj|.
The logic of this proof is particularly interesting. We
will use strongly the equivalence of convergence of a sequence and the
Cauchy criterion: we proved an "if and only if" statement and we will
use both implications!
Since (xn) converges, (xn) is Cauchy. Therefore,
given epsilon>0, there is Z(epsilon) in N so that if
n>m>=Z(epsilon), |yn-ym|<epsilon. Now
there is a trick. Here we know what the ystuff is:
each is a partial sum. So
|yn-ym|=sumj=m+1n|aj|.
The triangle inequality states that
|sumj=m+1naj|<=
sumj=m+1n|aj|. (Note how the
absolute value signs have changed!). But
|xn-xm|=|sumj=m+1naj|,
so that
|xn-xm|<=|yn-ym|<epsilon.
This means that the sequence (xn) satisfies the Cauchy
criterion (!) and therefore it must also converge. So we are done.
Many examples in calc 2 use this result. For instance, since we know
that sumj=1infinity1/2j converges, we
therefore know that
sumj=1infinity(sin(j^3+5j))/2j
converges, since |sin(j^3+5j)|<=1.
Of course, convergence does not imply absolute convergence. The
alternating harmonic series, mentioned above, shows this. And indeed
we have the following additional definition.
Definition The infinite series
sumj=1infinityaj is conditionally
convergent if it converges but
sumj=1infinity|aj| does
not.
Example: The alternating harmonic series converges conditionally.
Let us "discuss" such conditionally convergent series. For the
remainder of this lecture,
sumj=1infinityaj will be a
conditionally convergent series. So
- sumj=1infinityaj converges.
- sumj=1infinity|aj| diverges.
We can divide up the positive integers, N, into two disjoint
subsets, S and T. Here S will denote those j's for which aj
is non-negative, and T is those j's with aj<0. The sets
S and T are disjoint, of course. But how big are they? We analyzed
this slowly. I first asked if, say, T could be empty. Well, if T were
empty, then all the elements of the series would be non-negative, and
|aj|=aj. Then it would be impossible for the
assumptions numbered above to be true. If S were empty, then the
absolute values would all be (-1) times the aj. The series
would be constant multiples of each other. So it would be impossible
for one of the series to converge while the other diverged. What if,
say, T were finite? Then only finitely many terms would be
negative. And since "only tails matter", eventually the series
|aj| and aj would coincide. So again, both the
series would have to {con|di}verge together. And similarly, T would
have to be infinite also.
 Now we know that N is "divided" into two infinite sets, and
the conditionally convergent series has infinitely many positive and
infinitely many negative terms. In fact, let's look at say the
positive terms. If the sum of the positive terms converges, then we
could subtract (cancel out!) the positive terms from the convergent
series sumj=1infinityaj. Since the
difference of two convergent series must also converge (theorems on
arithmetic and limits) we then see that the series of negative terms
must converge. But then since the series of |aj|'s is the
difference of the positive terms and the negative terms (not
profound: it is always true that |x|=x for x>=0 and |x|=-x for
x<0), it would follow that the sum of the absolute values would
converge! But this is a contradiction. So if you can follow this chain
of hypothetical reasoning we have seen that the sum of the positive
terms must be divergent (and that means that the partial sums must be
unbounded above). Similar reasoning establishes that the sum of the
negative terms must be unbounded below.
Now we know that N is "divided" into two infinite sets, and
the conditionally convergent series has infinitely many positive and
infinitely many negative terms. In fact, let's look at say the
positive terms. If the sum of the positive terms converges, then we
could subtract (cancel out!) the positive terms from the convergent
series sumj=1infinityaj. Since the
difference of two convergent series must also converge (theorems on
arithmetic and limits) we then see that the series of negative terms
must converge. But then since the series of |aj|'s is the
difference of the positive terms and the negative terms (not
profound: it is always true that |x|=x for x>=0 and |x|=-x for
x<0), it would follow that the sum of the absolute values would
converge! But this is a contradiction. So if you can follow this chain
of hypothetical reasoning we have seen that the sum of the positive
terms must be divergent (and that means that the partial sums must be
unbounded above). Similar reasoning establishes that the sum of the
negative terms must be unbounded below.
Now here is a wonderful
result, which is totally unintuitive to me. Ooops: just as I did in
class, I forgot to state a definition first.
Definition Suppose
sumj=1infinityaj is a series. Then a
rearrangement of this series is gotten by specifying a
bijection f:N-->N to obtain an infinite series
sumj=1infinityaf(j).
Comment: the bijection establishes that every term of aj
appears exactly once in the rearranged series.
Riemann's Rearrangement Theorem Suppose
sumj=1infinityaj converges
conditionally. If c is a real number, then there exists a
rearrangement so that
sumj=1infinityaf(j) converges, and
the limit of the rearranged series is c.
Comment: this really means that commutativity and associativity are
FALSE for general "infinite sums". So they are not really sums, but
rather some very very special kinds of limits.
Proof: Since sumj=1infinityaj
converges
conditionally, we know several facts:
- lim(aj)=0. Therefore, given epsilon>0, there
are only a finite number of aj's with
|aj|>=epsilon. In fact, there are at most N(epsilon)
such, if N(epsilon) is the integer guaranteed by the definition of
convergence.
- The sum of the positive numbers in the series is unbounded above:
for any number, we can find chunks of the positive elements of the
series which add up to something greater than the number.
- The sum of the negative numbers in the series is unbounded below:
for any number, we can find chunks of the negative elements of the
series which add up to something less than the number.
These are the ingredients which are needed for the proof.
First just start with a1, and assume for simplicity that
a1<c. Now add on terms from the "positive" subseries,
the one associated with S. Since the partial sums of this subseries
are unbounded above, we can add on "enough" to make a partial sum
larger than c. We need to reverse things, so add on terms from the
subseries associated with T until the partial sum is less than
c. Reverse again, using terms from S. Etc. Each time we reverse, we
use up at least one term from the subseries. Eventually, of course (by
the time we have done N(epsilon) up and downs, we have used all the
terms of the series which are larger than epsilon in absolute
value. So when we go "past" c in either direction, we will stop after
at most one more term, and so all of these partial sums are N(epsilon
up and downs will lie in the interval [c-epsilon,c+epsilon]. But that
is exactly verifying the definition of convergence for the sequence of
partial sums of this rearranged series!
I could not "believe" this result when I first saw it. I needed to
think about it quite a bit. Notice that if the rearrangement
bijection, f, only changes finitely many of the integers (that is, if
there is N so that f(n)=n for n>=N), then the {con|di}vergence of
the rearranged series and its sum do not change, because the partial
sums of the original series and the rearranged series are identical
after the first N such. Again, "only tails matter". The preceding
theorem shows that we shouldn't think of infinite series as sums. They
are just a different sort of creature. As I mentioned in class, if we
called sumj=1infinityaj something
totally new and ludicrous, like GLUMP(aj), we then would
have less "intuition" or preconceptions (prejudices!) to get rid
of. If someone told us that GLUMP(aj) and
GLUMP(af(j)) were not necessarily the same, well, then, I
guess they would not necessarily be the same: not a tragedy.
I'll do just a bit more on series tomorrow before starting chapter 4.
|
| 3/24/2003
|
Sequences which satisfy the Cauchy criterion and convergent sequences
are the same sequences! I tried to give "real" examples illustrating
the usefulness of this "coincidence".
I began by restating the definition of convergence, and the definition
of the Cauchy criterion. Of course, the Cauchy criterion does
not include knowledge of the limit. But we can state the
following: since we know that given epsilon>0, there is M(epsilon) in N
so that when n and m are at least M(epsilon), then
|xn-xm|<epsilon, we do know that all
xn's with n>=M(epsilon) satisfy
|xn-xM(epsilon)|<epsilon. But that means that those
xn's lie inside the interval
(xM(epsilon)-epsilon,xM(epsilon)+epsilon). The infinite tail of
the sequence is in that open interval. Then the work we have done on
limits and inequalities will tell us that the limit must be in the
closed interval
[xM(epsilon)-epsilon,xM(epsilon)+epsilon].
With that behind us, I introduced my example: an infinite series. So I
want to analyze the sum as n goes from 1 to infinity of
+/-(1/nn) where the sign is given in the following weird
way: one + sign, then two - signs, then three + signs, then four -
signs, etc. So the series begins:
1-1/4-1/27+1/256+1/3125+1/46656 etc.
I ask the following questions: - Does this series
converge?
- If it does, what can one say about its sum?
I think it does converge. And the real reason I think it
converges is that the terms -->0 so fast.
Much of what we're going to do here could also be done in a second
semester calc course, but I want to do it from the viewpoint of Math
311. The basic idea is to compare this series with a more familiar
series. And the most familiar series are probably geometric series.
Consider the series 1+1/2+1/4+1/8+...+1/2n-1+... where
an=1/2n-1. Does this series converge? Well, we
need to reach back to second semester calculus. We say that the series
converges if the sequence of partial sums converges. Here the sequence
of partial sums is defined by
xn=sumj=1n(1/2j-1). The
nicest thing about geometric series is that there are simple formulas
for their partial sums. Here we can multiply xn by 1/2 and
subtract from the defining sum for xn. Lots of things
cancel out, and we have
xn-(1/2)xn=1-1/2n, so that
xn=2-1/2n-1.
Now let's go back to 311. The sequence (xn) is obtained by
adding positive numbers. So it is a monotone increasing sequence. For
such sequences, there is a dichotomy (the online dictionary
says that this means "a division into two, esp. a sharply defined
one.") Either a monotone increasing sequence is bounded and converges,
or it is unbounded and diverges. But we have a nice formula for
xn, so we know that the terms are all bounded above by
2. And, indeed, since we know that 1/2n-->0 we even know
that 2 is the limit of this sequence.
The Cauchy criterion can be applied to this sequence. That is, given
epsilon>0, there is M(epsilon) in N so that for n and m at least M(epsilon),
|xn-xM(epsilon)|<epsilon. Suppose m>n. We will
actually be able to "compute" M(epsilon) in this case. Here we know that
xn=sumj=1n(1/2j-1) and
xm=sumj=1m(1/2j-1) so
that
xm-xn=sumj=n+1m(1/2j-1).
We can multiply by 1/2 and subtract, just as we did above. The result
gets us a nice formula:
xm-xn=(1/2n)(1-(1/2m-n)
(remember that m>n). Therefore we can simplify (get rid of one
variable on the right-hand side, and give up strict equality):
|xm-xn|<=(1/2n). Since
(xn) converges, it must be a Cauchy sequence. What is
M(.001)? Apparently we need (1/2n)<(1/1,000), which will
occur when n=10. So M(.001) is 10 (or, actually, any integer larger
than 10).
Now let's go back to the original weird sequence. Let me call
bn the nth term, which is 1/nn with a
weird sign. And let me call yn, the nth partial
sum of the bn's. What can we say about the sequence
(yn)? It is certainly not monotone, because of the +
and - signs distributed among the bn's. But can we compare
the two sequences? Since |bn|=1/nn, and we know
that 1/nn<=1/2n-1 (we verified this for n=1
and n=2, and I bet it is true for all n>=2), we know that
|ym-yn|=|sumj=n+1m{weird sign}1/jj|,
and the triangle inequality breaks this up to
<=sumj=n+1m1/jj<=
sumj=n+1m1/2j-1=|xm-xn|.
But now if n and m are at least M(epsilon) for the (xn)
sequence, we know |xm-xn|<epsilon. This implies
that |ym-yn|<epsilon also for those n and
m's. Therefore, (yn) is also a Cauchy sequence. And further
therefore (!), we now know that (yn) must converge. Even
more, we know that y11, which we could compute, would be
within .001 of the sum of the whole series.
So this strategy allows us to conclude that a certain infinite series
converges, and to get a good approximation of the sum of the
series.
Now let me write down some of the theory we have actually in effect
proved:
Theorem Suppose (xn) and (yn) are
sequences. If we know that there is some positive constant C so
|ym-yn|<=C|xm-xn| and
if we know that (xn) converges, then (yn)
converges.
"Proof": We essentially verified this for C=1 above. Since
(xn) converges, it satisfies the Cauchy criterion, and then
if we use M(epsilon/C) for (xn) we'll get the Cauchy criterion
for (yn).
Theorem If an infinite series converges absolutely, then
it converges.
"Proof": This statement should be familiar from second semester
calculus. Here the yn's will be the sum of the absolute
values of the series, and C=1 in the previous result.
I used some Maple instructions to compute the sum of the weird series
I started out with. Here are the Maple instructions, and the result.
t:=(a,b)->evalf(sum(1/j^j,j=a..b)); Defines a function
to add up a chunk of 1/jj from a to b.
t(1,1)-t(2,3)+t(4,6)-t(7,10)+t(11,15)-t(16,21)+t(22,28);
0.7172093698
And since Maple told me that 2-28 is less than
10-8 this result is accurate to at least 8 decimal
places.
I wanted to do another example, but I sort of ran out of time. I
wanted to show an "iterative" way to get a root of a polynomial. This
is discussed in section 3.5, pages 84 and 85.
|
| 3/13/2003
| We began the lecture by contemplating a page of a final exam
I gave in 1996 to a second semester calculus class (o.k.: now I'll
admit it. It was a small class, an honors second semester calc course,
and the students were quite good). The worksheet had four true/false
statements. We analyzed those statements.
For a): the sequence (ak) defined by ak=(-1)k has the
property that (|ak|) converges, but (ak) does not. So the assertion in
a) is false.
For b): this is a more subtle question. If L is not zero, and
if (ak) and (bk) both converge to L, then ("eventually", which means,
there exists K in N so that ak is not 0 for k>=K) the sequence
(ak/bk) converges to 1. If L=0, then (using the examples 1/k and
1/k2) we can get sequences (ak/bk) which maybe diverge or
which converge to 0. We can even get a sequence (use 1/k and 37/k)
which converges to 37. So the statement as given is false.
For c): the statement is true. Here I tried to give a proof. Since
(ak) converges (say to L) we know that given epsilon>0, there is K(epsilon)
in N so that for k>=K(epsilon), |ak-L|<epsilon. Now we need to create
M(epsilon) so that for n>=M(epsilon), |(ak+1-ak)-0|<epsilon. Here
we can take M(epsilon)=K(epsilon/2) (in class we used L(epsilon/100) which also
works but this answer is more traditional). Then if k>=M(epsilon), we
know that |ak+1-L|<epsilon/2 and |ak-L|<epsilon/2. Now use
the triangle inequality:
|(ak+1-ak)-0|<=|(ak+1-L)+(L-ak)|<=|ak+1-L|+|L-ak|<epsilon/2+epsilon/2=epsilon.
So we are done: we have used the K(epsilon) "machine" to "build" an M(epsilon)
"machine".
For d): this is probably the most subtle question. We have in fact
addressed it before. If we consider the sequence
ak=sumj=1k1/j then the logic behind the Integral
Test of calculus allows us to underestimate ak by ln(k) or ln(k+1)
(see the diary entry for 3/5/2003). So in fact this sequence is
unbounded. Mr. Hedberg suggested a sequence from a homework problem:
ak=sqrt(k). The problem showed that
(ak+1-ak) converged to 0 when ak=sqrt(k). This example is
more in the spirit of Math 311: the integral test is way more
advanced than what we can use now.
I altered the example. I asked: suppose that you know that both
(ak+1-ak) and (ak+2-ak) converge to
0. Can you conclude that (ak) converges? And, indeed, the same example
(ak=sqrt(k)) shows that the answer is "No." Even more, we can add any
finite number of such requirements and still the answer will be
"No". So getting any criterion for convergence which doesn't seem to
depend either on already knowing a limit or on some special structure
(such as monotonicity) seems difficult, which makes the Cauchy
criterion yet more amazing.
I will call this CC for Cauchy criterion:
A sequence (xn) has the following property: given epsilon>0, there is
W(epsilon) in N so that if both n and m are >=W(epsilon), then
|xn-xm|<epsilon.
We will further contrast it with the following, which I will
temporarily label V (it is the definition of
convergence):
A sequence (xn) has the following property: there is a number L so
that for any epsilon>0, there is K(epsilon) in N so that if
n>=K(epsilon), then |xn-L|<epsilon.
The purpose of the remainder of this class is to verify that CC
and V are equivalent. CC is used a great deal in
practice and in theory, because it does not need a specific L to be
designated, but guarantees convergence. I'll try to show in classes
after vacation how CC is used. First, as always in Math 311,
the proofs:
Theorem V implies CC.
Proof: If we have K(epsilon), I need to show you how to "construct"
W(epsilon). And this implication is fairly easy: W(epsilon)=K(epsilon/2). Why does
everything work? Well, if both n and m are at least the specified
W(epsilon), then: |xn-xm|=|xn+0-xm|=|xn-L+L-xm|<=|xn-L|+|L-xm| using
the triangle inequality. But since n and m are both at least K(epsilon/2)
each of the terms |xn-L| and |L-xm| are less than epsilon/2, and the sum
is certainly less than epsilon.
That wasn't hard. Now for the other way. We will sneak up (?) on the
result.
Proposition If (xn) has CC, then the sequence is
bounded.
Proof: Well take some explicit epsilon, say, epsilon=40. Then W(40) is some
fixed positive integer, and every xn with n>=K(40) satisfies
|xn-xK(40)|<40. But we can "unroll" this inequality so
that xK(40)-40<xn<xK(40)+40. Therefore
xK(40)+40 is an upper bound for the infinite tail of the
series which begins with the K(40)th term. And I can "take
care" of the earlier ones, only a finite number (!!) with a simple (?)
"max". So, here it is: I claim that the max of this finite set:
{xK(40)+40,x1,x2,x3,...,xK(40)-1}
is an upper bound of all of the elements of the sequence. And a good
lower bound is the minimum of the set
{xK(40)-40,x1,x2,x3,...,xK(40)-1}.
I think we are done.
Proposition If (xn) has CC, then (xn) has some
convergent subsequence.
Proof: Since we know the sequence must be bounded by the previous
result, then the Bolzano-Weierstrass Theorem applies. There must be a
convergent subsequence.
Proposition If (xn) has CC and if (xn) has some
convergent subsequence, then (xn) converges.
Comment And once we prove this, we will be done with "If CC
then V."
Proof: What do we know? We know two things:
- (xn) has CC: so given epsilon>0, there is W(epsilon) in N
so that if n and m are at least W(epsilon), |xn-xm|<epsilon.
- (xn) has a convergent subsequence: let's suppose its limit is L. So for each k in N, there is
an nk in N with nk+1>nk for all
k (so always nk>=k) so that if epsilon>0 is given, then
there is M(epsilon) in N so that for k>=M(epsilon),
|xnk-L|<epsilon.
From all this we need to verify:-
If epsilon>0 is given, there is K(epsilon) in N so that if n>K(epsilon),
then |xn-L|<epsilon.
We discussed this at length in class. I tried to show during this
discussion that these proofs (at least when I do them!) don't come out
perfectly and immediately. I don't think I can reproduce what I
consider the instructive dynamics of this discussion. Instead, all I
can do right now is freeze us into a possible answer for creating
K(epsilon): K(epsilon) should be equal to the following integer:
nmax(W(epsilon/2),M(epsilon/2)). Now we need to verify this
claim:
Take n>=K(epsilon) as defined above. Look at
|xn-L|=|xn-xnmax(W(epsilon/2),M(epsilon/2))+xnmax(W(epsilon/2),M(epsilon/2))-L|<|xn-xnmax(W(epsilon/2),M(epsilon/2))|+|xnmax(W(epsilon/2),M(epsilon/2))-L|.
Now look at each piece.
- |xn-xnmax(W(epsilon/2),M(epsilon/2))| Since (xn)
is a Cauchy sequence, and n>=nmax(W(epsilon/2),M(epsilon/2)), we
know that n>=W(epsilon/2) (we just used the increasing nature of the
subsequence numbering!) and also
nmax(W(epsilon/2),M(epsilon/2))>=W(epsilon/2). But two elements of
the sequence which are "W(epsilon/2)" far along must differ by less than
epsilon/2: that is exactly how the W-machine implements the Cauchy
criterion.
- |xnmax(W(epsilon/2),M(epsilon/2))-L| The sequence
element xnmax(W(epsilon/2),M(epsilon/2)) is a member of the
subsequence, exactly because it is
xnsomething!. And look, it is at least as "far
along" the subsequence as M(epsilon/2). But the M measures how close the
subsequential elements are to the limit, and for subsequential
elements at least as far along as M(epsilon/2), the difference will L is
less than epsilon/2.
So each piece is less than epsilon/2, and the sum is less than epsilon. And we
are done.
I tried diligently and perhaps (almost certainly!) unsuccessfully to
"motivate" this elaborate strategy in class. It is certainly
complicated. We have now proved a major theorem.
Theorem A sequence converges if and only if the sequence
satisfies the Cauchy condition.
We will use this a lot.
|
| 3/12/2003
|
I began by advising students that I would "cover" sections 3.1-3.5 of
chapter 3 and requesting that students read these sections. I hope
that I will finish this material and that soon after vacation I will
begin chapter 4. From now on, many of the results (theorems, examples,
etc.) will have increasingly familiar statements. Most students should
recall versions of the results from calculus. But in Math 311 I will
be principally interested, almost solely interested, in the
proofs of these statements. For example, the "Ratio Test" in
the text:
Suppose (xn) is a sequence of positive numbers, and that
lim(xn+1/xn) exists and is a number L. If
$L<1, then lim(xn) exists and is 0.
I won't prove this but it is a part of what students should know
(Theorem 3.2.11 of the text). One special case is interesting,
however, since the text's verification of the result uses several of
the concepts we've been looking at recently.
Example If 0<b<1, then the sequence defined by
xn=bn converges, and its limit is 0.
This
result should be familiar from calculus. A short proof using
mathematical induction verifies that the sequence (xn) is
monotone decreasing. Since all of the elements of the sequence are
positive, the sequence is bounded below by 0. But then by our previous
work on monotone sequences, this sequence converges. Let's call the
limit of the sequence, x. What is x? Since all of the xn's
are non-negative, x must be also. But here is a "trick" to verify what
we suspect x to be. Let yn=b2n. Then
(yn) is a subsequence of (xn):
yn=x2n. Therefore by what we learned about
subsequences last time, (yn) also converges, and its limit
is x, the same limit as (xn). But
yn=(xn)2, so using our results on the
arithmetic of convergent sequences, we know that the limit of
(yn) is the square of the limit of (xn). Since
they both have x as a limit, we know that x2=x. But all of
the xn's are less than 1, and the sequence is
decreasing. Therefore of the two roots of x2=x (0 and 1) we
know the limit can't be 1. It must be 0.
Here is one of the most important results of the course.
Bolzano-Weierstrass Theorem Suppose (xn) is a
sequence all of whose terms are in [a,b]. Then (xn) has a
convergent subsequence.
Proof: The proof I tried to give of this
result is a bit different from what is in the book. But I wanted to
give a proof based on bisection. The structure of the proof involves
creating a sequence of "things" using an inductive procedure.
Base case My initial interval is [a,b]. My initial set,
S0, is the natural numbers, N. Now I will try to
create a new, smaller interval, and a new (sub)set of N. Here
is how: Define S0L to be the collection of
integers n in S0 for which xn is in the left
half of [a,b] (that is, xn is in [a,(a+b)/2]). And define
S0R to be the collection of integers n in
S0 for which xn is in the right half of [a,b]
(that is, xn is in [(a+b)/2,b]). Notice that S0
is the union of S0L and
S0R. (There may be n's in both sets, if
xn is actually equal to (a+b)/2: this will not affect the
discussion.) Since the infinite set S0 is a union of two
sets, at least one of those sets must be infinite. (If they are both
finite, then their union would be a finite set, which would be a
contradiction.) It is also true that both of the sets might be
infinite. In any case, I choose S1 to be one of these two
sets, and my choice is made so that S1 is infinite. Also I
choose I1 to be the subinterval corresponding to the choice
of S1 (if S0L is S1, then
I1 will be the left half interval, and if
S0R is S1, then I1 will be
the right half interval). Now we have S1 and I1
with the length of I1 equal to (b-a)/21.
Inductive step Here we are given the following elaborate
ingredients: a subinterval In of [a,b] with the length of
In=(b-a)/2n, and an infinite subset
Sn of N so that if k is in Sn, then
xk is in In. (There will be lots of
indices to keep track of in this proof!) Now I divide In
into two equal halves, the left and right halves. I also create
SnL and Sn: these are two
subsets of Sn defined by: k is in SnL
if xk is in the left half of In and k is
in SnR if xk is in the right
half of Inn is the union of these two
subsets, at least one of them must be infinite. So Sn+1
will be one of the subsets (either the "left" or the "right" one)
which is infinite. And In+1 will be the associated half
interval. So I have done the inductive "step".
What have we created? We have several "things": - A sequence of
intervals, the nth of which is
In=[an,bn], so that the length of
In is (b-a)/2n, and so that In+1 is a
subset of In. This is exactly the hypotheses of the Nested
Interval Theorem. We are "guaranteed" to have exactly one x which is
in all of the In's.
- We have a sequence of Sn's. Each of these is an
infinite subset of N. Each one is "smaller" than the one before:
well, exactly what I mean is that for each n in N, Sn+1
is a subset of Sn.
Now I will "construct" a convergent subsequence of (xn). Since each
Sn is a nonempty subset of N, each has a least element
("well-ordering"). I'd like the nth element of the
subsequence to be one which is in Sn (so the least element
would work) and one which is greater than the n-1st
element. I can do both of these (especially the latter one) because I
know that Sn is infinite, and infinite subsets of N obey
a version of the Archimedean property: there's always an element of
such a subset which is larger than any given real number. Notice that
this nth element of the subsequence must be in
In since its index is in Sn. Thus, since x is
also in In, we know that the distance between x and this
element is less than or equal to the length of In, which is
(b-a)/2n. Whew! I think I have done enough: created a
subsequence, shown that its distance to x-->0, and so the subsequence
converges. I think I proved the theorem.
Discussion I need to convince you of the claim that this
is an important theorem. But I also mention that lots of people
don't "like" it. They don't like it because it is non-constructive, it
is "ineffective": by that I mean that no mechanism is shown to create
an explicit subsequence which converges. Somehow one "knows" that
there are infinitely many points in one half of each interval,
etc. etc. I don't think human beings are too comfortable contemplating
infinity so directly. Humans tend to like things they can verify a
step at a time, and jumping to "Hey, half the interval has infinitely
many points" is quite a big jump. It is amusing, though, to look at
what follows: we will soon be able to "construct" sequences that
surely converge, and this will be, at least theoretically, a
consequence of the Bolzano-Weierstrass Theorem. The theorem applies to
any sequence which is bounded: no other condition is needed. Here is
the theorem again, stated simply: A bounded sequence has a
convergent subsequence.
Please note that K. Weierstrass is a professional ancestor of the
instructor of this course. The instructor's professional ancestors can be inspected.
In the fashion of Math 311, yet another definition:
Definition A sequence (xn) is a Cauchy sequence if
for all epsilon>0, there is K(epsilon) in N so that for n
and m >=K(epsilon), |xm-xn|<epsilon.
There are lots of quantifiers in this definition, which is somewhat
reminiscent of the definition of convergence. What does the definition
"say"? Well, let's try to particularize it. Suppose epsilon=46. And just
suppose that K(45)=400,000. Then, certainly, if n>=400,000,
|x400,000-xn|<46. We can "unroll" this inequality. It
means all the elements of the
sequence after the first 399,999 must be in the interval
(x400,000-46,x400,000+46). So in fact the
sequence must be bounded, because the "infinite tail" of the sequence
is caught in this interval and there are only finitely many (hey:
399,999 is just a finite number!) outside the interval. So we have
almost proved that
1 A Cauchy sequence is bounded.
Problem 11 of the first exam more or less proves the following:
2 If a subsequence of a Cauchy sequence converges, then the
whole sequence converges.
That's because problem 11 says that the convergent sequence sort of
"drags" along the other sequence, since they have to stay close. And
the elements of a Cauchy sequence sort of have to stay close to each
other. Therefore we almost have:
3 Any Cauchy sequence converges.
This is because any Cauchy sequence is bounded, so Bolzano-Weierstrass
applies, so there's a convergent subsequence, so the sequence
converges. So ... and it isn't too hard to verify that convergent
sequences are Cauchy. Sigh. What we have is a necessary and sufficient
description of a convergent sequence without mentioning the
limit of the sequence. And since most of the sequences I know sort of
naturally "occur" without specifying limits, this description is very
useful. It is an "internal" rather than "external" description of
convergence. All this, maybe, will be made clear tomorrow.
|
| 3/10/2003
|
Since I left my notes at home, I had to "wing it" a bit, and
spontaneous talk about the material. I went over 3.3, monotone
sequences, more abstractly. In particular, I proved the following
result:
Theorem Suppose (xn) is a monotone increasing sequence. Then:
(xn) converges if and only if the set {xn : n in N} is bounded
above. If (xn) converges, then its limit is the sup of the set {xn : n
in N}.
Comment: A similar result is true for decreasing sequences, with the
word "above" replaced by "below" and "sup" replaced by "inf".
Proof: If (xn) converges, then we saw already that it must be
bounded. Let me try the converse. Suppose (xn) is bounded. We must
know here that (xn) is monotone for the following to work, though!
If {xn : n in N} is bounded
above, then we can apply the Completeness Axiom (the set is non-empty
and is bounded above). Let T be the sup of the set. Now given
epsilon>0, there must be an element of the set between T and
T-epsilon. But elements of the set are sequence elements. That is,
there is xt so that T-epsilon<xt<=T. Now
consider n>=t. We know that (xn) is increasing, so if n>=t, then
xt<=xn. But T is the sup of all the xn's, so
xn<=T. Thus T-epsilon<xn<=T. Therefore for
n>=t,
|xn-T|<epsilon. We have just verified the definition of convergence
(!) with K(epsilon)=t. Very neat, somewhat tricky.
As I remarked last time, this class of sequences is interesting
because of the large number of applications involving them. It is
quite easy to create examples. Here, let me do it "spontaneously"
(something like this arose in conversations with Mr. Oleynick after
class): I know from "elementary" considerations that the following
functions are increasing (at least for positive numbers):
So if I compose them I will still get an increasing function. Consider
the sequence (xn) defined by x1=1 and
xn+1=(5xn3+7)1/4. Then x2 is
approximately 1.86. By an inductive argument, (xn) is increasing. Also
(xn) seems to be bounded: if xn < 100, then
(5(100))3+7)1/4 is less than 100 (easy
estimates, since (100)4 is 100,000,000). So I can now
conclude that (xn) converges! Quite simple. Of course, this doesn't
tell me what the limit is, but at least I can try to look for it
now.
I wrote in the background to the course (and said during various lectures)
that the single most important definition was that of limit of a
sequence. I can sort of try to understand sequences: they are a
countable object, sort of a list, and I can try to use simple-minded
(?) techniques like mathematical induction on sequences. Yet I am
trying to investigate the real numbers. One of the horrors and the
pleasures of the real numbers is that they are uncountable. How can I
use the tool of sequences, basically what seems to be a countable
tool, to investigate an huge, uncountable set? The method is to use
subsequences.
I will take for today a very formal view of sequences and
subsequences. Partly this is an effort to keep students alert and away
from the familiar standard notation (a subsequence is denoted by a
subscript on a subscript). But also it is a way to keep us honest and
rely only upon proving things. So here I go. First, let's
repeat what a sequence is:
A sequence is a function f from N to R.
A function h:N --> N is strictly increasing if for all
a and b in N, a<b implies h(a)<h(b).
A function g:N --> R is a subsequence of a function
f:N --> R if there is some strictly increasing function
h:N --> N so that g=foh (the notation o stands for the "little
circle" indicating composition).
I have written this in a very formal manner, to be darn near
incomprehensible: incomprehensible but honest. I gave a rather silly
example: f(n)=1/n, h(n)=n2, so that the subsequence g(n)
was 1/n2. In this example, we have a subsequence of a
convergent sequence which also converges, and the limits agree. This
is no accident:
Theorem If a sequence converges, then every subsequence
converges and has the same limit as the original sequence.
Proof: We first prove a result about strictly increasing h's:
Proposition If h:N-->N is strictly increasing, then
h(n)>=n for all n in N.
Proof: We prove this by Mathematical induction.
The statement is true for n=1, since h(n) is in N, and the lowest
element in N is 1, so h(1)>=1.
Now assume h(n)>=n. By the "strict increasing" definition,
h(n+1)>h(n), and h(n)+1 is the lowest integer greater than h(n).
Therefore h(n+1)>=h(n)+1. But if h(n)>=n, then h(n)+1>n+1, so
that h(n+1)>=n=1. We have completed the inductive step.
Back to the proof of the theorem: suppose the sequence f converges to
x. This means: given epsilon>0. there is K(epsilon) in N so that if
n>=K(epsilon), then |f(n)-x|<epsilon. But h(K(epsilon))>=K(epsilon), so if m
is in N and m>K(epsilon), then h(m)>=h(K(epsilon)>K(epsilon), so that
|f(h(m))-x|<epsilon, which is exactly the definition of "g=foh"
converges to x. And we're done.
Notation If g is a subsequence of f, then the traditional
notation goes something like this: f(n) corresponds to xn, and g(k)
corresponds to xnk. The text uses the more
traditional notation, so that's what I will generally do in the work
that follows.
Example We saw in the last lecture that the sequence
f(n)=(-1)n does not converge. The way we showed it in the
last lecture seemed rather elaborate and difficult to motivate.
Here's another method. If f(n)=(-1)n converges, then every
subsequence must converge, and the limit of every subsequence must be
the same. So we looked at the following strictly increasing functions
from N to N: h1(n)=2n (just "hits" the even integers)
and h2(n)=2n-1 (gets the odd ones). Then
g1=foh1 and
g2=foh2 are two subsequences of f. Not very
elaborate computation shows that g1 is the constant
sequence 1 (-1 raised to an even integer power is 1) and g2
is the constant sequence -1 (-1 raised to an odd integer power is
-1). So these two subsequences converge, and since they do not
converge to the same number (-1 is not equal to 1) the original
sequence f cannot converge.
Then I asked if it is possible to have a sequence with subsequences
converging to three numbers. We decided that could happen (the
sequence would alternate among 1 and 0 and -1). We could even have a
sequence with subsequences converging to 17 different numbers. A more
complicated question is the following:
Question Is there a sequence whose subsequences converge to
infinitely many distinct numbers?
There are many solutions to this problem. The answer, however, is
"Yes". One solution that I suggested in class is the following: let
xodd numbers always be 0. Now we know that at least
one subsequence must converge to 0. There are still infinitely many
integers left. Take every other even number (2,6,10,14, etc.) and let
the sequence elements which correspond to these integers be 1. Now we
know there's at least one subsequence which converges to
1. There are still infinitely many integers left. Sigh. Take every
other one of these (I guess this would be n's corresponding to
4,12,20, etc.) and let the xn's here be 2. Etc. So we get a rather
weird sequence (we could probably write a formula but who needs it?)
with a subsequence which converges to every non-negative integer. This
is strange. But how about an even stranger question?
Question Is there a sequence which, for each x in [0,1], has a
subsequence which converges to x?
The answer here is "Yes", also. Most verifications of this answer seem a
bit strange. Let me offer one of them, with an secret motive in
mind.
I will outline a procedure for creating the sequence. Then I will
outline a procedure for creating a subsequence which converges to any
x specified in [0,1].
Creating the sequence
- The first element of the sequence, x1, should be
any number in [0,1].
- The next elements: divide [0,1] into two equal halves. Let
x2 be any element in the left half, and let x3
be any element in the right half.
- The next elements: divide [0,1] into four equal parts. Let
x4 through x7 be points in each of these
quarters in order (left to right).
- The next elements: divide [0,1] into eight equal parts. Let
x8 through x15 be points in each of these
eighths, in order (left to right).
- And so on.
Again, I think it is possible to write formulas for such a sequence,
but I want to emphasize the qualitative aspect: we generate the
sequence "elements" in powers of 2, so that there is one in each
1/2K length of [0,1].
Creating the subsequence
Let's choose a random element, RANDOM, of [0,1]. I will get a subsequence
of the sequence "defined" above which will be guaranteed to converge
to RANDOM.
- The first element of the subsequence will always be
x1 as defined above. Note that since RANDOM and x1
are both in [0,1], |RANDOM-x1|<=1.
- Since the union of [0,1/2] and [1/2,1] is all of [0,1], RANDOM must
be in at least one of the two subintervals. Choose one. We choose the
next element of the subsequence to be the element of the subsequence
which is in the same half-length interval as RANDOM sits in. Then that
element has distance at most 1/2 from RANDOM.
- Since the union of [0,1/4], [1/4,1/2], {1/2,3/4] and [3/4,1] is
all of [0,1], RANDOM must be in at least one of these
subintervals. Choose for the next subsequential element the
xn which is in that subinterval. Then the distance from RANDOM
to that element is at most 1/4, since they are both in an interval of
length at least 1/4.
- Etc.
I hope I am not evading a good-enough specification of the
subsequence. I certainly don't want to write a complete specification,
since I would probably have to write lots and lots of details and I am
not sure that the details would help the understanding. The
subsequence (let me use the function-g notation now) is recursively
chosen so that |RANDOM-g(n)|<=1/2n-1 (that's the length of
the subintervals). Since the sequence
1/2n-1 --> 0, we know (Squeeze Theorem?) that the sequence
defined by g must --> RANDOM. And g is a subsequence of the original
sequence.
OF course there are other things one can say about this
procedure. First, it actually depends on the binary expansion of RANDOM: if there is a 0 or 1 in the nth
place, then we choose the left- or right-hand half of the next
subinterval and look for the element of the original subsequence which
is in that subinterval. Also, creation of this sequence uses the idea
of bisection, which is a famous technique both in theoretical
mathematics (I'll use it next time to prove the Bolzano-Weierstrass
Theorem) and in numerical analysis (the bisection method finds roots
of lots of equations.)
Question Id there a sequence which, for each x in R, has a
subsequence which converges to x?
I ended with this question, whose answer is also, "Yes". I remarked
that this could be verified with a construction like the previous
one. I should also say that Mr. Hedberg had a suggestion which applies
here: since we verified that the rational numbers are countable, we
can create a sequence which has each rational as an element of the
sequence. Then by using the density of the rationals we can get
subsequences which converge to any desired number. The details are not
completely easy, but this is an argument which can be made.
I returned the first exam, with an answer sheet and with comments about
the grading.
|
| 3/5/2003
|
We began the material of section 3.3 today. I decided to look at a
specific example and try to understand it well. I decided on the
following "process" in a fairly random way. Here is what I did:
I started with 1, then I multiplied by 8, added 13 to the result, and
took the square root of that. The result was 4.582575695.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 7.0470281.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 8.3292392.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 8.9237836.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 9.1864176.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 9.3000721.
I took this, multiplied it by 8, added 13, and took
the square root. The result was 9.3488276.
ETC. What is going on? People with experience in numerical analysis
may recognize this. Let me try to explain (and, hopefully, interest!)
other people.
First, we are looking at a sequence defined by the following recursive
rules:
An initial condition:x1=1
Recursive definition:xn+1=sqrt(8xn+113)
What can happen to this sequence? Here is a simple sequence of
"lemmas" analyzing what goes on:
Lemma 1: If x<=y, then 8x<=8y.
Lemma 2: If x<=y, then x+13<=y+13.
Lemma 3: If 0<=x<=y, then sqrt(x)<=sqrt(y).
Our sequence is obtained by a recursive rule which "concatenates"
these three "operations". Note that I needed to be a tiny bit careful
in Lemma 3, since our square root is only defined for non-negative
numbers. I also note, since it is useful for understanding what's
going on, that if the <= ("less than or equal to") between x and y
are changed to just < ("less than") then this strict
inequality is "inherited" by the outputs of the three
operations. Now back to our sequence.
Theorem: The sequence (xn) defined by
An initial condition:x1=1
Recursive definition:xn+1=sqrt(8xn+113)
is increasing: xn<xn+1 for n in N.
Proof: We will prove this by using mathematical induction. We will let
P(n) be the proposition xn<xn+1.
Base case: x1=1 and x2=sqrt(8+13)=sqrt(21), and since
21>12, we have verified P(1).
Inductive step: We assume P(n): xn<xn+1. Now use Lemmas 1 and 2 and
3 in order to get sqrt(8xn+113)<sqrt(8xn+1+13). But this is
xn+1<xn+2, which is P(n+1).
We are done with the inductive proof.
So we look now for more information about the sequence (xn). In fact,
we wonder if (xn) converges. Certainly an increasing sequence alone
need not converge. A simple example is xn=n, which, by the Archimedean
Property, cannot converge. Mr. Goode observed that the sequence whose
initial terms we computed seems to have smaller and smaller "jumps"
between successive terms. Maybe this means it converges. I remarked
that there is a sequence from calc 2 with interesting properties: xn=
the sum as j goes from 1 to n of 1/j. This is called the sequence of
harmonic numbers. It is an increasing sequence since it is adding up
more and more positive numbers as n increases. In this case, xn+1-xn is
1/(n+1), so certainly the sequence is taking ever smaller "steps" up
as n increases. However, we can use logic familiar from the Integral
Test, and compare xn with the left-hand Riemann sums of width 1 for
the integral from 1 to n+1 of 1/x. xn is larger than this integral,
and the integral is ln(n+1), which certainly is unbounded as n
grows. (I note that it is possible to get the result that the sequence
of harmonic numbers is unbounded without using integrals [I think the
logic is in the book] but this way is quicker.) .
What happens to our sequence (xn)? Mr. Hedberg suggested that the set
S={xn : n in N} is bounded. He even suggested the bound of 45. We
checked this:
Proposition: xn<45.
Proof: We will use Mathematical Induction. Call Q(n) the proposition
that xn<45. Then we observe:
The base case: x1=1, and 1 is less than 45.
The inductive step: Suppose xn<45. Multiply by 8, add 13, take
square root, to obtain: xn+1<sqrt(8·45+13)=sqrt(373), and
since 373<400 which is 202, I know that Q(n+1) is also
true.
So (xn) is increasing and bounded. Does it converge, and, if it
converges, what is its limit? Well, it can't converge to 46, say,
since 45 is an upper bound of the xn's, and 46 is one more, so that
the inequality |xn-46|<1 will never be satisfied. Recall that a
bounded sequence need not converge (we considered ((-1)n)
last time, an example of a bounded sequence which did not
converge). But here we have additional "structure": the sequence
increases. In fact, the sequence converges to the sup of the set
S={xn : n in N}. Why should this set even have a sup? We know that S
is not empty (1 is in S!). And we also know that 45 is an upper bound
of S. Therefore by the Completeness Axiom, S must have a least upper
bound. Let me call that least upper bound, L.
Theorem: (xn) converges to L.
Proof: I know that xn<=L for all n (definition of upper bound). I
also know that given epsilon>0, there is a member of the sequence, xfred,
so that L-epsilon<xfred<=L (the choice of xfred depends on epsilon, of
course). But I claim: if n>=fred, then |xn-L|<epsilon. Why? The
inequality |xn-L|<epsilon can be "unrolled" to
L-epsilon<xn<L+epsilon. But if n>fred, xn>xfred. fred was selected,
though, so that L-epsilon<xfred. so L-epsilon<xn. Also xn<=L since L is
an upper bound of the xn's. Therefore if n>=fred,
L-epsilon<xn<=L, which implies |xn-L|<epsilon. So we have verified
the definition of convergence.
Readers should note that we needed the sequence to be increasing
(o.k.: we didn't exactly need xn<xn+1 : our results would have been
true with the "weaker" statement xn<xn+1) and we needed L to be the
least upper bound, the sup, of the set of all the xn's.
But what is L? A whole bunch of more-or-less unsatisfactory
answers can be given:
L is the limit of the sequence (xn).
L is the sup of the set S.
L is less than 45.
These are unsatisfactory because they don't really "tell us" what L
is, nor do they relate L to the recursive rule which defined the
sequence. We can in fact be much clearer.
Since xn+1=sqrt(8xn+113), (xn+1)2=8xn+113. We know that (xn)
converges and that the limit of (xn) is L. We also can deduce that the
sequence (xn+1) converges, and its limit is also L (remember, "only
tails matter."). The limit of the left-hand side is L2. The
limit of the right-hand side is 8L+13. So we know
L2-8L-13=0. The quadratic formula is valid (I think it was
an exercise earlier in the book) so that L must be
(8+/-sqrt(82+4(13)))/2=(8+/-sqrt(116))/2=[approx](8+/-10.77)/2.
So there seem to be two choices for L. One choice is negative. But,
golly, each of the xn's is positive, so from previous results on
order, we know that the limit can't be negative. Therefore the limit
must be [approx]9.385 which is certainly at least consistent with the
previously computed numbers.
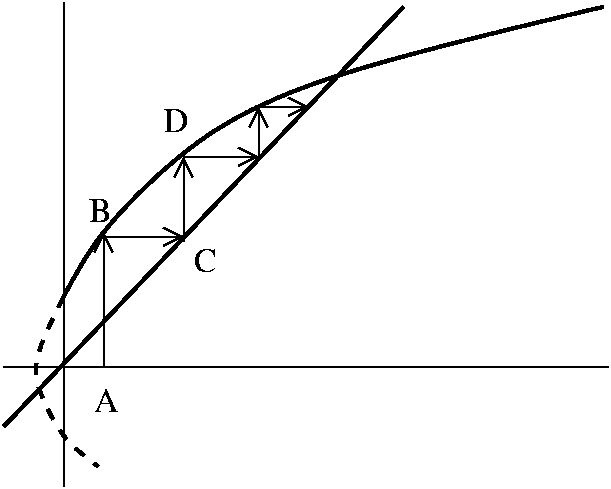 What is going on here? Look at the picture. The line shown is just
y=x. The parabola is y=sqrt(8x+13), or even y2=8x+13. The
point A is just an initial x1. Go "up" to the parabola. The
point B is (x1,x2), because the "rule of
formation" of the sequence is the same as y=sqrt(8x+13). Now "bounce"
to the diagonal line, where C is (x2,x2). Now
up to D, which must be (x2,x3), etc. The
sequence is gotten by bouncing back and forth between the curves. The
(xn) of Math 311 is just the first coordinates of these
points, marching to the right on the real line. The intersection of
the curve and the straight line is the point (L,L), and the sequence
"clearly" (well, maybe clearly geometrically) converges to L. It is
interesting to note that this process is quite "robust" --
perturbations of the initial "guess" x1 don't affect its
convergence to L. If the initial guess is chosen "too large", so
x1 is greater than L, the geometry shows that the sequence
decreases, wiggling back and forth, down towards L. This is a very
stable, very neat method of approximating a root. We have an
"attractive fixed point".
The main object of section 3.3 is to discuss:
What is going on here? Look at the picture. The line shown is just
y=x. The parabola is y=sqrt(8x+13), or even y2=8x+13. The
point A is just an initial x1. Go "up" to the parabola. The
point B is (x1,x2), because the "rule of
formation" of the sequence is the same as y=sqrt(8x+13). Now "bounce"
to the diagonal line, where C is (x2,x2). Now
up to D, which must be (x2,x3), etc. The
sequence is gotten by bouncing back and forth between the curves. The
(xn) of Math 311 is just the first coordinates of these
points, marching to the right on the real line. The intersection of
the curve and the straight line is the point (L,L), and the sequence
"clearly" (well, maybe clearly geometrically) converges to L. It is
interesting to note that this process is quite "robust" --
perturbations of the initial "guess" x1 don't affect its
convergence to L. If the initial guess is chosen "too large", so
x1 is greater than L, the geometry shows that the sequence
decreases, wiggling back and forth, down towards L. This is a very
stable, very neat method of approximating a root. We have an
"attractive fixed point".
The main object of section 3.3 is to discuss:
- Monotone sequences (xn).
- A sequence is increasing if xn<=xn+1 for all n in N.
- A sequence is decreasing if xn>=xn+1 for all n in N.
- Monotone sequences converge if and only if they are bounded.
- An increasing sequence is bounded below always, so such a
sequence is bounded when it is bounded above.
- An decreasing sequence is bounded above always, so such a
sequence is bounded when it is bounded below.
- A monotone sequence which is bounded converges to
- its sup if it is increasing.
- its inf if it is decreasing.
The proofs of these facts depend upon the characterization of inf and
sup with epsilon's, and on the "structure" ({in|de}creasing) of the
sequences involved. We may do more on this on Monday. There's an exam
tomorrow.
|
{kind=link}