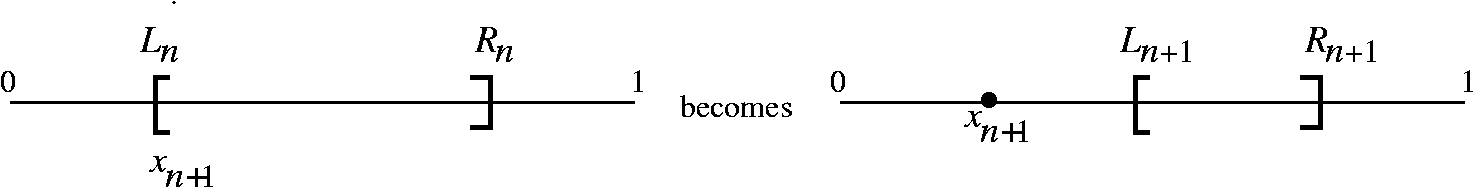| Date | What happened | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3/3/2003 | An ever-shrinking class accompanied me as I finished the
elementary "technology" of limits. So here's an outline:
We showed that if (xn) converges to x and if S={xn : n in N} then the set S is bounded. Is the converse true? That is, if the set of elements of a sequence are bounded, need the sequence converge? Ms. Greenbaum suggested that we look at the sequence whose elements were defined by the formula xn=(-1)n. Then (xn) "alternates" between +1 and -1, and it seems hard to believe that the sequence could converge. To show that (xn) does not converge to x, however, we would need to verify the following: there is some epsilon>0 so that for every N in N, there is n>N so that |xn-x|>=epsilon. Note that the choice of epsilon might well depend on x. In this case, there is a clever way to see that convergence can't occur. It depends on the fact that the distance from -1 to 1 is 2. If we choose epsilon to be 1, then for large n, the distance from xn to x should be less than 1. But the values of xn are +/-1. So go from 1 to -1 "by way of" x, and get a contradiction. More precisely, we will use the triangle inequality. Here is how: If (xn) converges to x, where xn=(-1)n, then take epsilon=1. Then there is N in N so that if n>N, |xn-x|<1. There are certainly even integers greater than n and certainly some odd integers greater than n. Let p be such an even integer and let q be such an odd integer. Then xp=(-1)p=1 and xq=(-1)q=-1. What else? By the triangle inequality, |xp-xq|= |xp -xq|= |xp-x+x-xq|=< |xp-x|+|x-xq|<2. But |xp-xq|=|1-(-1)|=2, and 2<2 is false. So the assumption that (xn) converges was wrong and the converse of the theorem is false.
Now let's try **the famous
Theorem Suppose c>=1. If (xn) is the sequence defined by xn=c1/n, (xn) converges and its limit is 1.
I remarked that a proof similar to this but with more complicated
details can be used to verify the following theorem:
Now we can do a more complicated version of the Math 152
workshop: The Question of the day is does (7n+13n+46n)1/n converge, and, if it does, what is its limit? I'll go on to 3.3 next time. I encouraged people to send in answers to review questions, and I will post these answers. Due a week from today (Monday, March 10) are these textbook problems: 3.2: 4, 9, 11, 13a, 16. | ||||||||||||||||||||||||||||||
| 2/27/2003 | We continued to trek through the rough landscape of
limits. My online dictionary defines the verb "trek" as 1. travel or make one's way arduously ("trekking through the forest"). 2. esp. [hist.] migrate or journey with one's belongings by ox-wagon. 3. (of an ox) draw a vehicle or pull a load. The only ox in sight is the instructor.
We proved the reciprocal theorem. A reward was given to all students present when this proof was completed.
Theorem(/) If (xn) converges to x and if (yn) converges to y,
and if y is not 0, then for n large, zn=xn/yn is defined, and (zn)
converges and its limit is x/y. Whew! Now I remarked that we can do a few more examples, officially. These examples are still rather baby calculus, but we can prove them. So we could look at xn=(5n2+7)/(3n2-2). Algebraically, this is the same as xn=(5-7(1/n)2)/(3-2(1/n)2). We know that the sequence (1/n) converges and its limit is 0 (this uses the Archimedean Property). Then by all of our results involving limits and arithmetic (sums and products and quotients), we can deduce that (xn) converges and its limit is 5/3. In fact, we can "handle" now limits of sequences of values of rational functions, just as yesterday we observed that we could analyze limits of sequences of values of polynomical functions. Limits & order (maybe better: Limits and inequalities)
Theorem If (xn) converges and its limit is x, then x>0
implies that there is M in N so xn>0 for n>=M. I then tried to "perturb" this theorem a bit. I asked what happened if we changed the inequalities.
What about the converse? So we could look at some assertion similar
to: In fact x does not "inherit" from xn in this case. We can look at xn=1/n. Then all the xn's are positive, while x itself is not positive.
A simple repertoire of examples is very useful to check
ideas! My online dictionary gives this as one definition of
"repertiore":
Theorem If (xn) converges and its limit is x, and if we know
that xn>=0, then x>=0 Again, I tried to examine what would happen if we changed the inequalities a bit.
Fascinating Question of the day: suppose (xn) is a convergent sequence and its limit is x. If you know that 0<xn<1 for all n in N, what can you conclude (with no additional information!) about x? I hope that most people will answer that x is in the closed interval [0,1]: 0<=x<=1. This answer uses the ideas of the last two theorems. We are quite close to moderately sophisticated mathematics. Here is an almost realistic scenario. Suppose we want to solve some sort of equation, f(x)=0. We might have a root-finding technique (or even several of them) which creates a sequence of better and better approximations to a root. Well we might have the following setup: (xn) converges to x and (yn) converges to y. We happen to know that xn<=yn for all n in N. We also know that the approximations grow closer and closer together. Here is one specific type of "closer": we might know for for n in N, 0<=yn-xn<1/n. What can we conclude?
We decided, in fact, that in this case the limits would be equal. That
is, x=y. Why would this occur? Well, we need all the information, but
the key is the estimate with 1/n. We do know: Now we look at zn=yn-xn and apply the previous proposition, so the limit of zn (which by our arithmetic results, must be y-x. Since z=0, we know y=x. What happens if we average our approximation schemes? That is, we create wn=(1/2)(xn+yn). By our arithmetic limit theorems, this sequence (wn), which is "trapped" between (xn) and (yn), will also converge and its limit will be the common limits x=y. This is a version of the Squeeze Theorem which we will do next time, and we'll do some interesting examples, too. I handed out review problems for the first exam, which will be given in a week. | ||||||||||||||||||||||||||||||
| 2/26/2003 | I continued to try to assemble a technological base to study
sequences. This is rather intricate, and some parts of it have details
which are not fun. General properties
Theorem 1 If (xn) converges to x and if (xn) converges to y,
then x=y. Theorem 2 If (xn) converges to x, then there is M>0 so that the set S={xn : n in N} is bounded by M: if s is in S, then |s|<=M.
The final fundamental result that we need is this: Limits and arithmetic (wasn't this Limts and algebra before?) We see what happens with addition, multiplication, etc. Most of the results here are very familiar to any long-suffering calculus student, but the interest in this course is building the detailed proof structure. Addition is fairly easy.
Theorem (+) If (xn) converges to x and (yn) converges to y,
then (xn+yn) converges to x+y.
That one isn't too bad. Slightly more difficult is multiplication.
Some examples The constant sequences converge (!). That is,
suppose c is a real number, and the sequence (xn) is defined by xn=c
for all n in N. Then (xn) converges to c. (You can take K(epsilon) always
to be 1 because |xn-c|=|c-c| is always 0!)
Here's the last major algebraic result about limits (we'll use it
to get an additional statement about quotients, of
course!): Comment It is certainly true that this proof is very elaborate, and one may well question the applicability of the methods to almost anything that almost all students are likely to encounter in later life. Let's see: "learning things is good" could be one answer, and it is one which I agree with. Any student who learns about actual numerical or scientific computing will need to know some elements of what we're doing here. If x is an approximation to y in some computation, how good (or bad) will the approximation of 1/x be to 1/y? That sort of problem is implicit in the "guts" of many computational strategies. It can be analyzed using the tools we are beginning to assemble here. So ... that's a partial answer. I think more applicable for most students is that this is a part of the 311 experience. And we can debate later if that experience is "worhtwhile" or "meaningful". Meanwhile, there is more to do tomorrow! | ||||||||||||||||||||||||||||||
| 2/24/2003 | Several announcements: Because the material of Workshop #4 is both important and complicated, I will meet with students in 6:30 PM on Thursday, February 27, in Hill 425, and I hope to write out complete solutions to all seven of these problems. As a spectator sport alone this should be fun (for you, maybe, and less so for me!). If someone takes good notes, I can scan them and put them on the web. We will have an exam a week from Thursday (in class on March 3). I will give out a review sheet this Thursday instead of more workshop problems. The review sheet will contain full information about the exam (the format, sections to be covered, etc.). It will also have sample problems, mostly problems I will get from other instructors' past exams. The reading for the week is sections 3.1 and 3.2 and 3.3.
I again wrote the definition of the limit of a sequence: I tried an example: suppose xn=(3n)/(4n+5). Should this sequence converge, and, if it does, what is its limit? Mr. Citterbart declared that it should converge, and that its limit should be 3/4. I agreed. But I wanted to provide a formal proof of this assertion. And we have very little "technology" to use: we only have the definition of limit. So I first did some informal preparation for the formal proof. I remarked that virtually everyone I know does this, although reading the text it might seem that the proofs should come forth beautifully formed from some divine source.
Informal preparation I want |(3n)/(4n+5)-3/4|<epsilon where epsilon
is some unspecified positive number. Somehow I want n to be
"controlled" by epsilon, so that if "the opponent" supplies an epsilon, then I
can choose n so large that the difference above will be less than
epsilon. The first thing we did was to work algebraically with the
difference above:
Formal proof We wish to show that ((3n)/(4n+5)) converges to
3/4. Suppose that epsilon>0 is given. By the Archimedean property,
there is a positive integer, which we will call K(epsilon), so that
K(epsilon)>(1/4)((15/4epsilon)-5). Now I must prove the following
implication: There are several comments to make about this formal proof. It seems really irritating, somehow redoing things we've already done. And it seems long and clumsy. In its defense I remark, as I did in class, that we right now have essentially no "technology" to do proofs about limits: all we have is the definition of limit, and that's the only way we can verify that a sequence has a limit. I changed the problem a bit, from xn=(3n)/(4n+5) to xn=(3n)/(4n2+5). Now we decided that the sequence should converge, and its limit should be 0. I wanted to write a formal proof of this, also. I began as before with Informal preparation Now epsilon>0 is specified, and I want to find n so that |(3n)/(4n2+5)-0|<epsilon. We can "clarify" the situation a bit algebraically. The absolute value is not needed, since what is inside is already positive. Again we "cross multiply", not changing the direction of the inequality since everything involved is positive: 1/epsilon<(4n2+5)/(3n). We're trying to uncover n so that we could once again use the Archimedean property to guarantee a K(epsilon). We notice that we have 3/epsilon<(4n2+5)/n=4n+(5/n). Now we need to think, since we don't seem to have a simple "recipe" where the Archimedean property can just apply. Mr. Kang suggested that we just ignore the 5/n! This is clever: notice that if 3/epsilon<4n then certainly 3/epsilon<4n+(5/n) since (5/n) is positive. And 3/epsilon<4n is a very easy inequality. We can satisfy it by requesting that 3/(4epsilon)<n, which can be "handled" by a direct reference to the Archimedean property. So here we get the following guess for K(epsilon): an integer greater than 3/(4epsilon). Question of the day I asked the students to write the formal proof that 0 is a limit of the sequence (3/(4n2+5)). I hope that people were comfortable doing this. I will look at the answers later. The proof should include a step which is very very strange: the writer just casually adds on 5/n out of "thin air" -- I know that if I presented this proof to a class formally I would find that step extremely difficult to motivate! I remarked that the balance of the week would be spent in developing "technology" to handle limits, so we won't have to verify every limit statement by direct checking of the definition. That would indeed be rather tedious. The agenda will be:
Theorem Suppose (xn) converges to x and suppose (xn) converges
to y. Then x=y. Then I went on to ask how sup's and inf's interact with limits. More specifically, suppose (xn) is a series which converges to x. Define the set S to be {xn : n in N}. So S is the set of "values" of the sequence. Does sup(S) necessarily have to be the same as the limit, x? One example (xn=1/n, where sup S =1 and x=0) showed that the answer is no. So I asked if inf(S) is the same as the limit, always. And another answer(xn=1-1/n where x=1 and inf(S)=0) showed that equality can fail, too. Finally I asked if the limit always must be either the sup or the inf? And the example xn=(-1)n/n which has the limit, x, equal to 0 and the inf equal to -1 and the sup equal to 1/2, showed that all three numbers could differ. But, in fact, more profoundly, I asked whether the set S has to be bounded in the first place (if it wasn't bounded, then actually the sup and the inf don't have to exist).
Theorem If (xn) is a sequence which converges to x, and if
S={xn : n in N}, then S is bounded. The last general principle I wanted to state was illustrated by the following example: suppose (xn) is a convergent sequence and its limit is x. Now suppose we define another sequence (yn) by the following rule: yn=(xn)^3+176,321 for n<=1078 and yn=xn for n>1078. Does (yn) converge, and, if it does, what can you say about the limit of (yn). The amazing fact is that (yn) does converge and its limit is x! I don't think that a mortal human being could see this by "testing" values of xn (huh? look at the first ... say the first ... well, if you "check" one term a second for about 3 three, you will only have looked at less than 100,000,000=108 terms. But if K(epsilon) is the expression guaranteed to us by the convergence of (xn), then any n greater than J(epsilon)=max(1078,K(epsilon)) will certainly have |yn-x|<epsilon. So you can change a sequence for "a while" and this won't change whether it converges or not, and it won't change the limiting value if it does converge. | ||||||||||||||||||||||||||||||
| 2/20/2003 | I first discussed yesterday's "Question of the Day". Here the
set S was the numbers, x, which could be written as (M-N)/(M+N) where
M and N were elements of N, the positive integers. I asked if S
were bounded above, and if it was, what sup(S) was. We discussed this question. A suggestion that 1 was an upper bound of S was made. The assertion (M-N)/(M+N)<=1 would need to be verified. But this is not too hard, because if we begin with M<M, certainly a true statement, and then subtract a positive number (N) from the left-hand side, and add that positive number to the right-hand side, then M-N<=M+N. Since M+N>0, we can divide by M+N to get (M-N)/(M+N)<=1. Therefore 1 is an upper bound. Then the suggestion was made that 1 is actually sup(S). It isn't totally clear to me how such things are guessed: look at lots of examples, try to see what happens when things get "big", etc. It is hard to explain human invention, and this is a modest example of such invention. How can one verify that sup(S)=1? I suggested looking at the difference between 1 and a typical element of S. So consider 1-(M-N)/(M+N)=[(M+N)-(M-N)]/(M+N)=2N/(M+N). I would like this to be "small" to establish that 1 is the least upper bound. If N is very large, then my experience with calculus suggests that 2N/(M+N) would get close to 2. So maybe to make this small, I should take N small. Since N is in N, I will try N=1. Then 2N/(M+N)=2/(M+1). This is slightly simpler to analyze. How can I "make" this small? Can I choose M so that 2/(M+1) is less than epsilon, where epsilon is some positive number specified in some weird way? Well, 2/(M+1)<epsilon will be true exactly when (2/epsilon)-1<M is true. Can such an M be found? The existence of such an M in N is guaranteed by the Archimedean property of the integers. Well, but now what? Now we know that if epsilon>0, then there is an element s of S so that 1-s<epsilon. This means 1-epsilon<s. But, my goodness, we know that 1 is an upper bound of S, so here we know 1-epsilon<s<=1. We have exactly verified the criterion for 1 being a least upper bound of S. This was a theorem we proved a few lectures ago. Similarly one can verify that this S is bounded below, and that inf(S)=-1. I remarked that it would be easy to get more examples of sets following this description. I could replace the "formula" x=(M-N)/(M+N) by something like
Now we come to the definition of limit of a sequence. As I wrote, this is "Almost surely the most important concept in Math 311". Although most sequences we think about are likely to be "simple", in fact sequences can be terrifically complicated. Usually the first example one thinks about is the sequence (1/n), or 1, 1/2, 1/3, 1/4, ... Note that with our definition, the limit of this sequence should be 0. Contrast that, please, with the fact that the sup of the elements of the sequence is 1.
Definition A sequence is a function whose domain is N
and whose range is a subset of R.
Definition A sequence (xn) is said to converge to x if
for all epsilon>0, there is K(epsilon) in N so that
|xn-x|<epsilon.
I decided to do something weird, to try to write the negation of the
statement above. So: Notice that if we want to prove that a sequence does not converge to some x, we need to specify only one epsilon and not check every epsilon! I tried to show that the sequence (n2) does not converge to 17. Of course, I did screw up -- I insisted on checking every epsilon which was too much work. So, here it is better, improved: how can we show that (n2) does not converge to 17? Well, we can specify an epsilon, say, epsilon=1. Then we need to see if |n2-17|>=1. We can remove the absolute value signs if we knew that what was inside was positive. So, golly, if we insisted that n was at least, say, 5, then |n2-17|=n2-17. So we need to know when n2-17>=1. And we need to know that n is at least K, some unspecified integer. So the two requirements will be satisfied if n is some integer greater than or equal to max(5,K). If we wanted to know that |n2-17|>=epsilon, then we could request that n be some integer great than or equal to max(5,K,sqrt(epsilon+17)). Such an integer exists by the Archimedean Property. I asked students to begin reading chapter 3 (at least 3.1 and 3.2), and to hand in textbook problems 2.4: 3, 4a and 3.1: 8, 10 in a week. Another set of workshop problems was also handed out. Also, I announced that an exam would probably be given in about two weeks. | ||||||||||||||||||||||||||||||
| 2/19/2003 | I discussed the material following the last diary entry's
"Pedagogical Error" statement. We went over some of the workshop problems from workshop #4. I tried to emphasize that finding examples and understanding the statements were important. I repeated my comments written in the last diary entry about the general structure of many of the proofs at this point in the course (contradiction, inequalities, Archimedean property). In almost an hour of discussion, we were only able to cover some aspects of problems 2 and 3. So investigating these problems is very difficult, and very painstaking. Much patience is needed!
Somewhat more detail Another example? We considered A=(0,1). Here A is nonempty, and A consists of positive numbers, and I asked why (III) was satisfied. We thought about this, and if a number is between 0 and 1, two-thirds of it would also be, since 2/3 is positive and 2/3 is less than 1. After some inquiry, we were given (0,1) union {2} as another example. This certainly "works". And another example: we considered S whose elements were 1/n where n was in N. If a=1/n, can we find b in S with b<(2/3)a? Ms. Chan suggested b=(1/3)(1/n)=1/(3n), certainly an element of S and certainly less than (2/3)a.
Now I made the game harder. I asked if there were an example of
an S which satisfied (III) but which had the following
qualifications: The last requirements seem to mean that S has lots of holes. The suggestion was made that we consider an S which is the collection of positive rationals. And, actually, due to the density of both the rationals and the irrationals, the example "works". For problem #3, the examples we considered seem far more "routine". For example, we looked at intervals "drifting" to the left: one example was An=(-n,-n+1). Then we proved that each An had to have an upper bound (this followed from the fact that An was a subset of B, which did have an upper bound). So each An had a least upper bound, sup(An). This was because we needed to verify that each un existed. Then I tried to verify orally the equality suggested in the proof. I don't know how successful I was. What was the strategy I used? This: after we established that the two sup's mentioned in the problem exist, I also remarked that to prove A=B, we may prove both A<=B and A>=B. This strategy will certainly work for the equality requested in problem 3.
The question of the day | ||||||||||||||||||||||||||||||
| 2/13/2003 | Today's the last day I will try to "cover" material in
chapter 2. I will attempt on Monday to discuss with students
some of the workshop problems. The results today contain further nearly paradoxical consequences of completeness. The discussion will also continue using various proof techniques which are common to the subject:
Theorem The rationals are dense in the reals. More precisely,
if x<y are real numbers, then there is q in Q with
x<q<y. More special case: 0<x<y & y-x>1. Here the length of the interval is greater than 1. I'll bet that I should be able to find an integer inside the interval (x,y). Well, what integer? I defined the following set: W={w in R : w is in N and w>=y}. SO W is a subset of N. What do we know about W? First and most important and almost obvious: W is not the empty set. Why? (Everything must be proved in this course!) By the Archimedean property, there is n in N so that n>y. So W is not empty. Now how can we get "close" to the open interval (x,y)? Every nonempty subset of N has a least element (this is called "well-ordering" and many people in class may know about it through the "principle of the smallest counterexample"). Suppse that v is the smallest element of W. Then v>=y. What about v-1? I bet that this integer will "work" -- it will be inside (x,y). The proof that it is inside uses contradiction.
What if v-1 is not in (x,y)? Then either v-1>=y or
v-1<=x. So we have found an integer in (x,y) if y-x>1. Let's go back now to a less specific case: what if we only know that y-x>0? At the suggestion of a student, we will "stretch" the interval (x,y). I claim there is m in N with (mx,my) having length greater than 1. Why is that? Well the length of (mx,my) is my-mx=m(y-x). Since (y-x)>0, the Archimedean property implies that there is m so that the product of m and y-x is at least 1. (Take m to be any integer greater than 1/(y-x).) Then the previous "analysis" applies to (mx,my). We can "find" an integer n which is inside (mx,my): mx<n<my. But if we divide this inequality by the positive integer m we get x<n/m<y, and n/m is in Q, so we are done with this case. Sigh. So we have "handled" 0<x<y. What about 0=x<y? Well we can use the fact that 0<y/2<y and use the previous case: we can find a rational number between y/2 and y, so there must be one between y and 0. What about the case x<0<y? Well, we can use the previous case and find a rational number between 0 and y, and that will work here. Sigh. Now move "down": we have two further cases: x<y=0 and x<y<0. Both of these can be "transformed" into an earlier case by multiplying the inequalities by -1. Then positive rationals are found in the transformed cases, and changed back to the current cases by multiplying those rationals by -1: so if x<y<0, for example, then 0<-x<-y so that there is n/m with 0<-x<n/m<-y and therefore 0>x>-n/m>y. So there is a rational number in every interval of positive length. Indeed, if you keep chopping up intervals, you can actually find an infinite number of rational numbers inside every interval of positive length!
Now the task is to analyze the irrationals. Well, here is a very
irritating proof of a statement:
Theorem There is a positive real number whose square is 2. So A has a least upper bound. Let's call a the sup(A). We know (1 is in A) that a is positive. We also know that a is less than 7. I am more interested in a2. I bet that a2 is equal to 2. But I need to more than bet in this course. I need to be sure and to verify. I will proceed by contradiction. If a2 is not 2 then either a2<2 or a2>2. I will try to find contradictions in both of these cases.
The case a2<2 b2=a2+2a/n+1/n2 and we would like this to be less than 2. I am assuming here that a2<2. So 2-a2 is positive. Therefore we want n so that 2a/n+1/n2<2-a2. Let me "factor out" a 1/n, so that I want (1/n)(2a+1/n)<2-a2. This is quite complicated in its dependence on n. Let me make my requirement a bit simpler: if I could get (1/n)(2a+1)<2-a2 then since 1/n<1 I would know that (1/n)(2a+1/n)<(1/n)(2a+1)<2-a2 and I would be done. So I need (1/n)(2a+1)<2-a2. But ("solving for n") this means I want n so that (2a+1)/(2-a2)<n. I can find this n because of the Archimedean property. Whew! I am done with providing a contradiction to this alternative.
The case a2>2 We know a2>2 and thus a2-2>0. So a2-2a/n+1/n2>2 means a2-2>2a/n-1/n2. The n2 on the right is confusing me. Let me "factor out" a 1/n: I want n so that a2-2>(1/n)(2a-1/n). The darn 1/n in the term (2a-1/n) is confusing me. Suppose I could find n so that a2-2>(1/n)2a. Then I know that a2-2>(1/n)2a>(1/n)(2a-1/n) so I would be done. (By the way, I think it is "wiggly" reasoning here that is close to the most difficult part of the proof for the newcomer. I don't totally know how to make this simpler: I am sorry.) To get a2-2>(1/n)2a is the same as getting an n in N so that n>2a/(a2-2) and such an n can be found because of the Archimedean property. Therefore we have eliminated the two "undesirable" alternatives, and the Completenenss Axiom has guaranteed us a positive real number whose square is 2. In calculus we could "create" a square root of 2 by considering the graph of y=x2 on, say, the interval [1,2]. The graph goes from (1,1) to (2,4) and must cross y=2 somewhere, and that somewhere has x=sqrt(2). The "must" comes from the Intermediate Value Theorem. We will prove a version of the Intermediate Value Theorem in this course when we get the "technology". The reasoning in the theorem just proved is essentially a very stripped-down version of the reasoning in the Intermediate Value Theorem. The proof of the theorem is quite intricate! Please also note that the elaborate proof scheme does not provide a method for efficiently approximating sqrt(2). That's a very different thing, one which we may touch upon later. Now we know one specific irrational number (but in fact, by the counting argument there are lots and lots and lots of them!). The enthusiastic and masochistic student could try the same argument to get a square root of 3 or a cube root of 4, etc. We now can "create" many irrational numbers: if P and Q are rational numbers, and Q is not 0, then I claim that P+Q*sqrt(2) is also irrational. Because if it were rational, say a rational number M, then sqrt(2)=(M-P)/Q would be rational which is false. Using this idea (multiples of sqrt(2) properly scaled) we could prove:
Theorem The irrationals are dense in the reals. More precisely,
if x<y are real numbers, then there is an irrational number
i withx<i<y.
The question of the day
I may have made a serious error in exposition here. For the purposes of the course, the results I would like students to "internalize" from this lecture are the following:
The first statement follows fairly directly from the Archimedean
Property, and is discussed above. The second result got a very, very
tortuous exposition. The online dictionary defines "tortuous" as Let me discuss a different way of getting the result desired. The "counting argument" already establishes that there are irrational numbers. That is, the rationals are countable, and the real numbers are not, so the irrationals must be uncountable. But must there be irrationals in, say, the closed interval [0,1]? Maybe some how (!?) that interval doesn't have any, and the irrationals are "somewhere else". Well, let's think a bit: if v is irrational, then v+1 is irrational, and, conversely, if v+1 is irrational, then v is irrational (for if v+1=q in Q, then v=q-1 is certainly rational). Therefore if [0,1] is "free" of irrationals, so is [1,2]. And so is [2,3], and ... The "..." indicate a proof via Mathematical Induction which could be run going "to the left" (to [-1,0] and [-2,-1] and ...) as well as "to the right". By the Archimedean Property, every number is in one of the intervals [m,m+1] for m in Z. So if there are no irrationals in [0,1], then there are no irrationals in all of R, which is a contradiction. This idea should also appeal to a certain "naive" feeling about the "real line": the real line is or should be "homogeneous" -- any one piece of it should "look like" another piece. So [0,1] and [53,54] and [-109,-108] should "look" the same. And that's what the discussion in the previous paragraph says. We can go further. Look again at [0,1]. We now know it has irrationals in it. If we break up [0,1] into intervals, say, [0,1/3] and [1/3,2/3] and [2/3,1], then these look alike, also. If one of these intervals has irrationals in it, then translate by +/-1/3 or +/-2/3 to get irrationals in the others. And if one of those intervals does not have irrationals, then neither do the other two (again, the intervals look the same for the rational/irrational characterization, since we are translating by rationals). We could extend this argument, and divide intervals into n equal parts, etc. The natural conclusion would be: any interval of positive length which has rational endpoints must have irrationals inside it. Now take your interval (x,y) with length y-x>0, where you know nothing about the rationality or irrationality of x and y. But, golly, the earlier result says we know there are rationals in (x,y). Well, in fact, there is q1 in (x,y) and then we can get q2 in (q1,y) with both q1 and q2 in Q. So we've put an interval with rational endpoints inside (x,y), and that interval must have irrationals in it. Of course students must decide if they like this argument. One defect, certainly, is its "non-constructive" nature: no specific irrational is actually exhibited. It is a "soft" argument. But maybe it is easier to understand, and we now do get the density of the irrationals nicely and easily (at least, "nicely and easily" to me -- with much less "sweat" than the sqrt(2) proof above). | ||||||||||||||||||||||||||||||
| 2/12/2003 | I vowed to (try to) do stuff only in the book
today. And I will finish chapter 2. So I will go from back to front
(!) in chapter 2. So, beginning backwards: I remarked that I would not at this time discuss decimal expansions. I hope to come back to them after we have done infinite series. Decimal expansions are a specific type of such, and they are really quite touchy to explain and understand. (Why then are we ever impatient if students in third and fourth [and tenth and eleventh] grades misunderstand them?)
Continuing backwards, I stated the If I=[a,b] and J=[c,d], then I is a subset of J if and only if c<=a and b<=d. Note that almost everything from now on in the course will have inequalities in it, and this is one example. You should prove the equivalence of the statements in the initial sentence of this paragraph. Also, if I is a subset of J, then b-a<=d-c (multiply one of the inequalities by -1 which "reverses" it and then add it to the other). Therefore the "nested sequence" In is really this: a collection of closed intervals [an,bn] so that:
I L is not empty. This is true because a1 is in L. II L has an upper bound. Let me be more precise than I was in class:
I claim that b1 is an upper bound of L. The proof will be
a bit intricate.
(I) and (II) allow us to apply the Completeness Axiom, and we know
that sup(L)=s exists. We also know that an<=s for all n in N. We
can conclude that s is in In if we also know that s<=bn. Why
should this be true? (Here is where I did draw a picture of the
geometric situation on "the real line" in class.) If we can establish
that bn is an upper bound of L for each n in N then we will
know that s<=bn. So all we need to prove is the statement:
Q(k,n): ak<bn for all n and k in N. Now we know that bn is an upper bound of L, so s, the least upper bound must satisfy s<=bn. This together with what we knew before implies that s is in In, for all n in N, and this is what we were supposed to prove.
Question What are "nested intervals" and who cares?
Proposition If inf({bn-an}, n in N)=0, then s is unique: there is
exactly one point which is inside all of the In's. Examples The remainder of the class was devoted to examples. The examples range fromt the stupendously silly to the somewhat subtle, and are good reviews of things we have already done. 1. If In=[0,1], then the Nested Intervals Theorem applies. There are many, many eligible s's: in fact, the collection of all the s's is exactly [0.1]. 2. If In=[0,0], then the Nested Intervals Theorem applies. s=0 is the only number in all of the intervals. 3. If In=[0,1/n], then the Nested Intervals Theorem applies. Certainly s=0 is in all of these intervals. Can there be anything else? Since the intervals each contain 0 and positive numbers, the only possible candidate would be some v>0. But we already showed that if v is positive there is some n in N with 1/n<v. So there can't be any other v. s=0 is the only number in all of the intervals. 4. If In=[-1/n,1+1/n], then the Nested Interval Theorem applies, and both "sides" of the intervals are "moving". Here the collection of s's which are in all of the In's is all of [0,1]. (We need to know that if w>1, there is 1/n with 1+1/n<w, which follows from the same result we proved last time.) 5. Now I started fussing with various other hypotheses. What if we remove "bounded" from the hypotheses? A closed unbounded interval is one of two types: [A,infty)={x in R: x>=A} and (infty,B]={x in R: x<=B}. Then there are nested closed unbounded intervals having lots of numbers in common: take In=[0,infty) for all n in N. And there are nested closed unbounded intervals having no numbers in common: take In=[n,infty). Then a number s will be in all of these In's if s>=n for all n in N. But the existence of such an s would contradict the Archimedean Property that we have already proved! 6. What if we changed "closed" to "open" in the hypotheses, but kept all the other words: that is, we look at nested sequences of open bounded intervals. An interval is open if it is of the form (A,B)={x in R : a<x and x<b}. If we took In=(-1/n,1+1/n) for all n in N, then the set (0,1) is the collection of s's which are in all of the In's. If we took In=(-1/n,1/n), then s=0 is the only number which is in all of the In's (again, using Archimedean consequences). And, perhaps most subtle of all, if we took In=(0,1/n), then we have a nested sequence of open bounded intervals, and there is no number s which is in all of the In's! Next time I will continue backwards and finish chapter 2. I will verify the density of the rationals, the existence of sqrt(2), and then the density of the irrationals. | ||||||||||||||||||||||||||||||
| 2/10/2003 |
Students have made some errors in written work (textbook homework,
workshop problems, class work) which are significant and common. I
hope that by pointing them out I can help people avoid these errors. I
also add some general comments about written work in this course.
Please proofread what you hand in. Ideally, you should read and reread and revise almost any formal communication. Neatness and clarity count, as you darn well know if you've tried to read any complicated document.
I began by rewriting a great deal of what I wrote last time. Then I
asked students to write answers to
Proposition Suppose V={x in R : x=1/n for n in N }. Then V is
bounded, and
sup(V)=1 and inf(V)=0.
The online dictionary tells me this about daphne:
Discussion I proceeded to investigate one "bad" consequence
of completeness,
the consequence which I labeled (a) during the last class: the
disappearance of little, small, very
small, infinitesimal numbers. "Everyone" has seen or endured or even
said explanations of such symbols as dy/dx: this is a ratio of really
really very very small numbers. And then sketched the curve y=f(x) and
drawn an infinitesimal right triangle, with one side "dx", the other
side "dy", and the ratio the "slope of the curve at the point". And
then when questioned, one is told that dx is very small. How small?
Well, it is smaller than 1/10 or 1/1,000 or ... very very small. It is
not 0, because one can't divide by 0. It is very small, and dy is the
consequential increase in y when x is "increased" by dx. Etc. This is
all very embarrassing, because: Then I turned to a analysis of the bad consequence (b) of completeness. This is more elaborate. I began with reminders (from the lecture of 1/23). I reminded people of the definition of a finite set (a set that had a bijection with {1,2,3,...,n} for some n in N). I reminded people of the definition of a countably infinite set (a set that had a bijection with N). And, finally, a set was countable if it was either finite or countably infinite. The startling result we are now about to prove needs these ideas.
Theorem R is not countable. (More positively stated, R
is uncountable.) Discussion Mathematical induction allows us to prove things about N. Indeed, mathematical induction allows us to prove things about sequences of statements. But one result of the theorem we just proved is that we cannot create a list of statements about individual real numbers, use mathematical induction to prove each statement, and then claim we have proved a statement about all real numbers. We can't make a sequential list of all real numbers. Therefore our proof techniques need to include somewhat different tools. Indeed, almost every proof we do later in this course will use inequalities. Inequalities are the chief tool of analysis. What can "computer science" do? Let me take a somewhat simplistic view of what computers can do. They run with programs, and programs act on inputs. Each program is a finite sequence of instructions. Each input is a finite sequence of symbols. This vision of computation is "deterministic", by which I mean that the program + the input completely specify what will happen. This is a coarse (?) view of programs, but if you accept it a rather startling conclusion can be gotten. How many programs are there of length, say, 78? No matter what the computer language, anyone would agree that the total number of computer programs of a fixed length is finite. Here I don't even care how big this number is, just that it is finite (a list of all strings of symbols of a certain length). How many inputs of length 78 are there? Again, finite (another long list). Therefore, the number of outputs of computer programs which are length 78 acting on inputs of length 78 is finite. Note that 78 is not special here. The number of outputs of computer programs which are length N acting on inputs of length N is finite for any N in N. But that means (since the union of countably many countable sets is finite [see the diagonal process in lecture of 1/23]) the number of outputs of computer programs is at most countably infinite. Let me temporarily call those real numbers which can occur as outputs of computer programs as "the computable real numbers", then, oh my goodness, there are many many many more real numbers which are not computable! Some people find this quite distressing. More or less, the discussion of (a) might convince someone that the Completeness Axiom proves there aren't enough real numbers, while the discussion of (b) could say that there are too many real numbers! This is complicated by a sort of disciplinary (math="the discipline" here) schizophrenia: essentially all professional mathematicians claim to believe in the Completeness Axiom, and many people think about "really small" numbers, and increasing numbers of people worry about the computability of "real numbers". Although objections (a) and (b) above can be distracting at times, from now on we will officially "believe" in the Completeness Axiom. As for the students, it is, as I remarked in class, something you should believe (!) if only for the purposes of the course (just as a student who believed in creationism might need to learn enough about evolution to answer some test questions correctly). | ||||||||||||||||||||||||||||||
| 2/7/2003 | Although I've tried to delay it as long as possible, today we
begin the deep stuff in the course. Our aim is
NO HOLES!When you are done, please read sections 2.3, 2.4, and 2.5.
We begin with a bunch of definitions> These definitions are actually designed to be tested -- the terms are defined by asserting that there are w's for which certain comparitive statements are true. So whenever we work with the definitions, we can always see what will happen to the "w".
(Counter)example(s): F itself is neither bounded above nor bounded
below. For example, suppose an element w of F is an upper bound. Then
x=1+w is greater than w (since 1 is in P) and this element x of F
shows that w is not an upper bound of F. Similarly F has no lower
bound. Definition Suppose S is a nonempty set of F which is bounded above. Then v is a least upper bound of S if
Definition Suppose S is a nonempty set of F which is bounded below. Then v is a greatest lower bound of S if
We discussed some examples, which are here displayed in tabular form. The examples were accumulated during the class discussion. In addition to least upper bound and greatest lower bound, I also included maximum and minimum, as described previously in these lectures.
The next piece of business is restating the last axiom we need to do "calculus": Completeness Axiom Suppose S is a non-empty subset of R. If S is bounded above, then S has a least upper bound.
This axiom carries considerable philosophical "baggage". The axiom
will get rid of the "holes", at least if we identify cuts with
holes. In the Dedekind approach, some cuts in Q seem to have nothing
in between (such as the sqrt(2) cut). The axiom is now generally but
not universally accepted. A reason for that is there are some
implications of this axiom which people find distasteful. How can we "identify" the least upper bound of a set? First, the text calls the least upper bound of S, sup(S), pronounced "soup of S". The greatest lower bound is inf(S). sup and inf are abbreviations of Latin words, supremum and infimum. sup(S) is unique. By that I mean if both Bob and Charlie are sup's of S, then Bob=Charlie. That's because if Bob is a sup, then it is an upper bound. Since Charlie is a least upper bound, Charlie<=Bob. Similarly, since Charlie is a sup, it is an upper bound, and if Bob is also a least upper bound, then Bob<=Charlie. Thus (Trichotomy) Bob and Charlie must be equal. Similarly, an inf of a set, if it exists, must be unique. To have a sup, a set must have an upper bound. If a set has a maximum, then the maximum is the sup of the set. But a set can have a sup without having a maximum. (Similar statements are true for inf's and minimums.) How can one try to "find" a sup? Well, if S is a non-empty set and if S is bounded above, then the completeness axiom says that S has a sup, and the discussion above declares that the sup is unique. But what "properties" does sup(S) have (besides the definition)? Here is something to think about. If w=sup(S), consider w-(1/2). Is w-(1/2) an upper bound of S? If it were an upper bound (subjunctive courtesy of Ms. Greenbaum), then it would be an upper bound less than w (since 1/2 is positive). But w is the least upper bound (the second part of the definition of least upper bound) so this is not possible. Therefore w-(1/2) is not an upper bound of S. What does it mean for something not to be an upper bound of S? That means there must be x in S with x greater than that number. That is, w-(1/2)<x. But notice that w, being an upper bound, must be greater than x. So we know that w-(1/2)<x<=w. Whew! It turns out that this weird intertwining characterizes sup's (and then, dually [?], inf's).
Theorem Suppose S is a non-empty subset of R which is bounded
above. An upper bound w of s is sup(S) if and only if for every
positive number e there is an element x of S so that
w-e<e<=w.
I more or less constantly use this theorem to find sup's of
sets. Here's a picture (?) of how I think (!!):
I think of the upper bounds of a set S as a collection of walls "marching down" from far to the right, getting closer and closer to S. They begin to pile up, and where they "stop" is sup(S). The content of the theorem is that if I want to move the walls the least little bit to the left, something in S will end up on the wrong (right) side. Now of course the picture I have drawn is somewhat simple. The S seems to have 3 pieces, and in most of the more interesting applications of all this that we will consider, S will have infinitely many pieces. So things will be complicated. The ideas I am outlining in this lecture took almost a century to shape. Although the reasoning is all displayed, it is often subtle, and may be difficult to understand. Here's one significant application.
THEOREM N (the natural numbers) has no
upper bound. I note that without the completeness axiom there are "models" of ordered fields where N can be "bounded above". The importance of the result is shown by the name used for it: the "Archimedean axiom". It isn't an axiom in our setup: we proved it! We will call it the "Archimedean Property". Some people like these models because the following corollary would not be true. Corollary (The death of tiny numbers.) The set S={x in R : x=1/n where n is in N} (just the set of numbers {1,1/2,1/3,1/4,1/5,...}) has sup(S)=1 and inf(S)=0. I will verify this next time. The following textbook problems will be due next Thursday: 2.3: 5 and 6 and 2.4: 2 and 8. | ||||||||||||||||||||||||||||||
| 2/5/2003 | I returned textbook homework (graded on the basis of 4 points
per problem). I returned the proofs of Bernoulli's inequality. I urged
students who had not done well on the proof of Bernoulli's inequality
and who also had time and energy to do the following: please read the
proof in the book. Please read my comments on the proof that you
handed in. Please then, flip the page of what you handed in, and in at
most 10 minutes, write a proof of Bernoulli's inequality. I will
regrade what you hand in tomorrow. I urge you to do this. I want your
work to improve and I am willing to help. I also gave out the next workshop problems. I strongly urged people to work in a group and to proofread each other's work. This is good practice. Covered with virus particles of the common cold, I persisted in trying to instruct. I proceeded further in the book. I discussed the content of section 2.2, absolute value. In this I totally followed the text, having little energy for anything else. The proofs I used are almost all in the text. The proof of the Triangle Inequality is quite "cute", and when I have taught the Triangle Inequality in more elementary courses, I have verified it using an argument of cases depending upon the "sign" of various terms. The most important results I deduced we will use repeatedly in the course. Here they are:
I tried feebly to apply the results on absolute value in a fashion that will be typical in this course. Consider the function f(x)=x3-15x2 on the domain [1,2] (that is the numbers x so that 1<=x<=2, what we will call a closed interval). After some stumbling around (thanks to several people for telling me that f has negative values on that interval!) I asked for the following: Find A and B so that 0<A<=|f(x)|<=B for all x in [1,2]. That is, I wanted positive upper and lower bounds for the absolute value of f's values on this interval. I wanted to use only the "technology" of the course as it so far existed. An upper bound is clear with the triangle inequality: |x3-15x2|<|x3|+|-15x2|. Now look at |x3|=|x|3. If 1<=x<2, then |x|3<=23. Also +|-15x2|=15|x|2, so, again if 1<=x<2, then 15|x|2<=15·22. Therefore we can use B= 23+15·22. An underestimate is a bit trickier. We have |A|-|B|<=|A+B|. To analyze |x3-15x2| we could take A=x3 and B=-15x2. Then we know that |x3|-|-15x2|<=|x3-15x2|. For an underestimate of this when x is in [1,2], for the |x3| part we want the smallest x. So the least this piece could be is 1 (or [sigh!] 13). To get a valid underestimate using the other part, we need to find the largest the piece to be subtracted is: so how big is the largest value of |-15x2| when x is in [1,2]? This is 15·22=60. So this elaborate effort results in an underestimate for |f(x)| of -59, which is not too satisfactory (logically, an absolute value is always non-negative, so telling us that such a number is bigger than -59 adds nothing). The "split" should be different. Take A=-15x2 and B=x3. Then an underestimate for |A| yields (for the smallest value of |A| when x is in [1,2]) 15. An overestimate for |B| yields 8 for the largest value of |B| when x is in [1,2]. And therefore we somehow have obtained an underestimate for |f(x)| when x is in [1,2]: |f(x)|>=15-8=7. A "beginning" student in this subject might find this all highly unsatisfactory. You can get some information with a certain sequence of algebraic "manipulations" and not get any with another, very parallel collection of manipulations. How can one tell what to do? I enlarged upon this by asking for positive over- and under- estimates of the same |f(x)| for x in the interval from [100,200]. Here the overestimate proceeds exactly as before with the triangle inequality, and we know that |f(x)|<=(200)3+15·(200)2. HOw about the underestimate? Well, it is useful to try to decide which of |x|3 and 15·|x|^2 will be the "bigger" piece when x is in [100,200]. Here I think the first, higher degree, term will be bigger. So I will write: |x|3-15·|x|^2<=|f(x)|. When x is in [100,200], then |x|3>=(100)3. The subtracted term must be overestimated (yes, this can certainly get confusing after a while!). So I know 15·|x|^2<=15(200)2. Now we finally get that if x is in [100,200] |f(x)|>=(100)3-15(200)2. This is positive (a fact verified by several public-spirited students since the instructor's head was clearly filled with ... phlegm or some result of having a cold). Note that the decomposition used for |f(x)| depended on the domain. Sigh. How can one tell what to do? I also mentioned that we can "invert" or take the multiplicative inverse of all of these inequalities and obtain positive over- and underestimates of 1/|f(x)| on [1,2] and [100,200]. Frequently one can concatenate (online dictionary: v.tr. link together (a chain of events, things, etc.) estimates of this type to work with rational functions, which are quotients of polynomials. I did a problem from the textbook: 2.2: 8(a). For which x is |x-1|>|x+1|. Several strategies were suggested for dealing with this inequality. We could use Trichotomy and an analysis of cases. That is, see where x-1>0 and etc.: lots of work. Or we could use the following idea: A>B>=0, if and only if A2>B2>=0. First, why should I believe it is true? It certainly isn't true without some assumption of non-negativity. For example, as supplied by Ms. Chan (?), if A=-1 and B=-5, then A>B, but A2=1<B2=25. But suppose they are both nonnegative. Then multiply A>B by A and also by B. We get A2>AB and AB>B2. Transitivity of > then shows A2>B2. On the other hand, if A=B, A2=B2, a contradiction, and if A<B similarly implies A2<B2, another contradiction. So we investigate |x-1|>|x+1|, an inequality involving non-negative numbers, by equivalently considering its square: (|x-1|)2>|x+1|2. We also know that (|A|)2=A2, so this becomes x2-2x+1>x2+2x+1. We can "simplify" by subtracting the same things from both sides, and then shift -2x over to get 0>4x. Multiply by the positive number 1/4 and we see that the x's which satisfy this inequality are the negative numbers. We can also try to understand this problem from a "geometric" "number line" point of view: we are looking for x's whose distance to 1 (that's |x-1|) is greater than their distance to -1 (that's |x+1|=|x-(-1)|). We'll move on next time. | ||||||||||||||||||||||||||||||
| 2/3/2003 | The instructor asked the students to write a proof of
Bernoulli's inequality.
Then we proved the following:
We have completed our math induction proof and the theorem is true. Comment I certainly do not recommend the outline of this proof as an algorithm to be implemented to find the maximum or to sort a list of 100,000 numbers. There are much faster ways to do such things! I commented that the logical outline of this proof (math induction!) is what's needed for most of the workshop problems. Problems 1 and 2 need more effort for the base case, while problem 3 needs more work for the inductive step. Most students successfully answered the question I asked last time, to find a set which had a max and no min. One simple answer is the following: {x in F : x is less than or equal to 1}. The question made me think of one of the background ideas of the subject: Richard Dedekind and his "cuts". So I detoured and discussed this topic. Consider F, a field satisfying the algebra axioms and the order axioms. The examples we know well are the rationals and the reals. There are actually many, many others, but here we'll try to distinguish between these two examples. In F, we will "cut" the number line, as if with a scissors, into two parts, a left part L and a right part R. So here are the requirements for such a cut:
Examples of cuts: In the second example, L has no minimum and has no maximum. R has a minimum of 1 and no maximum. In the third example, L has no minimum and has a maximum of 0. R has no minimum of 1 and no maximum. It is almost "clear" (considering the positive and negative integers) that any L will never have a minimum, and any R will never have a maximum. I asked if it was possible to find an example of a cut in which L has a maximum and R has a minimum. We discussed this a while. Let's consider such an example. Suppose the maximum of L is a and the minimum of R is b. Then a<b since a is in L and b is in R and these form a cut (requirement #4). What about the number c=(a+b)/2, suggested by Mr. LaCognata? Certainly c=(a/2)+(b/2). And since a<b and 1/2 is positive, we know a/2<b/2, so c<b/2+b/2=b. Because b is the supposed minimum of R, c can't be in R. But a similar argument shows that a<c so, since a is the maximum of L, c can't be in L. But now c, which is certainly a member of F, is in neither L nor R. This contradicts requirement #2 of being a cut. So we can't have a situation where the "left half" has a greatest element and the "right half" has a least element.
But what about the NO-NO situation, as I called it? That is,
the situation where L has no maximum and R has no
minimum. This can actually occur in the rationals. So here is
an example of a cut of Q: In fact, L always has what are called upper bounds (each element of R is one!) and R always has what are called lower bounds (each element of L is one!) and we need to eliminate the NO-NO case, which means eliminating holes. This will be one consequence of assuming (!) that there will always be least upper bounds (and greatest lower bounds) if sets are non-empty and appropriately bounded. Dedekind's original discussion of cuts is available: Essays on the Theory of Numbers, reprinted in English translation by Dover, with a cost of about 8 dollars. Much of the book is understandable to a high school student, as I explained in class. Surely some of the content and style is antique, but it is a neat source. I began discussing absolute value. I defined it as in section 2.2 of the textbook. I asked if "absolute value" was a function with domain F. What does this mean? I want to consider in FxF the collection of pairs: {(x,|x|) : x in F}. Is this a function? Is its domain all of F?
A function from A to B with domain equal to A is a subset W of
AxB with the following properties: | ||||||||||||||||||||||||||||||
| 1/30/2003 |
After an analysis of the moral positions of the instructor and the
students (showing that the students are much superior to the
instructor) I began the class. I first wanted to establish some common
methods for showing that "things" must be 0. In this, and in all that
follows in the course, we will assume that F is an ordered field (it
satisfies the 9 algebraic axioms and the 3 order axioms). I will
reserve using R for the real numbers until we get to the completeness
axiom.
Method #1 Suppose x is the sum of xj2 as
j goes from 1 to n. If x=0, then each of the xj's is 0 (for
j going from 1 to n).
Method #2 If x is nonnegative, and if, for all w positive,
z<w, then z=0.
Question Is there a smallest positive number? More precisely,
is there t in P so that if s is in P, then t is less than or equal
to s? Let's discuss the status of N and order. Since 1 is in P, and P is additively closed, we know 1+1 (which is called 2) is in P, and 1+1+1 (which is called 3) is in P, etc. Indeed, we could prove that N is a subset of P using mathematical induction. That is, the "counting numbers" are all positive. We also know that 2<3, since 3-2=1 is in P. How about 1/2? We showed last time that if a is in P, then 1/a is in P. So 1/2 is positive. We know that 0<1<2<3<(etc.) but we can also learn that (1/2)-(1/3)>0. Why is this true (I reserve "adding fractions" for the next workshop!)? Certainly 6·((1/2)-(1/3))=3-2=1>0. But also 1/6>0. So since P is multiplicatively closed, (1/6)·6·((1/2)-(1/3))>0 and (wow again!) 1/2>1/3. In fact, more generally (proof by induction!) if n and m are in N, then n/m is in P.
Question Is there a largest number less than 1? More precisely
we ask: is there z so that Then I drew some illegal pictures (officially illegal in this course, that is). I attempted to show the part of the "real line" just (?) to the right of 0 and showed by picture that there was no point to the right of 0 which was closest. I attempted to show the part of the line just to the left of 1 and tried to illustrate that there was no point just to the left of 1 which was closest.
Definition Suppose S is a subset of F. Then M is a
maximum of S if
Example(s) We begin with the simplest counterexample. The
empty set has no maximum and no minimum. That's because the
statements 1 and 3 are false for every element of F. The empty
set will constantly need to be ruled out as an example in many logical
statements. Question of the day Give an example of a set which has a maximum and which does not have a minimum. Next time I will prove that any finite nonempty set has a maximum and a minimum. But I will begin the class by asking students to write one of the following (I'll allow about 10 minutes):
| ||||||||||||||||||||||||||||||
| 1/29/2003 | I postponed the due date for the textbook homework until
tomorrow. I want to continue working with the algebraic axioms a bit
more.
Observation 8(-1)·a=-a.
Corollary (-1)·(-1)=1. Then I did some textbook problems. (Note that the "observation" above is 1b in section 2.1.) I think I did the following:
2.1 #2a) -(a+b)=(-a)+(-b)
2.1 #2d)-(a/b)=(-a)/b if b is not equal to 0.
2.1 4 If a·a=a, then either a=0 or a=1. I again wrote the order axioms, and stated that we were now going to investigate their consequences. (O1) and (O2) are called "P is closed under addition and multiplication."
Observation 9 If a is in F and a is not 0, then
a2 is in P.
Corollary 1 is in P. Now I can assert the following: the complex numbers cannot be made into an ordered field/ That's because i2 is -1, and on the one hand, squares are in P. But on the other hand, -1 is not in P: contradiction. Also the integers mod 5 cannot be made into an ordered field. THis is because 1 must be in P. And therefore by (O1) 1+1+1+1+1 (five times) must be in P. But in mod 5 addition, this is 0. And this contradicts Trichotomy.
Question of the day Suppose a is in F. Can -a be in
P? Notation/terminology Elements of P are called positive and if -a is in P, then a is called negative. We also write a>b if a-b is in P, etc. (All of this is in the text.)
Observation 74.3 If a is positive, then 1/a is positive.
We can add inequalities: if a<b and c<d, then a+c<b+d. We showed with an example (a=0,b=1,c=-1,d=0) that a similar multiplication of inequalities may be false. I returned the Entrance Exam and gave out the first workshop problems which must be done by groups of students. | ||||||||||||||||||||||||||||||
| 1/27/2003 | I wrote the axioms for a field, and for an ordered field, and
for a complete ordered field. Here they are:
The algebraic axioms (the axioms for a field; p.23)
The order axioms (the additional axioms for an ordered field; p. 25)
The completeness axiom (the additional axiom for a complete
ordered field; p. 37) All this will take quite a while to digest. Today we will primarily work on the first group of axioms, The algebraic axioms. Binary operation on a set s is a function whose domain is SxS and whose range is S. Actually, the traditional notation in, say, (A2) would be expressed in function notation as follows. If we suppose that A(a,b) means the binary operation "a+b", then (A2) would be rewritten A(A(a,b),c))=A(a,A(b,c)). That certainly looks more official, but maybe I will stick with what is traditional. The goal of the course is to recreate "calculus" using only the three groups of axioms above.
Examples and counterexamples
Obervation 1 The additive identity is unique. That is, if w is
any element of F so that, for some a in F, w+a=a, then w=0. Then students proved: Obervation 2 The multiplicative identity is unique. That is,
if w is any element of F so that, for some a in F with a not equal to 0 , wxa=a, then w=1.
Obervation 3 Multiplicative inverses are unique. That is,
suppose a is not 0 and a is in F. If there is w so that wxa=1, then
w=MI(a). The students proved:
Obervation 4 Additive inverses are unique That is, suppose a is in F. If there is w so that w+a=0, then w=AI(a). I then defined some conventional words. "-a" (minus a) is the unique additive inverse of a. "b-a" ("b minus a", subtraction) is just b+(-a). And if a is not equal to 0. 1/a (1 over a) is the unique multiplicative inverse of a. And b/a (b divided by a) is exactly bx(1/a). And usually I'll abbreviate axb by a·b or even just ab.
Observation 5 If a is in F, then -(-a)=a.
A similar result is true for multiplicative inverses:
Here is a more subtle result which uses (D). Observation 7 a·0=0 for all a in F. I remarked that we could already get some reward for this abstraction.
One equation
Two equations Next time, a bit more about algebra and then on to order. | ||||||||||||||||||||||||||||||
| 1/23/2003 | I briefly discussed possible responses to the fears
(worries?) of the survey. I urged students to question me as often as
they wish, see me outside of class, read the book, work on homework,
etc. Most students are experienced course takers (if that's the
phrase!) and I urge them to work actively here.
In this lecture I will discuss matters which are not vital to the understanding of the central subject matter of the course, but which certainly form part of the context that was known to people originating this "central subject matter". the ideas almost all come from the work of Georg Cantor in the late 19th century. Today we are interested in some rough measure of the size of a set. This is the material in section 1.3. If f:A->B is a function, I reviewed what injective or one-one and surjective or onto and bijective mean. In a loose sense, if f were injective, then (maybe!) A is "smaller" than B. If f were surjective, then A might be called "larger" than B. Finally, the existence of a bijection between A and B should mean, roughly, that A and B are the same size: we have, with f, a way of pairing up the elements of A and B. Formally, we say that A and B are the same size (the technical phrase the same cardinality, is used) if there is some function f:A->B which is a bijection. Pedagogical or psychological note When I wrote the official definitions of injective/surjective/bijective, the alert student may notice that after (and during) my writing of these definitions, I immediately asked for examples of functions that were not injective and surjective. For some reason, I and many other mathematicians find it easier to explore and understand a definition (and a theorem) by finding examples (well-chosen, one hopes!) that do not fulfill the defintion's requirements or the theorem's hypotheses, etc. Then I ran through a string of definitions, all in the book. The empty set (I'll use 0 as the empty set symbol here) is said to have 0 (zero) elements. If n is a positive integer, Nn is defined to be the integers {1,2,...,n}, an initial segment of N. Nn is said to have n elements. A set S is called finite if it is the same size as either 0 or Nn for some n in N. Then it is a theorem (proved with mathematical induction, and a bit irritating to get right!) that if a set is finite, either the set is empty (so it has 0 elements) or it is bijective to Nn for a unique positive integer n. So the "size" of a finite set is uniquely determined. This isn't totally obvious (why can't N12 and N324 be bijective -- it is true that they can't but I don't think that a proof is totally obvious!). A set is infinite if it is not finite (now there's a definition!). And another theorem: N is infinite. How would a "proof" of this go? The reason for the quotes is that I offered only an informal expression of a proof, not a detailed argument. If N were finite, then N is not empty, so it would have to be bijective with an initial segment, Nn. But if f:Nn->N were a bijection, look at the maximum of f(1) and f(2) and ... and f(n) and then add 1 ("take the successor"). This creates an element of N which is not f of anything (which is NOT in the range of f, more officially). So N is not finite. Then I looked at the mapping D:N->N which "doubles": D(x)=2x. D is not surjective (hey, 1 is not twice any positive integer), and D is injective. Its image is Eb, the even integers. So apparently Eb and N have "the same number of elements" or are "the same size". So an infinite set can be the same size as a proper subset of itself. I mentioned the famous (?) Hilbert Hotel, which has a room for every positive integer. If all the rooms are filled, then a new guest can be accomodated by asking everyone to move up one room: x->x+1. In fact, 23 new guests can get rooms (just x->x+23). And, more amazingly, an infinite number of new guests can get rooms (x->2x leaves the odd integers empty). There is actually a theorem here which I stated but which is honestly difficult to prove precisely: A set is infinite if and only if there is a bijection between the set and a proper subset of itself. This was easy to see in the specific case of N, but if we are given a "random" infinite set (what does random mean?), proving the result is not clear. I want big sets. N is infinite. Can we get a bigger set? I verified some bizarre facts. Fact 1 N and Z have the same number of elements. That is, there is a bijection between N and Z. I didn't give a specific formula (although this can be done). Specific formulas don't yield too much understanding. Instead, I "grouped" the elements of Z in a sort of strange way. I defined A0 to be {0}, and A1 to be {-1,1}, and A2 to be {-2,2}, etc. So An for n a positive integer was {-n,n}. Then the union of all of the An's is all of Z. "Clearly" I could "map" A0 to 1, and then the elements of A1 to 2 and 3, and the elements of A2 to 4 and 5, etc. So everything in Z gets mapped to distinct things in N, and everything in N is the image of something in Z. Fact 2 N and Q have the same number of elements. This is even more unbelievable, since the rationals look so darn much larger than the positive integers. Here I'll use the same outline as above. A0 is the set {0}. But now I will be trickier, and define An for n a positive integer in rather an involved way (I will use recursion in the definition). So here goes: if n is a positive integer, An is the collection of rational numbers a/b so that: a/b is not in any of the Aj's for j<n and |a| and |b| are both at most n. This is an involved definition. I asked for A1 and got {-1,1}. A2 was {-2,-1/2,1/2,2}. What I wanted people to see was that every rational number is eventually in exactly one of these pieces. For example, 355/113 must be in one of the Aj's where j is at most 355 (it could be in A355 itself, but it might already have been in one of the "earlier" ones). Then each piece Aj is finite (surely, since it can't be any larger than ... errr ... (2n+1)2, the number of a's and b's with |a| and |b| at most n). Then "pair up" N and Q by first matching each element in A0, then A1, then A2. etc. This uses up (?) all the elements of both N and Q. By now you should be confused, as confused as many of Cantor's contemporaries were when they first saw all of this. "Clearly" Q and N are different, but we just saw that their sizes are the same. Weird, weird ...
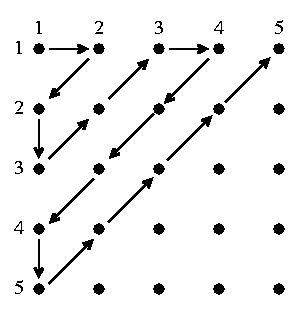
Fact 3 N and NxN have the same number of elements. For this I took a tour among the lattice points of a quarter of the plane (this is NxN). I started at the corner, and walked back and forth. This is weird and wonderful. Here is a picture of the beginning of the process, with just the first 5 rows and columns. Again, it is possible to write a formula for this "correspondance" (officially, this bijection) but to me the formula really conveys nothing immediately more useful. In fact, N and NxNxN have the same number of elements. Etc. Is there no bigger set? I want a bigger set! The way to get one is to consider the power set "construction".
If S is a set, then the power set of S, called P(S) here, is
the set of all subsets of S. For example, if S={a,b,c} then P(S) is
{0,{a},{b},{c},{a,b},{a,c},{b,c},{a,b,c}}. This is an 8 element set,
and all of the darn braces ({ and }) are needed, because this is a set
of sets! I then asked
Fact 4If S is any set, then there is NO surjection from S to
P(S). This is Theorem 1.3.13 in the book, and I gave the proof in the
book. It is an amazing proof, which is relevant to studies in physics,
philospohy, computer science (most notably in the Halting Problem),
and much of mathematics. The self-referential nature of the proof is
discussed at length in the book Gödel Escher Bach by
Hofstdter. The key idea: suppose F:S->P(S) is a surjection. Then
consider the set T given by: x is in T if both x is in S and x
is not in F(x). Then T is certainly a subset of S. If F is a
surjection, what can we say about the element w of S which has F(w)=T?
There must be such a w since we are supposing that F is a
surjection. If w is in T, then w is in F(w), but this means w doesn't
satisfy the description of an element of T, so w is not in T
(contradiction). If w is not in T, then w is not in F(w), but then w
satisfies the description of an element of T so w is in T
(contradiction). Therefore no such w can exist, so there is no
surjection. (Old idea: who shave the barber in a village where there
is one barber and the barber shaves anyone who doesn't shave himself?)
Therefore P(N) is bigger than N. And P(P(N)) is bigger than
that, etc. So there can somehow be arbitrarily (?) big sets.
Now that you are confused I will stop. What I'd like 311 students to get
out of this is that the most naive measure of sizes of sets already
leads to complications. I would like you to have some idea of answers
to the following questions.
| ||||||||||||||||||||||||||||||
| 1/22/2003 | Introduction of the instructor and the course.
I introduced myself and mentioned the course name. I requested student
information. I asked for a session of free association about the course, and collected some written student reactions. I asked what students thought about the course, and what they expected from it. A somewhat vague tabulation of the results yielded what follows. I give brief descriptions what I thought each answer meant.
I was asked what my reasons might be for a student to take the course. I had anticipated this question and replied:
Although we will prove almost everything in the course, I wanted to give some background and make sure we agreed on notation. So we started with N. This is the natural numbers, which in this course and with this text will be the set {1,2,3,4,...}. How can we characterize this set? It is inductive. Basically, it is the smallest set with the following property: 1 is in the set, and for each element of the set, there is a different element called the "successor". The set has the following property: If S is any subset of N, and if
This defining property is used in proofs by "mathematical induction". It is equivalent to the following "well-ordering property": every non-empty subset of N has a least element. (Trick here: the statement is false without "non-empty"!) The using mathematical induction and the "successor" function, operations of addition and multiplication can be defined on N. Defining these corrrectly is a serious undertaking, and one which I neither want nor am prepared to undertake (students interested in such details can see the book Foundations of Analysis by Edmund Landau). Again, with some effort, it can be shown that these operations (really functions on NxN) are both commutative, associative, etc. and that 1 is a multiplicative identity. The equation a+x=b can be solved only "sometimes" in N. So we "extend" the number system to Z, the Integers: as a set, Z could be thought of as two copies of N along with an extra element, 0. One copy of N could be thought of in red and one, in blue. The red elements could be thought of as being negative and the blue, as positive. Then additional work allows us to extend addition and multiplication to Z, with 1 as a multiplicative identity. All equations of the form a+x=b can be solved. The next desire is to solve equations of the form a·x=b. This leads us to the "larger" (?) set Q, the Rational Numbers. In order to stretch our imaginations and to use some of the abstraction that students are supposed to have under control, I suggested that the rationals could be "constructed" in this way: take the product of ZxZ\{0}. So this is pairs of integers (a,b) with b NOT equal to 0. In this set introduce an equivalence relation: (a,b)~(c,d) if and only if ad=bc. We experimented with this a while (it comes from the fact that if ad=bc, then the equations ax=b and cx=d should have the "same" solution, represent the same rational number). A rational number is an equivalence class of ZxZ\{0} using ~, and the set of all rational numbers, Q, is the set of all such equivalence classes. Introducing addition and multiplication into Q with this definition is lengthy, and (in this course) I am not particularly interested in checking the details. Everything works (see Landau's book!). The integers fit into this Q by the mapping w->[(w,1)]. This is a one-to-one or injective mapping. By the way, just understanding that succession of symbols means that you have mastered quite a lot of abstraction. The rational number a/b correspnds to [(a,b)]. I mentioned one of the most famous results of mathematics: sqrt(2) is irrational. Or, more formally, there is no rational number a/b whose square is 2. This is Theorem 2.1.4 in the text (please look there if you've never seen it!). This led me to consider the following function, whose domain is the rationals, Q, and whose range is just {-1,1}. (I did mention that functions are "officially" supposed to be ordered pairs, etc., but that I would usually be a bit lazy and define functoins by how they "map" elements in their domains: there is an implied listing of the ordered pairs.) So F(x) is 1 if x2>2 and F(x) is -1 if x2<2 It took a while to understand this function (I should give credit to T. W. Körner from whose Cambridge University lectures I "borrowed" this example). I emphasized that this function is very computable for every number in its domain. We drew a graph of the function. The graph was drawn in the QxQ plane. We had trouble understanding the graph. Even worse was the fact that, if we allow the standard definition of derivative, then F' exists at every point (rational numbers can get small so limits as "h->0" can be considered!) and that F'(x)=0 for every x! Note that F, although defined "everywhere" with derivative existing and equal 0 "everywhere", is not constant! This should be somewhat distressing. Another example, similar in spirit, is the function G(x)=x2-2, with domain and range both Q. We drew a graph, and this "parabola" did not intersect the horizontal axis! What's going on? All the natural geometric and calculus "facts" seem to be violated by these rather simple examples. The major content of the course is the transition or enlargement of Q to R, the real numbers, and understanding this and its consequences will be the principal task before us. I handed out the Entrance Exam. I urged students to begin reading chapter 1, and remarked that 1.1 and 1.2 should be familiar to them. I would try to discuss, more or less informally, the content of 1.3 next time, and would really begin the serious, proof-emphasizing part of the course next week. | ||||||||||||||||||||||||||||||
 Here is a somewhat poetic (?) view of the theorem. n increases as
pictures of the real line descend. I am trying to illustrate how
bn is "forced" to converge to x.
Here is a somewhat poetic (?) view of the theorem. n increases as
pictures of the real line descend. I am trying to illustrate how
bn is "forced" to converge to x.