March 5
We began the linear algebra part of this course on February 12. I asked some questions which were not answered by students in the class with a large amount of certainty. Today I returned to these questions after the linear algebra sophistication (!) we've gotten in the last three weeks. I would like to answer each question, and give a brief discussion supporting the section. The discussion will not be detailed but I would like it to be persuasive enough.
Old question #1
If (0,0,0,0) and (1,2,4,0) are solutions of 7 linear equations in
4 unknowns, must there be other solutions?
Discussion and answer
In matrix form, the equations are AX=Y where Y is a 7 by 1 column
vector and X is a 4 by 1 column vector. A is therefore a coefficient
matrix which is 7 by 4. Since (0,0,0,0) is a solution, we learn that Y
must be the 7 by 1 vector of 0's, and that this system is AX=0, a
homogeneous system. The collection of solutions, S, of a homogeneous
system is a subspace, in this case a subspace of R4. The
dimension of S gives a rough measure of how big S is. Here the
dimension of S is one of the integers 0 or 1 or 2 or 3 or 4. We're
also told that (1,2,4,0) is a solution, that is, it is in S. Therefore
S has at least dimension 1. And since S is a subspace, any scalar
constant multiplying (1,2,4,0) must also be a solution. Therefore if t
is any real number, (t,2t,4t,0) is a solution. The answer to the
question, "Must there be other solutions?" is therefore, yes, there
are infinitely many other solutions. I note also that the coefficient
matrix, A, of the homogeneous system AX=0 which we know is 7 by 4,
must have rank somewhere between 0 and 4. There is no restriction on
the rank (I messed this up in class!). Let's just look at the extreme
values for simplicity. If rank A = 0 then A is the 0 matrix, and
certainly (t,2t,4t,0) solves AX=0. If rank A =4, then the coefficient
matrix could look like (in
RREF)
(1 0 0 0 -1 0 0 0) (0 1 0 0 -2 0 0 0) (0 0 1 0 -4 0 0 0) (0 0 0 1 0 0 0 0)and this also has (t,2t,4t,0) as some solutions. So I don't think we can say much about the rank of A in this case.
Old question #2
Can there be exactly 5 distinct solutions to a collection of
340 linear equations in 335 unknowns?
Discussion and answer
I inserted the italicized word distinct above. I think I meant
that "Could there be exactly 5 distinct solutions?", not just 5
solutions, which by linguistic indefiniteness (!) could turn out to be
just one solution with 5 different names.
We have another system here, which again in matrix form could be
written AX=Y where is Y a 340 by 1 column vector, and X is a 335 by 1
column vector of unknowns, and A must therefore be a coefficient
matrix which is 340 by 335. A contains more than 100,000 (I think!)
numbers. I claim that the answer to the question is "No." I will
attempt to convince you that the answer to the question is "No" by
assuming that AX=Y has five distinct (pairwise unequal!) solutions and
showing that there can be many others.
So suppose X1 and X2 and X3 and
X4 and X5 all satisfy AX=0. Then Mr. Obbayi who I believe was thinking
linearly suggested that we look at the column vector
W=X1-X2. What do we know about W? Well,
AW=A(X1-X2)=AX1-AX2=Y-Y=0.
Therefore this W is a solution to the associated homogeneous
system. But each one of the Xi's is a particular solution
to AX=Y. Therefore any of them plus a solution to the homogeneous
system is a solution to AX=Y. Remember again that solutions to the
homogeneous system form a subspace. Therefore
X3+t(X1-X2) is a solution to AX=Y for
any t. Hey: there are lots and lots of values of t, and since the
solutions are distinct, X1-X2 is not
0. Therefore we have created infinitely many different solutions to the
original system. That's more than 5!
Old question #3
Must a system of 30 homogeneous linear equations in 40 unknowns have
some non-zero solution?
Discussion and answer
So we have again AX=Y. Now Y is 30 by 1, and, in addition, Y is 0 (all
zero entries) since this is a homogeneous system. X is 40 by 1 and A
is 30 by 40: it has 1200 entries. We need to describe some aspects of
the solution space of AX=0. This collection of X's is a subspace of
R40. Initially, it could have any dimension, from 0 to
40. The answer to the question will be "Yes" and to give some
supporting evidence we must show that the dimension is >0. Since
this is a homogeneous system, we can look hope that the
RREF will contain some information.
And since the system is homogeneous, we don't need to "augment" the
coefficient matrix. So:
(BLOCK OF 1's AND | JJJJJJ UU UU NN N K K)
(0's SORT OF AN | JJ UU UU N N N KK )
A~~...~~(IDENTITY MATRIX | JJJJ UUUUUU N NN K K)
(------------------------------------------------)
( MAYBE HERE SOME ROWS OF 0'S )
The most important fact to remember her is that A is a 30 by 40
matrix: it is "wider" than it is "high". The rank of A is the number
of 1's in the left-upper corner BLOCK. How big can the rank
be? The largest it can possibly be is 30, the "height" of the
matrix. Now consider the width. Since that is 40, the chunk I called
JUNK (pretty poetry!) must be at least 40-30 columns
wide. That means (if you think about the equations that the rows
represent) at least 10 variables can be freely specified (uhh,
x31 through x40, I think, as we usually number
them) in the solution space of AX=0. So the solution space has
dimension at least 10. Therefore there are "some" non-zero solutions,
in fact, at least a 10-dimensional space of non-zero solutions.
I wanted to revisit those questions so I could attempt to convince you that we've done something worthwhile in the last few weeks. Certainly part of what we've done is learn vocabulary ("spanning" and "subspace" and "linear combination" and "forsooth") but I hope we've also gotten enough understanding that we could answer some questions which seem formidable.
Mr. Marchitello kindly wrote his solution to yesterday's QotD, which will be useful in today's work. The system was
2x1+3x2=y1 5x1-1x2=y2and here is the row reduction:
(2 3|y1)~(1 (3/2)| (1/2)y1 )~(1 0|(1/17)y1+(3/17)y2) (5 -1|y2) (0 -(17/2)|-(5/2)y1+y2) (0 1|(5/17)y1-(2/17)y2)What can we learn from this computation? As I remarked, there are no "compatibility conditions" to be satisfied, so there is a solution for any choices of y1 and y2. But how many solutions are there? Well, again think about "a particular solution plus any solution of the associated homogeneous system". Here the associated homogeneous system is row equivalent to the 2 by 2 identity matrix,
(1 0) (0 1)where there's no "junk" in the sense of the earlier discussion. The only solution of the associated homogeneous system is the trivial solution, (0,0). So for every choice of the pair (y1,y2) there is exactly one solution (x1,x2). That solution is given by those two linear combinations, so x1=-(5/2)y1+y2 and x2=(5/17)y1-(2/17)y2.
This situation is very nice and very important. I need to discuss it
in general.
DEFINITION
The n by n identity matrix has 1's on the diagonal and 0's
elsewhere. I will call it In. It is both a left and right
multiplicative identity for matrices where the matrix product is
defined. For example, where n=3
(1 0 0) I3=(0 1 0) (0 0 1)and if
(a b c) (d e f) (p q) A=(g h i) B=(r s) (j k l) (t u) (m n o)then you should do enough of the matrix multiplication to convince yourself that AI3=A and I3B=B.
DEFINITION Suppose A is a square matrix, say n by n. Then B is an inverse of A if AB and BA are both In. B is frequently written as A-1. If I know that B is the inverse of A, and if I want to solve the matrix equation AX=Y, then X=BY, very simple.
It is possible find inverses "by hand" for small square matrices. Look:
(2 3|1 0)~(1 (3/2)| (1/2) 0)~(1 0|(1/17) (3/17)) (5 -1|0 1) (0 -(17/2)|-(5/2) 1) (0 1|(5/17) -(2/17))So
((1/17) (3/17)) ((5/17) -(2/17))is a multiplicative inverse to
(2 3) (5 -1)You can check this claim very easily by multiplying the matrices. Why does this method "work"? Of course, I am just duplicating what Mr. Marchitello did above. The different columns are just place-holders for the variables y1 and y2. The inverse remarkably (?) appears because we are just writing out the coefficients for the linear combinations solving the original system of linear equations.
Algorithm for an inverse and some ideas
Suppose A is an n by n matrix. We can attempt to get an inverse by
doing the following: write the augmented matrix
(A|In) and then use row operations on A, pushed
through the whole n by 2n augmented matrix, to try to get the n by n
identity matrix appear on the left-hand side. If the result is
(In|B) then B is the guaranteed inverse of A.
From this we can deduce some facts and uses:
- If A is an n by n matrix, then A will have an inverse exactly when A has rank=n.
- If A is an n by n matrix, then A will have an inverse exactly when its rows are all linearly independent. Then the rows will be a basis of Rn.
- If A has an inverse B, then the equation AX=Y will have exactly one solution, and that solution X is BY. That's because B(AX)=BY, but B(AX)=(BA)X=InX=X, so X must be BY.
A silly (?) example
I wrote the following on the board. Suppose A is the matrix
( 7 1 3 -1) ( 6 3 0 2) (-2 2 3 1) ( 6 -4 -1 -4)and B is the matrix
( -13 9 17 12) ( 98 -67 -128 -90) ( -38 26 50 35) (-108 74 141 99)I assert that B is A-1. How would you verify this rather peculiar claim (yeah, I will tell you how I got this example, soon). What should we do and how difficult would the task be? We could multiply the matrices which is not much work on a computer, since I have explained that matrix multiplication and vector dot products are often acknowledged by both software and hardware these days, and are very fast. By hand, we could pick out a row, say, in A, and dot it with a column in B. I forgot which candidates I took in class, but let me try the third row in A and the third column in B.
A B, the candidate
for A-1
( 7 1 3 -1) ( -13 9 17 12)
( 6 3 0 2) ( 98 -67 -128 -90)
(-2 2 3 1) ( -38 26 50 35)
( 6 -4 -1 -4) (-108 74 141 99)
We compute:
(-2)(17)+(2)(-128)+(3)(50)+(1)(141)=-34-256+150+141=-280+281=1.
Amazing and just as we hoped! The diagonal entries in the product of
these matrices should all be 1. What about off-diagonal entries. The
dot product of such a row vector and a column vector should be
0 (the vectors should be orthogonal or perpendicular). We could try
again a random (?) entry:( 7 1 3 -1) ( -13 9 17 12) ( 6 3 0 2) ( 98 -67 -128 -90) (-2 2 3 1) ( -38 26 50 35) ( 6 -4 -1 -4) (-108 74 141 99)Again we compute:(-2)(9)+(2)(-67)+(3)(26)+(1)(74)=-18-134+78+74=-152+152=0.More amazing! This says that the (32) entry in the product (third row and second column) is 0. These vectors are perpendicular. "Clearly" -- no, not at all! I think most of this stuff is almost miraculous.
Comments
No, I am not a magician. I used Maple but I must tell you that even with Maple's assistance producing this example was not exactly easy. First, the inverse of a matrix with integer entries usually involves rational numbers which are not integers. We have already seen that, with the wonderful (?) "17" example. Well, next week we shall see that there is an approach distinctively different from this algorithm which will produce the inverse to a matrix. There's an actual formula for the inverse, and the determinant of the matrix is a very important ingredient in the formula. By the way, deciding when to use the formula (which is explicit but can be very clumsy) and when to use the algorithm is difficult. So here I found a 4 by 4 matrix with integer entries whose determinant just "happens" to be 1. If you want a really wonderful word to thrill people at your next social encounter try unimodular: a square matrix is unimodular if it's determinant is 1. O.k., even with all this and with Maple, I had to work a bit to produce the example I showed you. It wasn't a lot of work, but it was some work.
Bad matrices: no inverses
I asked for the simplest example of a matrix which does not
have an inverse. A good deal of discussion followed, but Mr. Dupersoy suggested the 1 by 1 example:
(0). I agreed this example was certainly smallest. I asked
for a larger example, and was given
(0 0) (0 0)which I said wasn't too original. Then Mr. Cohen (I believe it was he) suggested
(0 0) (0 1)which has rank 1 and since 1<2, this matrix has no inverse. Also
(0 1) (0 1)has no inverse. Wow. Matrices which don't have inverses are sometimes called singular. Singular matrices have low rank. Good matrices have high rank, and those square matrices which are highest rank are invertible (have inverses).
Please note that according to the dictionary, the word "rank" used as an adjective can mean "foul-smelling, offensive, loathsome, indecent, corrupt." Therefore some sentences using the word "rank" can be understood in a humorous way.
I was asked if only square matrices have inverses. In the context of this course and this text, my answer is "Yes". In fact, there are one-sided inverses for non-square matrices which some students may meet during computations. We won't see these ideas here.
The ideas I suspect M&AE students will need concern matrices with symbolic coefficients. This is so they will be able to do computations concerned with changing coordinates (and recognizing symmetries) more easily. The next two (and last two!) examples I considered are of this type.
Strange example #1
Suppose that a and b are real numbers, and G is the matrix
(0 a a 0 0) (1 0 0 b b) (0 1 0 0 0) (0 0 2 2 2) (0 0 1 1 1)Question For which values of a and b is this 5 by 5 matrix invertible?
Answer O.k., this was wonderful in the sense of how distracting the a and b stuff could be. People looked and looked. Finally, I think Mr. Hunt remarked that the last two rows were identical so the column rank was less than 5. Indeed, I agreed with him, and said that there were some important ideas in his statement. First, there is the fact, not at all obvious, that the row rank and the column rank are always the same. That is, the number of linearly independent rows equals the number of linearly independent columns. Second and easier, recognizing that column 4 = column 5, so that the column 5 is at most 4, can't be 5, so that this matrix can never have an inverse, for any values of a and b! I have not discussed column rank etc. because this is mostly a row-oriented text, and we just don't have time for a full treatment of all of linear algebra.
Is there a "row argument" supporting the statement that the rank is less than 5? Well, yes, far away from the distraction of the a's and b's. Row 4 and row 5 are linearly dependent (one is a scalar multiple of the other) so that in row reduction we will certainly get a row of 0's. The rank will definitely be less than 5, so there are no values of a and b which would allow this matrix to have an inverse.
Strange example #2
Suppose that a and b are real numbers, and H is the matrix
(0 a a 0 0) (1 0 0 b b) (0 1 0 0 1) (0 0 2 1 1) (1 0 1 0 0)Question For which values of a and b is this 5 by 5 matrix invertible?
Answer Here it is clear that if a is 0 then the rank is at most 4. What happens if a is not 0? I will use some row operations, beginning with exchanging rows so that I'll avoid the symbolic entries for as long as possible! (Avoid thinking! Avoid effort!)
Warning The following discussion is complicated.
Here I will begin by rearranging the rows, and then I clear up the first column and then the second column.
(0 a a 0 0) (1 0 0 b b) (1 0 0 b b) (1 0 0 b b) (1 0 0 b b) (0 1 0 0 1) (0 1 0 0 1) (0 1 0 0 1) (0 1 0 0 1)~(0 0 2 1 1)~(0 0 2 1 1)~(0 0 2 1 1) (0 0 2 1 1) (1 0 1 0 0) (0 0 1 -b -b) (0 0 1 -b -b) (1 0 1 0 0) (0 a a 0 0) (0 a a 0 0) (0 0 a 0 -a)Now I'll try to clear up the third column, carefully. We need to be very careful with the symbolic entries.
(1 0 0 b b) (1 0 0 b b) (1 0 0 b b) (0 1 0 0 1) (0 1 0 0 1) (0 1 0 0 1) (0 0 2 1 1)~(0 0 1 1/2 1/2)~(0 0 1 1/2 1/2) (0 0 1 -b -b) (0 0 1 -b -b) (0 0 0 -b-1/2 -b-1/2) (0 0 a 0 -a) (0 0 a 0 -a) (0 0 0 -a/2 -3a/2)I'll begin by exchanging the fifth and fourth rows (the algebra is simpler!), and here I need to assume that a is not equal to 0.
(1 0 0 b b) (1 0 0 b b) (1 0 0 0 -4b) (0 1 0 0 1) (0 1 0 0 1) (0 1 0 0 1) (0 0 1 1/2 1/2)~(0 0 1 1/2 1/2)~(0 0 1 0 -1) (0 0 0 -a/2 -3a/2) (0 0 0 1 3) (0 0 0 1 3) (0 0 0 -b-1/2 -b-1/2) (0 0 0 -b-1/2 -b-1/2) (0 0 0 0 2b+1)We are almost done. I will assume now that 2b+1 is not equal to 0.
(1 0 0 0 -4b) (1 0 0 0 -4b) (1 0 0 0 0) (0 1 0 0 1) (0 1 0 0 1) (0 1 0 0 0) (0 0 1 0 -1)~(0 0 1 0 -1)~(0 0 1 0 0) (0 0 0 1 3) (0 0 0 1 3) (0 0 0 1 0) (0 0 0 0 2b+1) (0 0 0 0 1) (0 0 0 0 1)So the rank is 5 exactly when both a and 2b+1 are not zero.
By the way, if these numbers are not zero, then H has an inverse. What is the inverse? Well, I tried working it out using our row reduction algorithm. The reductions got complicated, and I lost my eagerness to do the work. So ...
with(linalg):
H:=matrix(5,5,[0,a,a,0,0,1,0,0,b,b,0,1,0,0,1,0,0,2,1,1,1,0,1,0,0]);
[0 a a 0 0]
[ ]
[1 0 0 b b]
[ ]
H := [0 1 0 0 1]
[ ]
[0 0 2 1 1]
[ ]
[1 0 1 0 0]
inverse(H);
[ 1 b 2 b ]
[ 0 ------- 0 - ------- ------- ]
[ 1 + 2 b 1 + 2 b 1 + 2 b ]
[ ]
[ 1 b 1 ]
[ 1/a ------- 0 - ------- - -------]
[ 1 + 2 b 1 + 2 b 1 + 2 b]
[ ]
[ 1 b 1 ]
[ 0 - ------- 0 ------- ------- ]
[ 1 + 2 b 1 + 2 b 1 + 2 b ]
[ ]
[ 3 b - 1 3 ]
[ 1/a ------- -1 - ------- - -------]
[ 1 + 2 b 1 + 2 b 1 + 2 b]
[ ]
[ -1 b 1 ]
[ -1/a ------- 1 ------- -------]
[ 1 + 2 b 1 + 2 b 1 + 2 b]
[ ]
Notice how the conditions we know appear implicitly in the
matrix. That is, there's division by a, so a shouldn't be 0, and
division by 1+2b, so that shouldn't be 0 also. Maple can find
symbolic matrix inverses, and Maple rarely gets hysterical!
The QotD was the following (with instructions phrased so that
Mr. Malek would not be able to just
write the answer with a calculator):
Use row operations and exact rational arithmetic to find the inverse
of the matrix
(3 3 3) (3 1 0) (3 0 -1)I remarked that this matrix was symmetric (that is, when you "reflect" it across the diagonal of 11 22 33 terms you get the same matrix), and it turns out that the matrix inverse will also be symmetric. Also the final answer will only involve fractions whose bottoms are 3 (yes, I fouled up and wrote 2 at first!).
Please read the textbook and hand in 6.7:1, 5 and 6.9: 7, 13.
March 2
(-15 0 -42 -6 -21 -83) ( 30 0 84 0 24 -6) (-15 0 -63 2 -8 27)which is row equivalent to
(1 0 0 0 2/5 5/3) (0 0 1 0 1/7 -2/3) (0 0 0 1 5 -2 )There is a free variable because of the second column. The first "equation" implied by the first row is x1=-(2/5)x5-(5/3)x6. With this in mind Mr. Gradziadio observed that the coefficient matrix implied that there were 3 equations in 6 unknowns, and that the rank of the matrix was 3. The collection of vectors (x1,x2,x3,x4,x5,x6) which are solutions to the homogeneous system are a subspace. The dimension of this subspace is 3. A basis for this subspace is (0,1,0,0,0,0) (because of the column of 0's) and (-2/5.0,-1/7,-5,1,0) (put x5=1 and x6=0) and (-5/3,0,2/3,2,0,1) (put x5=0 and x6=1). A typical vector which solves the homogeneous system is x2 multiplied by the first vector, and x5 multiplied by the second vector, and x6 multiplied by the third vector. The easiest way to see this is by writing out the linear system abbreviated by AX=0. We can "see" that the three vectors named are linearly independent by looking at the second, fifth, and sixth components of the vectors (they form a matrix called I3, a 3 by 3 identity matrix) whose only solutions are 0 and 0 and 0.
Now, again, we begin: the study of solutions of inhomogeneous systems of linear equations. I first observed that non-linear equations are not too well-behaved. For example, even in one variable, the equation x2=a has 0 (a=-1) or 1 (a=0) or 2 (a=1) real solutions.l There are lots of ways of understanding that, but all of the ways take some effort. It is p0artially my job to convince you that the case of linear systems, even in high dimensions, is actually much easier.
I started with a very detailed analysis of an example. The example was extremely carefully and delicately (?) chosen. Here is the system of equations:
2x1+1x2+1x3+4x4+4x5=y1 2x1+2x2-4x3+4x4+6x5=y2 2x1+0x2+6x3+4x4+2x5=y3The questions I wanted to discuss included these:
For which triples (y1,y2,y3) will there be solutions of this specific system?
If there are solutions, can we describe the solutions in some systematic fashion?
As in the homogeneous case, changing to RREF will help a great deal. In this case we need to carry along the right-hand sides of the equations, so that we can interpret our final results in terms of them. We take the coefficient matrix and write another column, and call the result the augmented matrix. The row operations will result in a system of equations with the same collection of solutions, and maybe the solutions will be easier to understand after we are done (that will be true).
( 2 1 1 4 4 | y1) ( 2 2 -4 4 6 | y2) ( 2 0 6 4 2 | y3)It is conventional to put some sort of separator between the coefficients and the "right-hand sides". Most texts use |. I challenged the class with an announcement. The system can be solved for exactly one of these vectors: (3,2,1) and (2,3,1). Which vector, why not the other one, and what are the solutions "like"?
Row reduce the coefficient matrix:
( 2 1 1 4 4 | y1) (1 1/2 1/2 2 2 |(1/2)y1) ( 1 0 3 2 1 | (3/2)y1-(1/2)y2) ( 2 2 -4 4 6 | y2)~(0 1 -5 0 2 | y2-y1)~( 0 1 -5 0 2 | y2-y1 ) ( 2 0 6 4 2 | y3) (0 -1 5 0 -2|y3-y1) ( 0 0 0 0 0 | y3+y2-2y1)Well, the typesetting isn't perfect but I hope you get the idea. First, I would like to mention that maybe the coefficient matrix which is now in RREF might be a bit familiar. It is the first example I analyzed in detail last time.
The additional detail of the last column is what we will look at now. But what the heck does the last row mean? It abbreviates a linear equation, which I will write out in detail with the +'s and the variables:
0x1+0x2+0x3+0x4+0x5=y3+y2-2y1When we dealt with homogeneous systems, such a row had little information. But now we seem it imposes a condition the the y-variables must satisfy if the system of equations could have a solution.
Compatibility conditions
I learned to call a condition like
y3+y2-2y1=0 a compatibility
condition
(the dictionary says "compatibility" is "able to coexist; well-suited;
mutually tolerant"). Your textbook says that a selection of the
variables where the compatibility condition is satisfied makes the
system consistent, and otherwise the system is
inconsistent.
Recall the triples (3,2,1) and (2,3,1). The equation
y3+y2-2y1=0
is not satisfied
if y1=3 and y2=2 and y3=1. It becomes
1+2-2(3)=-3-0, which is false. Therefore (3,2,1) cannot be a solution
of the original system. I can't easily "see" this fact just by looking
at the original system. What about (2,3,1)? The compatibility
condition becomes 1+3-2(2)=0, which is true. Be careful of a possible
logical trap here: this alone by itself doesn't guarantee that the
original system has a solution for (2,3,1). It just says that (2,3,1)
passes this "test" or satisfies this criterion or something.
[The instructor discussed this point of logic
in terms of driving strategy: "Slower cars should be on the right, so
therefore (??!!) cars are the right should/must/might be slower ..."
while this is certainly a false implication, it might be helpful
under certain circumstances ...]
Finding a solution
So does (2,3,1) have some solution to the system? Consider the system
in RREF. The third equation is
satisfied. The other two are
x1 =(3/2)y1-(1/2)y2)-3x3-2x4-1x5
x2= y2-y1 +5x3+0x4-2x5
I just want to get some solution of the equation for the vector
(2,3,1). Here is one way: make x3=0 and x4=0 and
x5=0. Plug in y1=2 and y2=3 and
y3=1 in on the right hand side, where the green stuff is. Then
x1=(3/2)(2)-(1/2)(3)=3/2 and x2=2-3=-1. Indeed
(!) if you just "plug in" the values (3/2,-1,0,0,0) into the original
system:2x1+1x2+1x3+4x4+4x5=y1 2x1+2x2-4x3+4x4+6x5=y2 2x1+0x2+6x3+4x4+2x5=y3you will get 2(3/2)-1+0's=2 (the desired value of y1) and you will get 2(3/2)+2(-1)=1 (the desired value of y2) and you will get 2(3/2)+0's=3 (the desired value of y3). This isn't magic but to me it seems quite close!
Other solutions
We experimented with other solutions, The students were revolted by my
request that we think if there are solutions when x3=Pi and
x4=sqrt(2) and x5=e. There are solutions, and
they were easy to write. What is the "structure" of all
solutions? Here matrix notation comes in handy. Suppose I know that
AX=Y and AW=Y where Y is the vector (2,3,1) in column form. Then I
know that AX-AW=Y-Y so (undistributing?) A(X-W)=0, and X-W is a
solution of the associated homogeneous system which which had
previously analyzed in detail. So if W is any
particular solution of our system, such as the vector
Z=(3/2,-1,0,0,0),
we can get
the general solution by adding on any solution of the
homogeneous system, which was the span (all linear combinations) of
three vectors which I called u and v and w. So
all solutions are exactly Z+au+bv+cw for
any choice of numbers a and b and c.
Digression back to 244
Another example, with a square coefficient matrix
What do we know? There is no compatibility condition. Any 4-tuple of
y's has a solution: just plug in the y-coordinates on the right of the
RREF and you'll get the
corresponding x-coordinates. How many solutions are there? Well,
that's the same as asking what the solutions of the associated
homogeneous equation are. In this case, if all of the y's are 0, then
all of the x's are 0. The subspace of homogeneous solutions is just
the zero vector, {0}, and its dimension is 0. The only solution of the
associated homogeneous system is the trivial solution. So this is a
very nice case: all outputs in R4 are possible, and each
output corresponds to exactly one input. This special case is very
important, and we will learn an algebraic tool (the determinant) which
may help us recognize when this occurs.
The QotD asked students to do row reduction of a 2 by 2
system:
I checked my answer with Maple:
What are all solutions of the ODE y''+y=xex? (This is not
an initial value problem -- I am just asking for some useful
description of all solutions. Well, y''+y=0 has as solutions
a sin(x)+ba cos(x). These are the collection of solutions
of the associated homogeneous equation. Now, oh my goodness, we just
guess that one solution of y''+y=xex is
(1/2)x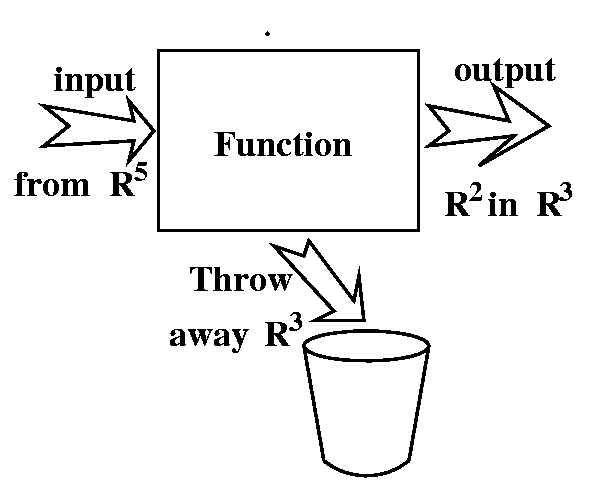 What might be happening
What might be happening
Linear systems actually keep track of the "information" using a
dimension count. The linear system we just analyzed takes vectors from
R5 to R3. It takes 5 "chunks" of information in
the 5-dimensional vector, and then it throws out 3 of them (the three
chunks corresponding to the solutions of the homogeneous system). Then
the output is a vector in R3 subject to the restriction
y3+y2-2y1=0. This is a plane in
R3, and it is a 2-dimensional subspace with basis (1/2,1,0)
(with y2=1 and y3=0) and (1/2,0,1)
(with y2=0 and y2=1).
We could almost draw a picture: input 5 chunks, throw out 3, output 2
chunks. The complication is that the coordinate systems are really
forced by the structure of the matrix A, and don't have to correspond
to what we might initially "like". In this case, the collection of
allowable outputs in R3 is rather thin, and must satisfy
the compatibility condition. I also should remember to mention Mr. Elnaggar for some meritorious (?)
suggestion he made in connection with this example.
I rapidly analyzed another example. This was a 4 by 4 system: 4
equations in 4 unknowns. This was the original system:
3x1+0x2-1x3+1x4+=y1
0x1+1x2+0x3+1x4+=y2
2x1+0x2+1x3+1x4+=y3
0x1+2x2+0x3+1x4+=y4
I was actually going to compute the row reduction but the clamor of
the class prevented it.
clamor: n.
1. loud or vehement shouting or noise.
2. a protest or complaint; an appeal or demand.
Instead I presented this result:
(3 0 -1 1 | y1) (1 0 0 0 | (1/5)y1-(4/5)y2+(1/5)y3+(2/5)y4)
(0 1 0 1 | y2)~~~~(0 1 0 0 | -y2+y4 )
(2 0 1 1 | y3) (0 0 1 0 |-(2/5)y1+(2/5)y2+(3/5)y3-(1/5)y4)
(0 2 0 1 | y4) (0 0 0 1 | 2y2-y4 )
It is only four "pivots" and not that much work!
Here is a general fact, which is difficult to state precisely but sure
is true (trust me!): matrices want> to be of maximal rank. So
if we try to write a random matrix (as I did here, subject to my
desire that the row reduction not horrible) then it is likely that
the rank will be 4. So here the rank is 4, and we verified it (or I
did, the class declining to cooperate!).
2x1+3x2=y1
5x1-1x2=y2
The answer is
x1 =(1/17)y1+(3/17)y2
x2=(5/17)y1-(2/17)y2
There was enormous complaining because the number 17 was
seen. I regret this. (It is intentionally not clear whether I
regret giving an example with 17 or whether I regret the complaints!)
with(linalg):
a:=matrix(2,2,[2,3,5,-1]);
[2 3]
a := [ ]
[5 -1]
inverse(a);
[1/17 3/17]
[ ]
[5/17 -2/17]
Isn't this EASY?
February 26
5a-6b+3c=0
This is a fairly puny system, especially compared to those you will encounter in both school and the real world. It has the essential aspects, though: some variables (a and b and c) entering only to the first power and being combined linearly with coefficients (5 and -6 and 3) and the linear combination is set equal to 0.
A more general system might involve N variables, x1, x2, ..., and xN. There might be a collection of M equations: SUMj=1Naijxj=0. Here the coefficients are the aij, which are N times M coefficients. The equations all describe linear combinations of the variables, and we are asked to see what we can say when all of the linear combinations are zero: that's what makes this a homogeneous linear system.
We can rewrite this more compactly in matrix notation: AX=0. Here A is
the M by N matrix whose ijth entry is aij and X
is the N by 1 column matrix or a column vector with entry in row i equal to
xi. Finally, 0 is the M by 1 column matrix whose entries
are all zeros.
Minor comment about names: a (something by 1) matrix is frequently
called a column matrix or a column vector, while a (1 by something)
matrix might be called, of course, a row matrix or a row vector. In
our text, the "unknowns" are almost always column matrix
notation. Warning: other sources (textbooks, program descriptions,
etc.) might make the unknowns row vectors, because everybody always
has a new and better and different way to write and understand things.
Suppose S is the collection of all vectors in RN which are solutions of AX=0. What can one say about S? What is the "structure" of S?
In all cases, S has at least the vector of all 0's in it. That's because this is a homogeneous system. This is usually called the trivial solution of a homogeneous system. The interesting question to ask is whether there are solutions which are not the trivial solution. In applications, systems might represent long-term or steady-state responses of some circuit or springs or something, so we might want to know whether the mathematical model allows the possibility of other than a "neutral" (trivial?) steady-state.
O.k., what can one say about the solution set? Let's briefly look
again at our puny example (my online dictionary defines puny as
"undersized, weak"):
5a-6b+3c=0
Suppose we have a solution, a and b and c, of this system. (No, I
don't care what the numbers are here -- my goal is the general
features or structure right now).
-
What about ta and tb and tc? Well,
look:
t·0=t(5a-6b+3c)=5(ta)-6(tb)+3(tc)
So ta and tb and tc are again solutions: a scalar multiple of a solution is a solution. - Suppose a1 and b1 and c1 are
solutions, and also a2 and b2 and
c2 are solutions. Then:
5a1-6b1+3c1=0
5a2-6b2+3c2=0
ADD EQUATIONS
(5a1-6b1+3c1)+(5a2-6b2+3c2)=0+0
5(a1+a2)-6(b1+b2)+3(c1+c2)=0
So the vector sum of solutions is a solution.
A friendly dialog on the street
As we walk down the street, we meet a stranger who asks
various questions.
Question #1 "Yo! [My effort to be contemporary.] I gotta homogeneous
system of 5 linear equations in 6 unknowns. Does this system gotta
solution?"
Our answer "Esteemed stranger, surely you must know that such a
system is solved by (0,0,0,0,0,0)."
Question #2 "Hey, hey, yeah, yea, I know. But ... what if
(1,2,3,0,0,-1)
is a solution? Hey, do ya know any others, and not that cheap, crummy
solution?"
Our answer "Forsooth, friend met by chance: I know that
(-1,-2,-3,0,0,1) is a solution. And, even, let us add, there are many,
many other solutions, such as (5,10,15,0,0,-15), oh, so many that each
star in the sky could have a separate one!"
(Dictionary says forsooth is old-fashioned and means "truly; in
truth; no doubt.")
Question #3 "O.k., o.k., no stars, just now for some down to earth
bling-bling which I'll give ya if you can tell me: suppose I know both
(1,2,3,0,0,-1)
and (5,0,2,2,1,1)
are solutions of this system. Can you
tell me if there is a solution which doesn't happen to be a scalar
multiple of any solution I've told you?"
Our answer "Noble new acquaintance, our lives are enriched by
your inquiries. Know that (6,2,5,2,1,0)
is also a solution, for it is
a vector sum of two known solutions of this homogeneous
system. And (6,2,5,2,1,0) is not a multiple of
(1,2,3,0,0,-1) or else it would have a 0 in the fourth coordinate. And
also it cannot be a multiple of
(5,0,2,2,1,1) for then it would have a 0 in the second
coordinate. And, certainly, it isn't a multiple of
(0,0,0,0,0,0). So we have produced what you requested."
Question #4 "Well, you've done well so far, here in this dark,
quiet street. I have just one more question, just one more. Here in
this book I have a list of all of the 98,000 solutions to a
homogeneous system of 35,000 equations in 2,340 unknowns. What do you
say to that?"
Our answer "No, that can't be so. Once there are more
solutions than the trivial solution, there must be infinitely
many solutions, and your book must therefore be an infinite sink
of knowledge ... and even more, by your gradually improving grammar
and the increasing
subtlety of your questions, we know that you are the evil magician,
The Linear Eliminator, whom all must
loathe and hold in contempt!"
With a gigantic flash, the stranger disappears!
[This drama can be licensed at your local high
school. Inquire about fees and rights.]
Actually, elimination (which means changing a matrix by row operations to reduced row echelon form [RREF]) will be the nicest thing. And I should specify that what the last question/answer revealed is a general dichotomy (dictionary: a division into two, esp. a sharply defined one.) worth remarking on: a homogeneous linear system either has only the trivial solution, OR it has lots and lots (infinitely many!) solutions.
I tried to give a really explicit example. I started writing a 3 by 5 matrix, and then remarked that we would eventually want to change it to RREF, so why don't we just start with the RREF. Here's our A:
( 1 0 3 2 1) ( 0 1 -5 0 2) ( 0 0 0 0 0)I checked to make sure this matrix was in RREF, and it was. Now we proceed to
Analysis of the homogeneous system determined by the coefficient
matrix, A
1. How many unknowns in each equation? 5 unknowns
2. How many equations does this represent? 3 equations
Comment Yeah, the third equation is rather silly. It is 0=0,
or, more formally,
0x1+0x2+0x3+0x4+0x5=0.
I would like to be organized here, and not ignore anything.
3. What is the rank of this matrix? The rank is 2
4. Find a solution of this system? (0,0,0,0,0).
Comment This solution, suggested by Mr. Ivanov, is so distinctive that I propose
to call it the Ivanov vector. In fact, the Name-a-vector-registry
will maintain a list of the vectors I designate forever, or maybe for
just a few minutes.
5. Find another solution (a non-trivial solution!) of the system.
(-3,5,1,0,0)
Comment This is the Seale vector following its
suggestion by Mr. Seale. I asked why
this vector satisfies all of these equations. One way is to just "plug
in" the suggested values, and, sure enough, they will satisfy the
equations. But is there some "structure" underlying his example?
6. What is the dimension of the subspace S of R5 of
solutions of this system? What is a basis of this subspace?
The core of the example with coefficient matrix A
The collection of equations is
1x1+0x2+3x3+2x4+1x5=0. 0x1+1x2-5x3+0x4+2x5=0. 0x1+0x2+0x3+0x4+0x5=0.Therefore
x1 =-3x3-2x4-1x5
x2= 5x3+0x4-2x5
So if(x1) (x2) (x3) (x4) (x5)is a vector in S, we know the following:
(x1) (-3x3-2x4-1x5) (-3) (-2) (-1) (x2) ( 5x3+0x4-2x5) ( 5) ( 0) (-2) (x3) = ( 1x3 ) = x3( 1) ( 0) ( 0) (x4) ( 1x4 ) ( 0) + x4( 1) ( 0) (x5) ( 1x5 ) ( 0) ( 0) + x5( 0)I will call the first vector which appears on the right-hand side, u, and the second vector, v, and the third, w. There are several important observations to make about these vectors.
SPAN Every vector in S can be written as a linear combination of these three vectors.
LINEAR INDEPENDENCE These three vectors are linearly independent. Look at the last three coordinates. If some linear combination is equal to 0, then because of the 0-1 structure of the vectors, we see that x3 and x4 and x5 would all have to be 0. The only way a linear combination can be 0 is for all of the coefficients to be 0. These vectors are linearly independent. Generally it might be a bit irritating to decide ("by hand") if three vectors in R5 were linearly in dependent.
VECTORS IN THE SUBSPACE HAVE COORDINATES Each vector in S has a unique description written as a sum of the three vectors. In effect, the numbers x3 and x4 and x5 serve as a unique address for any vector in S once we know u and v and w. These vectors form a basis for S and the dimension of S is 3.
Another example
Consider this coefficient matrix for a homogeneous system of linear
equations:
(1 0 0 0 0 3 5 7 -1) (0 1 0 0 0 2 1 0 0) (0 0 0 1 0 2 5 -1 1) (0 0 0 0 1 5 0 2 1)There's an additional little "wrinkle" here: the third column of 0's. Here S will again mean the collection of all solutions of the system of equations. We want to understand S well, so if needed we can compute with it.
1. How many unknowns in each equation? 9 unknowns
2. How many equations does this represent? 4 equations
3. What's the rank of this system? The rank is 4.
4. What additional complication does that "all 0's" column represent? The vector (0,0,1,0,0,0,0,0,0) is in S.
Comment This vector was suggested by Ms. Kohut and will therefore be called the Kohut vector. Any multiple of the vector solves AX=0. It represents one dimension in S. What is or what should be the dimension of S? At first, since S is inside R9, we see that the dimension is some integer from 0 to 9. The Kohut vector (!) certainly shows that 0 isn't correct. And we can see that 9 isn't correct if we can find at least one vector which isn't in S, such as (1,0,0,0,0,0,0,0,0). But ...
5. What's a basis of S? Think about it ...
Comment This is supposed to be the payoff of the whole lecture. You are supposed to see that every vector in S can be written as
x3(0,0,1,0,0,0,0,0,0)+ x6(-3,-2,0,-2,5,1,0,0,0)+ x7(-2,-1,0,0,0,0,1,0,0)+ x8(-7,0,0,1,-2,0,0,1,0)+ x9(1,0,0,-1,-1,0,0,0,1)
This needs some thinking about and I strongly urge you to think about it. The collection of these 5 vectors in R9 does give a basis of S.
6. What's the dimension of S? Its dimension is 5.
You maybe should notice that the matrix is 4 by 9, its rank is 4, and the dimension of S is 5. In our previous example, the matrix was 3 by 5, its rank was 2, and the dimension of S was 3.
Advertisement: 4+5=9 and 3+2=5.
The QotD was to analyze similarly the collection S of solutions of the linear homogeneous system given by the matrix
(-15 0 -42 -6 -21 -83) ( 30 0 84 0 24 -6) (-15 0 -63 2 -8 27)There was some distress voiced almost immediately about this. In order to make people happier, I declared that I would respond to one computational request from the students. I heard from Mr. Seale, "What is that in RREF?" So I responded
(1 0 0 0 2/5 5/3) (0 0 1 0 1/7 -2/3) (0 0 0 1 5 -2 )(Secret: I started with this and did row operations to get the one I first wrote on the board!)
Please continue reading chapter 6. Please hand in 6.5: 1, 5, 13 on Tuesday.
The first exam results
I returned the graded exams and answers. Here is a version of the exam, and here
are some answers. A discussion and
some statistical analysis of the grading is here..
As I remarked, the grades were incredibly bimodal, with a standard deviation of 22.78, very large in my experience (wide dispersion from the mean in this scale). In general, math courses are intensely cumulative and students who do poorly on the first exam tend to do poorly in the whole course. This course has three components. There certainly are connections (for example, problem 6 on the first exam, and other connections of linear algebra with Fourier series which will become apparent) but the connections are not overwhelming. Therefore I believe students are more likely than in most math courses to be able to have much improved achievment on other exams in this course. Since I don't believe that students who have gone through technical majors and persisted into the junior and senior years are likely to be weak, I respectfully suggest that allocation of time and effort are likely to be related to very poor performance. So I recommend practice.
February 24
I can't stay so late next time. (A few of us stayed until almost 10!). I keep five giant mutant rottweilers (200 pounds each) and they got so hungry that they ate the refrigerator.
On Wednesday, I went to a nice presentation about Schlumberger. They are looking for mechanical engineering undergrads who want to be field engineers. This is a real employment opportunity for such people.
|
|
February 19
How can we solve systems of linear equations? This is a difficult
question which is central to many applications. I'll break it up into
three parts.
Numerical solution of linear equations
Google
lists 407,000 (four hundred and seven thousand!) responses to
the query "numerical linear algebra". There are steps in the solution
of linear equations (division!) where numerical things (such as
accuracy) can get really tricky. There are even examples of 2 by 2 and
3 by 3 matrices where computing the inverse is unstable numerically. I
certainly won't worry about this here (my examples will mainly be to
illustrate the logic and almost always involve "small" rational
numbers' But you will almost certainly have to worry about numerical
stuff. The simplest approach is to get a good collection of programs
(for example, Matlab) and hope that your problems stay inside
what the programs can handle.
Symbolic computation in linear algebra
Some students may have been witnesses in calc 3 to the computation of
the Jacobean (volume distortion factor) for spherical
coordinates. This is a symbolic 3 by 3 determinant.
I'll discuss the difficulties of symbolic computation a bit more when
we get to determinants and Cramer's rule, but such computations are
almost notoriously difficult. There may be no good way to do them.
And for right now, here?
We will deal with small systems. We will use a variant of Gaussian
elimination and won't worry too much about efficiency. The main point
of using this will be to illustrate the concepts of linear algebra,
and to try to give students some intuition about what to expect.
I began by writing three vectors in R4 and asking if they were linearly independent. Let's see: I took them at random, with small integer entries. Maybe v1=(1,2,-2,0) and v2=(2,3,0,3) and v3=(3,0,2,4). These vectors are linearly independent if the only solution to the vector equation av1+bv2+cv3=0 is a=0 and b=0 and c=0. Because that solution always works, it is sometimes called the trivial solution. We want to know if there is a non-trivial solution, where the equation is correct with a and b and c not all 0. Then the vectors will be linearly dependent. The vector equation translates into a system of 4 scalar equations:
1a+2b+3c=0 2a+3b+0c=0 -2a+0b+2c=0 0a+3b+4c=0It is tremendously appealing to just jump (?) into this collection of equations and "do things". Instead, I would like to promote the use of a methodical approach. This takes some of the "flavor" away, but it does work. I'd like to change those 4 equations into others, and be sure that the solution set of the equations does not change. Sometimes people call this changing the system of linear equations into an equivalent system. It turns out that there are some things we can do that are all reversible, and then (almost) clearly the solution set won't change. These are:
- Multiply an equation by a non-zero constant. (Reversible because we can multiply by 1/constant, of course.)
- Add/subtract one equation from another. (Reversible because we can subtract/add.)
- Interchange two equations.
( 1 2 3) ( 2 3 0) (-2 0 2) ( 0 3 4)The equation operations above have a different name in the matrix context.
DEFINITION
The elementary row operations
- Multiply a row by a non-zero constant.
- Add/subtract one row from another.
- Exchange rows.
( 2 3) (-1 0) ( 5 2)Then a variety of elementary row operations will yield these matrices:
(-1 0) ( 4 6) ( 1 3) ( 2 3) A=( 2 3) B=(-1 0) C=(-1 0) D=(-1 0) ( 5 2) ( 5 2) ( 5 2) (35 14)See if you can "guess" the row operations which created A, B, C, and D. Here are the answers. If M and N are matrices which can be linked by a series of row operations, then I will say that M and N are row-equivalent, and I will frequently write M~N (that's a "tilde", a horizontal wiggle, which is used in many places to denote row equivalence). If a matrix is non-zero, then infinitely many other matrices can be created which are row equivalent. But some of the row-equivalent matrices are easier to understand than others.
DEFINITION Reduced row echelon form
(p.264 of the text).
A matrix is in reduced row echelon form if:
- The leading entry of any nonzero row is 1.
- If any row has its leading entry in column j, then all other entries of column j are zero.
- If row i is a nonzero row and row k is a zero row, then i<k.
- If the leading entry of row r1 is in column c1, and the leading entry of row r2 is in column c2, and if r1<r2, then c1<c2.
I remarked that this interesting definition certainly illustrates the
following remark of Goethe:
| Mathematicians are like a certain type of Frenchman: when you talk to them they translate it into their own language, and then it soon turns into something completely different. |
One of the tricks I use when I see a complicated mathematical
definition is try to break it. That is, I test (?) each of the
conditions in order and see what it means by finding a sort of
counterexample. And I try to find the very simplest and smallest
counterexample. So:
- The leading entry of any nonzero row is 1.
First, I guess that "leading entry" means the first (moving from left to right) non-zero entry of a row. So if (0 0 2 1 3) is a row, the leading entry would be 2. What is the smallest example of a matrix which has a non-zero row whose leading entry is not 1? The 1 by 1 matrix (2) was suggested.
- If any row has its leading entry in column j, then all other
entries of column j are zero.
Can I find a very small example of a matrix which does satisfy 1 but does not satisfy 2? The suggestion here was something like(1) (1)
- If row i is a nonzero row and row k is a zero row,
then i<k.
How about an example satisfying 1 and 2 but not this? Here we needed to ponder a bit longer. Zero rows are supposed to be at the bottom. Here's a small example:(0) (1)
- If the leading entry of row r1 is in column
c1, and the leading entry of row r2 is in
column c2, and if r1<r2, then
c1<c2.
Certainly this is the most mysterious specification, and seems most menacing with the letters and subscripts. This example will need more than one column, because c1 and c2 shouldn't be equal. Here is an example which satisfies 1 and 2 and 3, but not rule 4:(0 1) (1 0)
What the heck does rule 4 say? The leading 1's have to move down and to the right.
(0 0 1 0 0 2 -3 0) (0 0 0 0 1 0 0 0) (0 0 0 0 0 0 0 0)For those of you who know about identity matrices) these are square matrices which have 1's on the diagonal and 0's off the diagonal. I will call the n by n identity matrix In. These matrices are nice because they are identities for matrix multiplication. If the dimensions are in agreement so that the multiplication is defined, then AIn=A and InB=B. So In's are nice. The row echelon form is sort of
(In JUNK) (ZEROS ZEROS)But of course the example above shows that we don't exactly need an identity matrix -- the 1's can be further indented or pushed in.
BIG IMPORTANT FACT Every matrix is row equivalent to exactly one reduced row echelon form matrix.
And we can find this unique reduced row echelon form matrix with a simple algorithm. An algorithm is a computational rule which is definite (you don't need to guess anywhere!) and is finite: it will always terminate.
Here is an example. Let's look at the matrix
( 1 2 3) ( 2 3 0) (-2 0 2) ( 0 3 4)which we started with earlier. We look for the first non-zero column and the highest non-zero entry in that column. Multiply that row so the row begins with 1. Here we don't need to do anything, since the row already begins with 1. Then take multiples of the first row and subtract them in turn from the other rows so that the entries below become 0.
( 1 2 3) ( 2 3 0) (-2 0 2) ( 0 3 4) | ~ | ( 1 2 3) ( 0 -1 -6) (-2 0 2) ( 0 3 4) | ~ | ( 1 2 3) ( 0 -1 -6) ( 0 4 8) ( 0 3 4) |
| Nothing necessary; row already begins with 1. | Multiply first row by 2 and subtract from second row. | Multiply first row by 2 and add to third row. |
( 1 2 3) ( 0 -1 -6) ( 0 4 8) ( 0 3 4) | ~ | ( 1 2 3) ( 0 1 6) ( 0 4 8) ( 0 3 4) | ~ | ( 1 0 -9) ( 0 1 6) ( 0 4 8) ( 0 3 4) | ~ | ( 1 0 -9) ( 0 1 6) ( 0 0 -16) ( 0 3 4) | ~ | ( 1 0 -9) ( 0 1 6) ( 0 0 -16) ( 0 0 -14) |
| Identify non-zero entry. | Divide second row by -1. | Multiply second row by 2 and subtract from first row. | Multiply second row by 4 and subtract from third row. | Multiply second row by 3 and subtract from fourth row. |
( 1 0 -9) ( 0 1 6) ( 0 0 -16) ( 0 0 -14) | ~ | ( 1 0 -9) ( 0 1 6) ( 0 0 1) ( 0 0 -14) | ~ | ( 1 0 0) ( 0 1 6) ( 0 0 1) ( 0 0 -14) | ~ | ( 1 0 0) ( 0 1 0) ( 0 0 1) ( 0 0 -14) | ~ | ( 1 0 0) ( 0 1 0) ( 0 0 1) ( 0 0 0) |
| Identify non-zero entry. | Divide third row by 16. | Multiply third row by 9 and add to first row. | Multiply third row by 6 and subtract from second row. | Multiply third row by 14 and add to fourth row. |
a=0 b=0 c=0 0=0and now it is very clear that the only solutions are 0 and 0 and 0, so the original collection of three vectors is linearly independent.
An interesting exercise is writing a correct implementation of this algorithm as a computer program. I am not the world's leading programmer but I think I could do this. But it is not an easy exercise. In fact, just describing the algorithm to get a reduced row echelon form matrix is not easy. I don't think I will attempt to do it. Move from left to right, and clean up the columns in order. I made one more
DEFINITION Rank The rank of a matrix is the number of 1's in the leading block of the reduced row echelon form (therefore it is the number of non-zero rows).
The matrix above has rank 3. A matrix has rank 0 if it is the zero matrix, a matrix whose entries are all 0. Generally, a p by q matrix could have rank any non-negative integer between 0 and the minimum of p and q. So a 7 by 4 matrix could have rank 0 or 1 or 2 or 3 or 4. Here are examples of each:
(0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) | (0 1 2 3) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) | (1 0 0 5) (0 0 1 7) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) | (1 0 0 0) (0 0 1 0) (0 0 0 1) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) | (1 0 0 5) (0 1 0 4) (0 0 1 7) (0 0 0 0) (0 0 0 0) (0 0 0 0) (0 0 0 0) |
||||
| Example of rank 0 | Example of rank 1 | Example of rank 2 | Example of rank 3 | Example of rank 4 |
|---|
A homogeneous system with fewer equations than unknowns
What can we say about this homogeneous system
of equations:
2a+3b+1c+3d+4e+1f=0 3a+4b+2c+1d+2e+2f=0 4a+1b+1c+5d+6e+4f=0So let's take the coefficient matrix and use row operations to change it to reduced row echelon form.
(2 3 1 3 4 1) (3 4 2 1 2 2) (4 1 1 5 6 4) | ~ | (1 3/2 1/2 3/2 2 1/2) (3 4 2 1 2 2 ) (4 1 1 5 6 4 ) | ~ | (1 3/2 1/2 3/2 2 1/2) (0 -1/2 1/2 -7/2 -4 1/2) (0 -5 -1 -1 -2 2 ) | ~ |
(1 3/2 1/2 3/2 2 1/2) (0 1 -1 14 8 -1) (0 -5 -1 -1 -2 2 ) | ~ | (1 0 2 -39/2 10 2) (0 1 -1 14 8 -1) (0 0 -6 69 38 -3) | ~ | (1 0 2 -39/2 10 2 ) (0 1 -1 14 8 -1 ) (0 0 1 -23/2 -19/3 1/2) | ~ |
(1 0 0 7/2 -8/3 1 ) (0 1 0 5/2 5/3 -1/2) (0 0 1 -23/2 -19/3 1/2) | |||||
The rank of this matrix is 3. To me, especially because this is a random example (honestly!), this is no surprise. Random matrices naturally "want" to have maximum rank. This can be made precise, but I would need an explanation of the word "random" and I don't want to enter that swamp.
The original system of equations was
2a+3b+1c+3d+4e+1f=0 3a+4b+2c+1d+2e+2f=0 4a+1b+1c+5d+6e+4f=0which we now know has the same solutions as
a + [ (7/2)d -(8/3)e +1f]=0
b + [ (5/2)d +(5/3)e-(1/2)f]=0
c + [(-23/2)d-(19/3)e (1/2)f]=0
3 by 3
identity JUNK
matrix
This actually has some significance. Does this system of homogeneous
equations have any non-trivial solutions? Yes, it does. We can specify
any numbers for d and e and f (a three-parameter family of solutions)
and then select a and b and d so that the equations are correct. So we
have learned that this system of equations has actually a
three-dimensional subspace of solutions. More about this next time,
but, generally, you can see that if we have any homogeneous system of
3 equations in 6 unknowns, there will always be non-trivial solutions.
The QotD was first incorrectly stated, and then
rewritten. Here's the first version: suppose I have a homogeneous
system of 340 linear equations in 315 unknowns. What are the possible
ranks of the coefficient matrix? Explain why there must be non-trivial
solutions to this system.
O.k., the first part isn't hard. The coefficient matrix is 340 by 315,
so the rank could be any integer from 0 to 315. The second statement
asks students to justify a false
statement, which is quite idiotic of the instructor. Why is it false?
Here is an example of a system of equations. If j is an integer
between 1 and 315 (including the end values) suppose that the
jth equation is xj=0. I don't care what the
other 25 equations are, these 315 equations already guarantee that
there will be only the trivial solution.
Corrected QotD: suppose I have a homogeneous
system of 315 linear equations in 340 unknowns. What are the possible
ranks of the coefficient matrix? Explain why there must be non-trivial
solutions to this system.
The rank again could be any integer from 0 to 315. But now consider
the coefficient matrix in reduced row echelon form. It is a rectangle
which has more columns than rows (25 more). That means no matter what
the rank (0, 1, 2, ...., up to 315) there must be JUNK columns in the
matrix, in fact, at least 25 junk columns. That in turn implies that
we can specify any values to those 25 variables, and can then choose
if necessary values for the "first" 315 variables making the equations
true. There must be non-trivial solutions, and in fact there is a
subspace of at least dimension 25 in R340 which is composed
of solutions to this homogeneous system of equations.
I must and will go over this more in the next class.
|
The row operations which were used in the early example:
|
( 2 3) (-1 0) ( 4 6) ( 1 3) ( 2 3)
Start=(-1 0) A=( 2 3) B=(-1 0) C=(-1 0) D=(-1 0)
( 5 2 ( 5 2) ( 5 2) ( 5 2) (35 14)
|
February 17
I defined a subspace of Rn last time. Why should we be interested in this? Many math processes create subspaces. For example, when we analyze y''+y=0 we see the solutions are A sin(t)+B cos(t): that's the linear span of sine and cosine, the collection of all linear combinations of sine and cosine. It is a subspace of functions.
Here is another way subspaces of functions can arise. If we consider the more complicated expression y''-3y'+2y (another second order linear ODE) we could ask what are the possible outputs if we feed in linear combinations of functions like sin(t), cos(t), t sin(t), t cos(t), et: what outputs should we expect? Here the question is more subtle, since I threw in et which is actually a solution of the associated homogeneous equation. The result will be a subspace, but will be a bit more difficult to describe. The general problem to be discussed: How can we describe subspaces efficiently? I'll go back to Rn for this.
DEFINITION
Linear combinations
Suppose v, v2, ... vk are
vectors in Rn. Then a linear combination is a sum
a1v1+a2v2+...+akvk
where a1, a2, ..., and ak are
scalars.
I'd like to describe subspaces as linear combinations of vectors.
DEFINITION
Span; spanning set
If the collection of all linear combinations of v1,
v2, ..., vk is a subspace S, then S is said to
be the span of v1, v2, ....,
vk. Or, the other way around: v1,
v2, ..., vk is a spanning set for S.
I tried a modest example as a beginning: S was the collection of vectors in R4 which can be described as (x,y,0,0) with x and y any real numbers. If e1=(1,0,0,0) and e2=(0,1,0,0), then {e1,e2} is a spanning set for this S (xe1+ye2 is the linear combination). We tried various examples of spanning sets. One was {e1,e1+e2}. I ran through the logic which went something like this:
I went through this logic in detail, although rapidly, because it is at the heart of numerous arguments in linear algebra. Another way to understand the logic is to mumble, "Linear combinations of linear combinations are linear combinations" very rapidly.
Goldilocks
and the three bears (a wonderful link!)
Let's see: Just {e1} alone is not enough to be a spanning
set for this S because we couldn't get, say, (0,17,0,0). The set
{e1} is too small to be a spanning
set.
THIS PORRIDGE IS TOO HOT!
The set {e1,e2,e1+e2}
definitely is a spanning set for S, but, as Mr. Cohen remarked, the last vector in the
list is redundant vector: it isn't necessary. Including it
doesn't change the
span. So this set is too large to describe S
efficiently.
THIS PORRIDGE IS TOO COLD!
What's going on? There are many descriptions of S, but what
descriptions are efficient, minimal, etc.? How can we tell? This is a
core question of linear algebra. If we can write one vector as a sum
of others, then ("linear combinations of linear combinations are
linear combinations") we don't need that vector. The trouble is that
we may not know which vectors are unneeded. An unbiased way of finding
out that there are unneeded or redundant vectors uses the following
definition.
DEFINITION
Linear independence and linear dependence
Vectors v1, v2, ..., vk are said
to be linearly independent if, whenever there is a linear combination
a1v1+a2v2+...+akvk
which =0, then all of the coefficients a1,
a2, ..., ak must be equal to
0. (Intuitively, the vectors point in different directions, so if
some sum is 0 we must have no non-zero multiple of any of the vectors
in the sum.)
On the other hand (?), Vectors v1, v2, ..., vk are said
to be linearly dependent if there is some linear combination
a1v1+a2v2+...+akvk
which =0 and not all of the scalar coefficients are 0. (This
means that one of the vectors can be written as a linear combination
of the others, so [at least!] one of the vectors is redundant in
describing the span of v1, v2, ...,
vk.)
Example in R4
This was a lot, so I thought it was time to do an example. Look at the
vectors v1=(1,2,0,3) and
v2=(0,3,1,2) and
v3(1,2,3,1). I tried to choose an example with small
integer entries, but one where I couldn't "look at" the vectors and
guess the answers to questions I would ask. Here I first wanted to
know if these vectors were linearly independent. So I need to know
about the solutions to the vector equation
av1+bv2+cv3=0.
If the only solutions to this vector equation occur when a=0 and b=0
and c=0 then the vectors are linearly independent. This is a vector
equation in R4 (the 4 is most important
here!) so the one vector equation translates to a system of 4 scalar
equations:
1st component equation 1a+0b+1c=0
2nd component equation 2a+3b+2c=0
3rd component equation 0a+1b+3c=0
4th component equation 3a+2b+1c=0
For the few of you who don't know, there are well-known algorithms for
analyzing such systems. Right now (this lecture!) I'll just try to
look at the equations "by hand" -- this is a bit inefficient and
sometimes irritating, but, just for today. Please try to keep your
attention focused on the logic as much as possible. The first equation
tells me that a=-c and the third equation tells me that b=-3c. Using
these in, say, the fourth equation gives me 3(-c)+2(-3c)+1c=0 which
is -8c=0 so c must be equation to 0! The other equations which
relate c to a and b now tell me that a and b must be 0 also. So these
vectors in R4 must be linearly independent. Therefore if I
want to define a subspace S and the span of these three vectors, all
of the vectors are needed: none of them are redundant. In fact, each
vector in S has a unique description as a sum of v1 and
v2 and v3. Why is this?
Let me show you with an example. Suppose w is in S, and
w=4v1-9v1+33v1 and
also
w=83v1+22v1+48v1: two
different descriptions as linear combinations of the vectors. Then the
two linear combinations must be equal since they are both w.
Do some vector algebra and get
(83-4)v1+(22+9)v1+(48-33)v1=0.
Hey! This contradicts the linear independence of
v1 and v2 and v3 which we just
verified! So eachw in S can have only one description as a
linear combination of those three vectors.
DEFINITION
Basis and dimension
Suppose S is a subspace. Then v1,
v2, ..., vk is a basis of S if
any of the following three equivalent conditions is satisfied:
- The vectors v1, v2, ..., vk span S and they form a minimal spanning set for S: if we delete any of them, the linear combinations no longer "fill up" S.
- The vectors v1, v2, ..., vk are linearly independent and they are a maximal linearly independent set in S: if you include any other vector in S, there's a way of writing that vector as a linear combination of these.
- Every vector in S can be described as a unique linear combination of v1, v2, ..., vk. So if w is in S, there is exactly one way to write w as a1v1+a2v2+...+akvk. The scalars a1, a2, ...., ak are usually called the coordinates of w with respect to this basis.
 Now back to the example
Now back to the example
So I have this subspace S of R4 which has
v1=(1,2,0,3) and
v2=(0,3,1,2) and
v3+(1,2,3,1) as a basis. Even with our low-brow "hand"
technology, we can still answer questions like this: is
w=(2,2,2,2) in S?
I picked this vector at random, and felt very comfortable betting with
myself that the answer was "No." Why is that? Let me try to share my
mental picture of the situation. In fact, let me try, as I did in
class, to draw a picture of the situation. This picture has got to be
deceptive. It is a two-dimensional picture of a three-dimensional
analogy of a four-dimensional situation. (Now that's a
sentence!) So my impression is that S is a flat "thing" going through
the origin, 0. It is flat because multiples of any vector in S
is in S: so S is made up of straight lines which pass through the
origin (+ and - multiples of vectors are allowed). Because we can also
add vectors in S and get another vector in S, we know that the straight
lines are "joined" by flatness. A random point in R4 is
probably not in S because S is down a whole dimension from the
"ambient" (surrounding) space. Well, let's see what happens. Can this
w be in S? If
w=av1+bv2+cv3,
then this is one vector equation which results (look again at the
coordinates) in four scalar equations which again I will analyze in a
naive manner. Here are the four scalar equations:
1st component equation 1a+0b+1c=2
2nd component equation 2a+3b+2c=2
3rd component equation 0a+1b+3c=2
4th component equation 3a+2b+1c=2
Then (first equation) a=2-c and (third equation) b=2-3c, so inserting
things in, say, the fourth equation, we get 3(2-c)+2(2-3c)+1c=2. This
becomes after a bit of cleaning -8c=-8 so, if the equations can
be satisfied, then c should be 1. We used only the first, third, and
fourth equations. What about the second? If c=1, then a=2-1=1 and
b=2-3(1)=-1. The equation 2a+3b+2c=2 becomes 2(1)+3(-1)+2(1)=2 or
1=2. So the equations have no common solution. Therefore w is
not in S.
Another example
Of course I didn't want to repeat totally an example with similar
qualitative aspects as the previous one. With that in mind, let us
analyze the situation in R4 when
v1=(-2,4,2,-4)
and v2=(1,-5,-1,4) and
v3(-2,1,2,-2). (I screwed up one of these vectors in
class, and copied a vector with a sign change onto the board!) If S is
the span of these vectors,
what is and what could be the dimension of S? S sits inside
R4. The dimension could be 4 or 3 or 2 or 1 or even
0. (What about 0? Well if S consisted just of the zero vector, this
does satisfy the rules for a subspace, and the usual understanding is
that the dimension of this rather small subspace is 0.) How about
here? Since S is spanned by 3 vectors, I don't think S will be all of
R4, which needs 4 vectors to span, so we can throw 4
out. Also, S won't have dimension 1, because "clearly" the three
vectors spanning S will not consist of multiples of one vector. Since,
for example, v1 is not a scalar multiple of
v2, S needs at least two vectors to span
it. Therefore S has either dimension 2 or 3. We need to decide if
these 3 vectors are linearly independent. So we look at the vector
equation
av1+bv2+cv3=0.
which translates into the system of 4 scalar equations:
1st component equation -2a+1b-2c=0
2nd component equation 4a-5b+1c=0
3rd component equation 2a-1b+2c=0
4th component equation -4a+4b-2c=0
Again, only elementary techniques will be used. The majority of the
class, who know about, say row reduction to row-echelon form, was
getting fairly restless. This did not work in class because of the
misquoted minus sign. It will work here! The first and third
equations are the same (logically the same: one is the other
multiplied by -1), so we can forget one of them. Double the first
equation and add it to the second. The result is -3b-3c=0, so that
c=-b. Add the second and fourth equations. The result is -b-c=0 so
that (again!) c=-b. What is going on? Apparently if we choose b and c
to satisfy c=-b, and then deduce a value of a, we will get solutions
to all of the equations. Let me choose b=1. Then c=-1, and, say,
the first equation becomes -2a+1(1)-2(-1)=0 so that a should be
a=3/2. In fact the values a=3/2 and b=1 and c=-1 satisfy all of the
equations. (You can check that the vector equation
3v1+2v2-2v3=0 is
correct, which is the same thing.)
Therefore v1, v2, and
v3 are not linearly independent. In this case, we can
get a basis for S by omitting any one of them, and the dimension of
the subspace S is 2.
A system of abbreviation: matrices
We will be writing lots and lots and lots of linear equations. It may
be handy to have abbreviations for them. For example, the two linear
equations in four unknowns
3x-2y+6z+5t=9
5x-4y-7z+t=11
is conventionally abbreviated using certain rectangular arrays called
matrices. The three matrices which would be used for this system
are
( 3 -2 6 5) (x) ( 9)
A= ( ) B= (y) C= ( )
( 5 -4 -7 1) (z) (11)
(t)
and the matrix equation which abbreviates the linear system
above is AB=C. Now we should talk a little bit about matrix algebra.
Coverage of this is going at jet speed and I strongly suggest
that students who are
weak on this material should review it in the text.
Matrix algebra
A rectangular array with p rows and q columns is called a p by q
matrix. (Yeah, there are higher dimensional matrices, and some of you
may come into contact with them as representation of things like
stress tensors, etc.) If A is a p by q matrix, then the entry in the
ith row and jth column will frequently be called
Ai,j.
DEFINITION Matrix addition If A
and B are matrices which
have the same size (both p by q) then the p by q matrix C=A+B has
(i,j)th entry
Ci,j=Ai,j+Bi,j.
DEFINITION Scalar multiplication of
a matrix If A is a p
by q matrix, and t is a scalar, then the p by q matrix C=tA has
(i,j)th entry
Ci,j=tAi,j.
DEFINITION Matrix
multiplication
The product AB of the
matrices A and B is only defined under certain conditions. A must be
p by q and B must be q by r. So for AB to be defined, the "inner
dimensions" of A and B must be the same: the number of columns
of A must equal the number of rows of B. If C=AB then C will be a p by
r matrix, and the entries of C are gotten in a weird manner:
Ci,k is the inner product: (ith row of
A)·(kth column of B). This is very
very weird if you
have never seen it before. This computation organizes
"linear combinations of linear combinations". Do
examples, please!
An inadequate collection of examples of matrix algebra
Here are some small matrices we can practice on.
A= B= C= D=
( 2 3 2) (3 5 -1) (-2) (2 0 0)
(-1 5 3) (4 4 2) ( 2) (0 2 0)
(-3) (0 0 2)
Here A and B are the same size (both 2 by 3) so we can compute A+B. No
other pair of matrices given here has the same size. We could compute
3C and 5A and -30D (scalar multiplication) since there aren't size
restrictions for those. What about products? A and B are 2 by 3, C is
3 by 1, and D is 3 by 3. What products are defined? I think just these
and no others: AC, AD, BC, BD, DA, and DB. Look at just AC. It is the
matrix product of a 2 by 3 matrix and a 3 by 1 matrix so AC must be a
2 by 1 matrix. The top entry is the dot product of the first row of A
with the single column of C: (2,3,2)·(-2,2,3), which is
-4+6+6=8. The other entry is the value of
(-1,5,3)·(-2,2,3), which is 2+10+9=21. So AC would be a
2 by 1 matrix whose entries are( 8) (21).It would be useful if students computed A+B, 3C, 5A, -30D, AD, BC, BD, DA, and DB. Some of the products are sort of interesting.
The QotD was: suppose A is the 2 by 2 matrix
(2 1) (3 4)Compute A4. After a clever suggestion from the class (who did suggest that?) I agreed that one could do one third less work by first computing A2 and then squaring the result, rather than computing A2 and then A3 and then A4. Of course I am sitting here in luxury with a Maple window, so I type:
with(linalg):
A:=matrix(2,2,[2, 1, 3,4]);
[2 1]
A := [ ]
[3 4]
evalm(A^4);
[157 156]
[ ]
[468 469]
and that's the answer.
Please keep reading the book: now chapter 6.
|
|
February 12
Here are my goals for this part of the course.
First, enough understanding of the "structure" of the collection of solutions to a set of linear equations so that someone who uses powerful tool such as Matlab will see what the answers should "look like". Matlab, by the way, was originally designed to do linear algebra computations for engineers and scientists.
Questions
- If (0,0,0,0) and (1,2,4,0) are solutions of 7 linear equations in 4 unknowns, must there be other solutions?
- Can there be exactly 5 solutions to a collection of 340 linear equations in 335 unknowns?
- Must a system of 30 homogeneous linear equations in 40 unknowns have some non-zero solution?
Computational aspects
- Solution by "elimination" of a system of linear equations (conversion to row echelon form)
- Decision that a square matrix is invertible (algebraically) and the computation of an inverse; connection with Cramer's rule for solution of some systems.
- Know that, due to its "structure", there are ways to compute
rapidly the 10th power of this matrix:
0 3 2 1 3 7 4 2 2 4 0 1 1 2 1 1
Vocabulary
When discussing linear algebra, special vocabulary is used. Students
should have some idea what these terms mean, and be able to check if
suggested examples are valid.
homogeneous, inhomogeneous, basis, linear independence,
linear combination, spanning, subspace, dimension, rank, eigenvalue,
eigenvector, matrix addition and matrix multiplication, symmetric,
diagonalization.
The coefficients of the systems of linear equations
 I remarked that our arithmetic will be limited to addition,
subtraction, multiplication, and division. The examples I'll do in
class will be rather small, because I am human. Usually the
coefficients and the answers will involve rational numbers. But other
collections are possible for the coefficients. Standard examples
include the real numbers and the complex numbers. But other, less
standard, examples can occur to engineers. The QotD given a week ago
is converted by Laplace transform into a system of linear equations
for X(s) and Y(s) whose coefficients are rational functions of s (that
is, quotients of polynomials). Rational functions can be added,
subtracted, multiplied, and divided. Suppose we wanted to analyze a
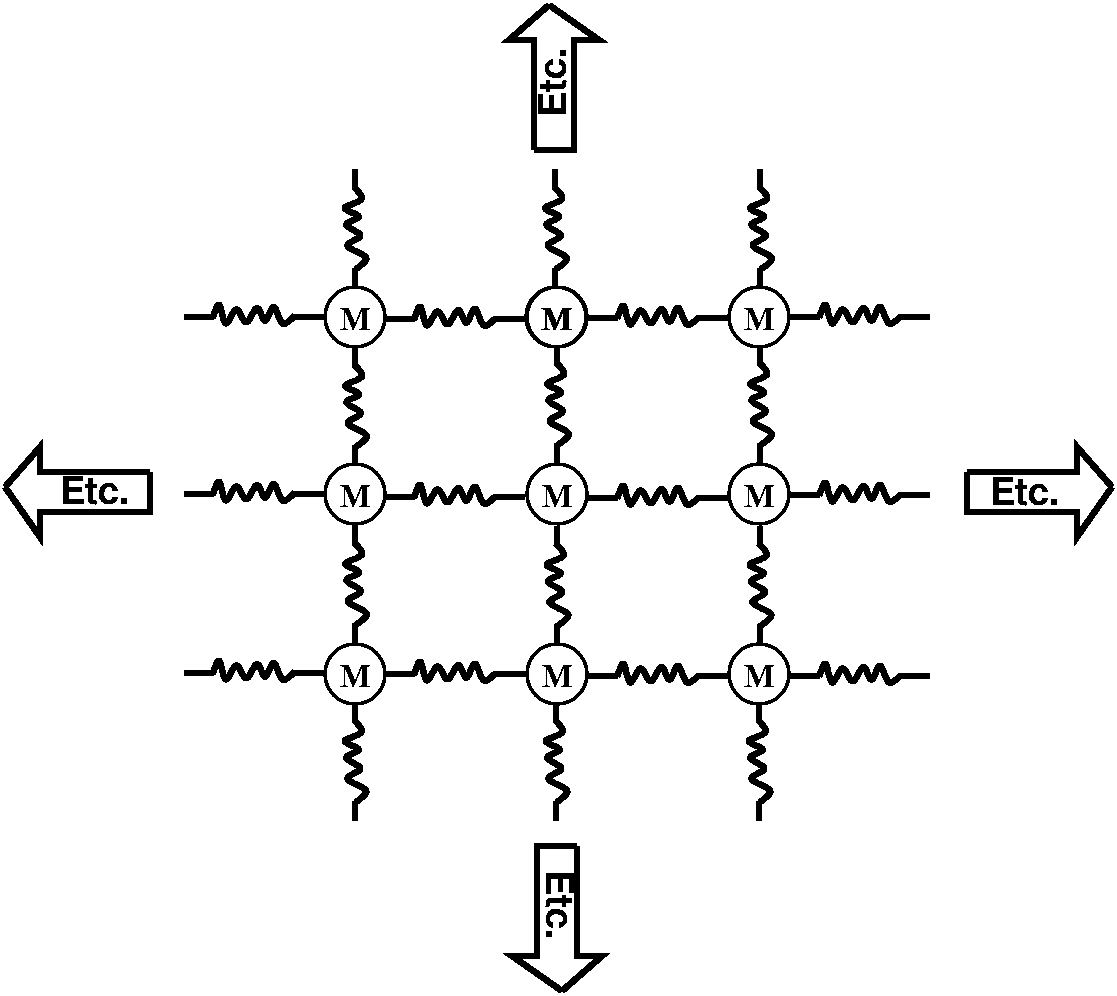
really big system of "masses" and "springs" (I've shown part of one to
the right) and wanted to learned how the system reacted if we "kicked"
it in one place. The Laplace transform would give us a big system of
linear equations with rational function coefficients. The same ideas
and algorithms that we will discuss here can be used. (Application:
material science, study of crystals, etc.) Another example, more
relevant to electrical and computer engineering, occurs when the
coefficients of the linear equations are integers mod a prime
(simplest example: the prime is 2, and the coefficients are just 0 and
1). This sort of arithmetic arises, for example, in cryptographic
applications (secure transmission and storage of information). Again,
many of the same ideas and computations can be done with such
coefficients.
I remarked that our arithmetic will be limited to addition,
subtraction, multiplication, and division. The examples I'll do in
class will be rather small, because I am human. Usually the
coefficients and the answers will involve rational numbers. But other
collections are possible for the coefficients. Standard examples
include the real numbers and the complex numbers. But other, less
standard, examples can occur to engineers. The QotD given a week ago
is converted by Laplace transform into a system of linear equations
for X(s) and Y(s) whose coefficients are rational functions of s (that
is, quotients of polynomials). Rational functions can be added,
subtracted, multiplied, and divided. Suppose we wanted to analyze a
really big system of "masses" and "springs" (I've shown part of one to
the right) and wanted to learned how the system reacted if we "kicked"
it in one place. The Laplace transform would give us a big system of
linear equations with rational function coefficients. The same ideas
and algorithms that we will discuss here can be used. (Application:
material science, study of crystals, etc.) Another example, more
relevant to electrical and computer engineering, occurs when the
coefficients of the linear equations are integers mod a prime
(simplest example: the prime is 2, and the coefficients are just 0 and
1). This sort of arithmetic arises, for example, in cryptographic
applications (secure transmission and storage of information). Again,
many of the same ideas and computations can be done with such
coefficients.
The chief example for 421
This will be Rn which is the collection of n-tuples of real
numbers. Each n-tuple will be called a vector. So we have
v=(a1,a1,...,an). I'll try (I
won't guarantee!) to write vectors in italics (just as I will
try to write them on the blackboard with happy little half-arrows on
the top. Where did that notation came from?) If
w=(b1,b2,...,bn) then the
vector sum v+w is the n-tuple
(a1+b1,a2+b2,...,an+bn).
I will now use the correct words, and I hope you will agree that they
are precise: vector addition is commutative (order to be added doesn't
matter) and associative (grouping of adding doesn't matter) and
there's an additive identity (0=(0,0,...,0)) and additive
inverses. Etc. We also have scalar multiplication:
tv=(ta1,ta2,...,tan) which has
various distributive rules, etc. Everything for this stuff is similar
to what works in R2 and R3. Here I will be
chiefly interested in what happens for other, bigger, n's.
Length/norm and inner product
I'll do it for Rn but I have in mind constantly a more complicated
example we'll be doing later: Fourier series, where things will be
the same but not the same (stay in the course, and you will see what I
mean). So the length or norm of a vector v is
sqrt([a1]2+[a2]2+...+[an]2).
This is, of course, an "echo" of the Pythagorean theorem to measure
distances between two points. I will remark right now that your
intuition may be weak. For example, if you consider the n-dimensional
unit cube (all coordinates between 0 and 1) then
most of the corners are very, very far away from the origin. Why?
Well, just look at the farthest corner, (1,1,...,1). In R560
its distance from the origin is sqrt(560), already fairly large! I
then defined the inner product of two vectors,
v=(a1,a1,...,an) and
w=(b1,b1,...,bn).
This is
v·w=SUMj=1naj·bj.
So the inner product (or dot product) gives a real number for two
vectors. Basic inner product properties should all look familiar:
v·w=w·v (commutativity),
(v1+v2)·w=v1·w+v2·w
(linearity in the first variable, and because of commutativity, the
same in the other variable), and
(tv)·w=t(v·w) (scalar multiplication
"comes out" of dot product).
As I mentioned above, sometimes "intuition" (principally the result of computing
lots and lots of examples) can't be trusted, but
something wonderful does happen.
Cauchy-Schwarz inequality
For v and w in Rn,
|v·w|<=||v|| ||w||. I tried to
explain why this is true (or see p.224 of the text). I looked at
(v+tw)·(v+tw). Since this is the norm
squared of the vector v+tw, the quantity must be
non-negative. "Expand it out", using linearity in both factors and
commutativity of the dot product. The result is
v·v+(2v·w)t+w·wt2.
If you look carefully at this, you can see several things. If the
vectors are "fixed" and t varies, this is a quadratic function in t:
At2Bt+C (maybe with peculiar A and B and C, though). I
remarked that the graph was a parabola. Since A is non-negative (A is
the square of a norm) the parabola opens up. Since the whole
quadratic function is also a norm squared, it can either be in the
upper half plane or, at worst, it could just touch the t-axis. Now the
roots of a quadratic are [-B+/-sqrt(B2-4AC)]/(2A). The
quadratic should not have two real roots (otherwise it will be
negative for some values of t, which is impossible). So the
discriminant should be non-negative: B2-4AC<=0. When I
replaced A and B and C with the weird coefficients above, and cleared
up the algebra, I got the Cauchy-Schwarz inequality. I went through
this is detail because I will need a similar computation later when we
do Fourier series.
Consequences of Cauchy-Schwarz
Well, we could prove the triangle inequality:
||v+w||<=||v||+||w|| but I don't feel
like it. It is true, though (square both sides, "expand"
(v+w)·(v+w), and do algebra).
So the distance in R5 from
(1,2,3,4,5) to (3,4,5,6,7) is less than or equal to the distance from
(1,2,3,4,5) to (-2,2,-2,2,13) plus the distance from (-2,2,-2,2,13) to
(3,4,5,6,7). (Do not check this, but accept my assurance!) What's more
interesting is now we can define angles. Why? In earlier courses, you
should have seen the law of cosines used to get an alternate
description of v·w, as equal to
||v|| ||w||cos(theta), where theta
was the angle between the vectors. Cauchy-Schwarz says that the
quotient for the cosine part must be between -1 and 1. This is not
obvious. Why could the dot product of two vectors in R33 be
444 while the lengths of the vectors are 3 and 12. Cauchy-Schwarz says
this can't happen.
I think I finally did an example, something like (1,2,3,0,2) and
(2,-3,0,7,-1) in R5. Here one length is sqrt(18) and the
other is sqrt(53), while the dot product is -6. So the angle between
these vectors is arccos(-6/(sqrt(18)sqrt(53))). The minus sign
indicates that the angle is between Pi/2 and Pi. Two vectors are
orthogonal or perpendicular if their dot product is 0.
Computational note
Most "higher level" computer languages recognize things like vector
addition and dot product, and usually compile the instructions to take
advantage of "vector" or parallel processing which is built into the
computer chips. So these things can be done really fast. Therefore it
is useful
computationally to see the vector operations in your work.
DEFINITION
Subspace
A collection of vectors S in Rn is a subspace if
- 0 is in S.
- The sum of vectors in S is in S.
- The scalar multiple of any vector in S is in S.
1. First I gave an S which was just two vectors: S={(1,2,3,0,0),(0,1,2,0,1)}. This is not a subspace because, for example, 0 is not in S.
2. I amended S a bit. I put (0,0,0,0,0) into the previous S. Now people said this S still wasn't a subspace because the sum of (1,2,3,0,0) and (0,1,2,0,1) wasn't in S, so that rule #2 isn't satisfied. And then we discussed more: we could sort of add vectors etc. Things still wouldn't work, because of rule #3.
3. Here's a different sort of example. I define S by a descriptive phrase which will be much more common in this course: S was the collection of vectors (a+b,2a,3a-b,3b,a) where a and b are any real numbers. In this case, I worked hard at proving that all of the rules (#1, #2, #3) were satisfied. If we look at the underlying "structure", this S consists of a(1,2,3,0,1)+b(1,0,-1,3,0). We will call this a linear combination of the two vectors. I sort of tried to draw a picture (a five-dimensional picture?) of this S. It seems to be a two-dimensional thing (a plane) which passes through 0. We will have to make everything more precise.
4. Here is another way where an example will be presented systematically. Suppose u=(1,-1,2,3,4) and w=(3,1,-2,0,5). My candidate for an S will be the collection of vectors v in R5 so that v·u=0 and v·w=0. That is, the collection of all v's which are perpendicular to both u and w. I tried, not too successfully, to draw a picture of the situation, and persuade the class that this was indeed a subspace. How about an algebraic view? Well, consider rule #2 of the subspace stuff. If v1·u=0 and v2·u=0 then v1·u+v2·u=0 and (linearity!) (v1+v2)·u=0. The same thing would happen with the "·w" requirement. And also with scalar product, etc. This is a subspace. It is not immediately clear to me what the "dimension" of S is. It will turn out to be that the dimension will be 3. But this will take a bit of effort.
The QotD was: consider the vectors in R4 with the following description: (a+b,a,3b-a,c) where a and b are any real numbers, and where c is any integer, positive or negative or 0. Is this a subspace? Well, for example, a=0 and b=0 and c=56 gives us the vector (0,0,0,0,56) in our candidate for a subspace. Well, if we try to multiply this be 1/(17) we will get something not in S, contradicting rule #3. So this S is not a subspace. Logically, we need to show a specific example to be sure that the rule is really broken, not that is might be broken. Oh well, this is a delicate point of logic.