 The instructor first wasted time by returning lots and lots and lots
of homework. This was silly. He will, as it gets colder, consider
burning the stuff for heat instead. Of course, there was an early
commemoration of a holiday. Several of the instructor's brain cells
died today, as he demonstrated once again his inability to
distinguish between rows and columns. Oh well. This was in today's
second example. Let's do it correctly, here. The very last linear
algebra presentation and he dropped the ball, he let loose the parrot,
he graffled the snook, etc. He didn't do things correctly. I am
sorry.
The instructor first wasted time by returning lots and lots and lots
of homework. This was silly. He will, as it gets colder, consider
burning the stuff for heat instead. Of course, there was an early
commemoration of a holiday. Several of the instructor's brain cells
died today, as he demonstrated once again his inability to
distinguish between rows and columns. Oh well. This was in today's
second example. Let's do it correctly, here. The very last linear
algebra presentation and he dropped the ball, he let loose the parrot,
he graffled the snook, etc. He didn't do things correctly. I am
sorry.
Mr. Dwyer kindly had his work on the previous QotD put on the board. Please, students, you should be able to find eigenvalues and eigenvectors of very simply matrices!
Example 1
Last time we saw that the matrix A=
(5 2) (3 4)had eigenvalues 7 and 2, and, associated with those eigenvalues were the eigenvectors (1,1) and (2,-3), respectively. (Notice that you'd better keep track of which is associated with which, or things get ... wrong ... later.) I noticed that multiplication by A changes (1,1) into 7 times (1,1) and changed (2,-3) into 2 times (2,-3). What happens to, say, (78,-34)? The answer is not clear. But if I could described (78,-34) in terms of the basis {(1,1),(2,-3)} then the result would be clear. I tried to describe a philosphy.
Philosophy or hope or ...
I have a basis of eigenvectors. Maybe I can rethink multiplication by
A into three stages. Here I will start with a vector described in
terms of the standard basis (1,0) and (0,1).
I want to change (1,0) as a column vector to (1,1) and change (0,1) as a column vector to (2,-3). So I need to find a matrix M which does the following:
(a b)(1) is (1) and (a b)(0) is ( 2). (c d)(0) (0) (c d)(1) (-3)This isn't too difficult: a and c are specified by the first requirement and b and d are specified by the second requirement. Therefore M=
(1 2) (1 -3)
How can I undo switching information from the standard basis to the basis of eigenvectors? "Clearly" I should find M-1:
(1 2 | 1 0)~(1 2 | 1 0)~(1 0 | 3/5 2/5 ) (1 -3 | 0 1) (0 -5 | -1 1) (0 1 | 1/5 -1/5 )
A multiplication
I computed M-1AM. I noted that this could be computed in
two ways, as (M-1A)M or as
M-1(AM). Matrix multiplication is
associative so you can regroup as you wish. It is not
always commutative (recalled the first linear
algebra QotD!) so you can't change the order of the matrices you
are multiplying.
M-1 A M-1AM (3/5 2/5)(5 2) is (21/5 14/5) and then (21/5 14/5)(1 2) is (7 0). (1/5 -1/5)(3 4) ( 2/5 -2/5) ( 2/5 -2/5)(1 -3) (0 2)I'll call the diagonal matrix just D. You should see, I hope, that this computation verifies the philosphy above. Finding an invertible matrix M and a diagonal matrix D so that M-1AM=D is called diagonalization.
Why do this?
This is a very appropriate question (voiced by Mr. Novak, I believe). Well, computations
with diagonal matrices are very easy. For example,
(7 0)(7 0) is just (49 0). (0 2)(0 2) ( 0 4)So D2 is gotten just by squaring the diagonal entries (one can do this in parallel, actually). Well, so if I want to compute D50 then I would just have as answer
(750 0 ) ( 0 250)But what if I wanted A50? Since I know that M-1AM=D, I then know that A=MDM-1. Be very clear about this: I left multiply the first equation by M and right multiply it by M-1 to get the second equation. I don't use commutativity, but I do use associativity. Then what is A50? We write:
Why do this?
Why? We can now efficiently compute, say,
17A98-56A14+.002A7 because
17A98-56A14+.002A7=M(17D98-56D14+.002D7)M-1
and 17D98-56D14+.002D7 is
the same
as
(17·798-56·714+.002·77 0 ) ( 0 17·298-56·214+.002·27)
Why do this?
Everybody (well, all engineers, at least!) wants to solve differential
equations. So let us look at a linear system of ordinary differential
equations (the more ways you know
to solve the darn things, the better):
{dx/dt}=5x(t)+2y(t)
{dy/dt}=3x(t)+4y(t)
If we make X(t) the column vector corresponding to (x(t),y(t)), then
this system can be abbreviated in matrix form as X'(t)=AX(t). By
analogy with the scalar case, I would hope that a solution could be
written as X(t)=eAt(Const), and here the (Const) would be a
2 by 1 column vector of initial conditions: x(0) and y(0). Let's see
what happens:(SUMn=0infinity(7t)n/(n!) 0)=(e7t 0) (0 SUMn=0infinity(2t)n/(n!))=(0 e2t)and this means that the solution should be
(1 2)(e7t 0 )(3/5 2/5) (1 -3)( 0 e2t)(1/5 -1/5)Here is what Maple reported as the product of this with the x(0) and y(0) column vector:
([[(3/5*exp(7*t)+2/5*exp(2*t))*x(0)+(2/5*exp(7*t)-2/5*exp(2*t))*y(0)], [(3/5*exp(7*t)-3/5*exp(2*t))*x(0)+(2/5*exp(7*t)+3/5*exp(2*t))*y(0)]])The first entry is x(t) and the second is y(t). You could check that this does satisfy the system of ODE's. And that's a reason why we do this. For those of you who know something about probability, what we've done makes computing certain aspects of Markov chains easier, also (transition probabilities).
Let's go on to the dreadful second example. Here I wanted to analyze the matrix C given by
( 0 -1 1) (-1 1 2) ( 1 2 1)which people realized immediately was not very random. It had small integer entries, since I am lazy and I wanted to do all aspects of the computation on the board, correctly. Sigh. Also this matrix was symmetric. Symmetric matrices arise frequently is real computations (for example, the distance from cityi to cityj is the same as the distance from cityj to cityi).
Analysis of C
This didn't go badly but I was running out of time and getting
nervous. It probably showed. Sigh. Now the characteristic polynomial
of C is
(-which I computed somehow (thank you Mr. Lin!) and it was what I thought it would be. Maple has the following command:-1 1) det(-1 1-
>charpoly(C,x);
3 2
x - 2 x - 5 x + 6
and the eigenvalues turn out to be 1, -2, and 3. I found one
eigenvector, and students, as their QotD found the others.
Doing it correctly ...
We noticed that the eigenvectors were all perpendicular (in mathspeak:
orthogonal). That was nice. The matrix for the first part of the
philosophy (eigenvectors into columns) was P=
( 2 -1 0) (-1 -1 1) ( 1 1 1). Now look at Pt:
( 2 -1 1) (-1 -1 1) ( 0 1 1)I (should have) computed PtP. This is
(6 0 0) (0 3 0) (0 0 2)If the result were the identity (I3) then the transpose would have been the inverse. Well, the result is diagonal, which happens because of the orthogonality of the eigenvectors. And then I could get the transpose to be the inverse by simply changing the lengths of the eigenvectors (you can multiply eigenvectors by non-zero constants and they stay eigenvectors). So let's change things a bit. Take P to be
( 2/sqrt(6) -1/sqrt(3) 0 ) (-1/sqrt(6) 1/sqrt(3) 1/sqrt(2)) (-1/sqrt(6) 1/sqrt(3) 1/sqrt(2))and then the transpose of P will be P-1. This really is remarkable.
The major result
We can diagonalize the symmetric matrix C using a matrix of normalized
eigenvalues. The eigenvalues are orthogonal, and the resulting matrix
used for changing bases has the wonderful property that its inverse is
its transpose. A matrix P such that P-1=Pt
is called orthogonal.
This is always true for symmetric matrices:
| Every symmetric matrix has a basis of orthogonal eigenvalues, which, when normalized, form an orthogonal matrix. The matrix of eigenvalues and its inverse/transpose diagonalize the symmetric matrix. |
This result is not easy to prove, and is usually the triumph (?) of our Math 250 course.
HOMEWORK
Please read sections 8.8, 8.10, and 8.12 of the text. The following
problems almost surely can be done easily by Maple or
Matlab or any grown-up calculator. I strongly urge
students to do these problems by hand and get the correct
answers.
8.8: 13, 19.
8.10: 15
8.12: 5, 13, 39.
>A:=matrix(2,2,[5,2,3,4]);
[5 2]
A := [ ]
[3 4]
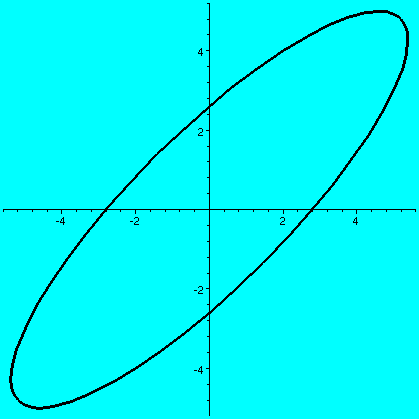
>plot([5*cos(t)+2*sin(t),3*cos(t)+4*sin(t),t=0..2*Pi],
thickness=3,color=black);
|
|
>B:=evalm(A^2);
[31 18]
B := [ ]
[27 22]
>plot([31*cos(t)+18*sin(t),27*cos(t)+22*sin(t),t=0..2*Pi],
thickness=3,color=black);
|
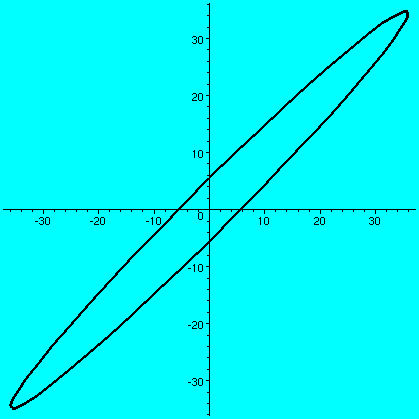
|
>eigenvects(A);
[2, 1, {[1, -3/2]}], [7, 1, {[1, 1]}]
 So we are looking at the effect of the matrix on the unit
circle, those points (x,y) in the plane which can be written as
(cos(t),sin(t)) for t between 0 and 2Pi. This is a circle. Then a
matrix, A, creates what is called a linear transformation,
which is a mapping taking R2 to R2 and taking
linear combinations in the domain to corresponding linear combinations
in the range.
So we are looking at the effect of the matrix on the unit
circle, those points (x,y) in the plane which can be written as
(cos(t),sin(t)) for t between 0 and 2Pi. This is a circle. Then a
matrix, A, creates what is called a linear transformation,
which is a mapping taking R2 to R2 and taking
linear combinations in the domain to corresponding linear combinations
in the range.
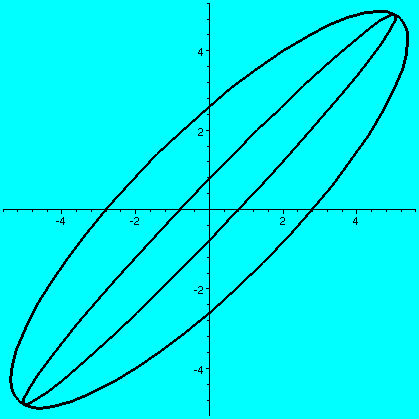
(a b) (c d)and if a vector X in R2 is (x1,x2), then AXt (the transpose changes the row vector to a column vector) is (back in row vector form [another transpose]) the point (ax1+bx2,cx1+dx2). What does this look like geometrically? The circle gets distorted geometrically. It turns out that for many matrices, the figure obtained will be an ellipse, with (0,0) as center of symmetry. The biggest stretch of this ellipse is in a certain direction. If we then multiply again by A, (that's B in this case, the evalm command in Maple asks it to do arithmetic on matrices) the picture is another matrix. Because the pictures are a bit difficult to compare, I asked Maple to rescale (important!) and graph both pictures together. The B picture is the narrower one, inside the A picture's ellipse. One way to find this principal preferred direction, where A seems to want to send stuff, is (as I tried to suggest in class) to take a point on the circle at random. Then some high power of A will likely send it more or less in about the correct direction (!!). This direction is called an eigenvector.
Ms. Horn asked why I looked at the unit circle. Well, if you give me all information about what happens on the unit circle, then I will know what happens everywhere. For example, I could ask what happens to (15,-48). Call sqrt({15}2+{48}2), w. Then (15,-48)=w(15/w,-48/w). If everything is linear, and if I know what happens to the unit circle then the w factor on the outside will just multiple what happens to (15/w,-48/w), a vector on the unit circle. So it you know that, then you know "everything"
|
|
Understanding eigenvalues and eigenvectors is important if you are
going to any sort of extensive computation with matrices (by hand, by
computer, by thinking). As I observed in class, the requirement that
an eigenvector be not equal to 0 is very important. Without it,
any value ![]() is an eigenvalue! Eigen{value|vector} is also called
characteristic {value|vector} and proper {value|vector}, depending on
what you read and what you work with.
is an eigenvalue! Eigen{value|vector} is also called
characteristic {value|vector} and proper {value|vector}, depending on
what you read and what you work with.
Example
As requested by Mr. Huertas, I worked
out the details, the indispensable details, of course, for the example
which generated the pictures above. So A=
(5 2) (3 4)and if X is (x1,x2) then we would like to find solutions of the system corresponding to the matrix equation AXt=
5x1+2x2=and this sytem is the same as
(5-. I want non-trivial solutions to this homogeneous system. This is the same as asking that the RREF of the system's coefficient matrix is not equal to I2, the 2-by-2 identity matrix. And this is the same as asking that the system's coefficient matrix be singular. We can test for singularity by asking for which
(5-has determinant 0. It is easy to find the determinant of this matrix: it is (5-
|
|
The roots of ![]() 2-9
2-9![]() +14=0 are 7 and 2. Nice people like
Ms. Julien factor this
polynomial. People like me, who wear suspenders and a belt on their
pajamas, use the quadratic formula. By the way, there is no general
formula for the roots of a polynomial, and frequently numerical
approximation schemes are needed. Knowing these values of
+14=0 are 7 and 2. Nice people like
Ms. Julien factor this
polynomial. People like me, who wear suspenders and a belt on their
pajamas, use the quadratic formula. By the way, there is no general
formula for the roots of a polynomial, and frequently numerical
approximation schemes are needed. Knowing these values of ![]() doesn't end our task. I would like
to find eigenvectors for each of these eigenvalues.
doesn't end our task. I would like
to find eigenvectors for each of these eigenvalues.
![]() =7
=7
Go back to the homogeneous system
(5-and plug in
-2x1+2x2=0 3x1-3x2=0and the equations are a multiple of one another, so solutions are what solves x1-x2=0. One solution is (1,1). Another is (-46,-46). Etc.
Facts about eigenvectors
Any non-zero multiple of an eigenvector is also an
eigenvector. Any non-zero sum of eigenvectors associated to the same
eigenvalue is also an eigenvector. In practice, I suggest you choose
some useful way of specifying an eigenvector. Different computational
packages may give different answers. Sometimes this can be annoying.
![]() =2
=2
Now plug in ![]() =2 in the homogeneous system. The result is
=2 in the homogeneous system. The result is
3x1+2x2=0 3x1+2x2=0and again the equations are multiples of one another (no surprise, because we have selected
Why do this, and why do the pictures look the way
they did?
Well we now know that (1,1) is an eigenvector associated to the
eigenvalue 7 and (2,-3) is an eigenvector associated to the eigenvalue
2. I can create a vector, let's see: 5(1,1)+3(2,-3)=(11,-4). Weird,
but o.k. Now I can ask what effect multiplication by A has on this
vector (actually on the transpose of the vector, changing it from a
row vector to a column vector, but few people bother being that
linguistically pure). I could compute the product of the matrix A with
the vector, or just notice that due to linearity, the effect is 5
multiplied by what A does to (1,1) plus 3 multiplied by what A does to
(2,-3). Since the affected vectors are eignevectors, I can
tell you the result easily: 5·7(1,1)+3·2(2,-3). There is
no purpose to doing the arithmetic, and in fact if I did the
arithmetic, things would be less comprehensible. Notice, please, that
(1,1) and (2,-3) are linearly independent. Since they are two linearly
independent vectors in R2 they form a basis of
R2 and every vector in R2 can be written as a
linear combination of these two. If I am going to do extensive
computations with A, it is much better to write things in terms of
this basis than the standard basis, (1,0) and (0,1). In fact, let's
see: suppose I want to "find" the result of multiplying
5(1,1)+3(2,-3) by the matrix A5.
This will be
5·75(1,1)+3·25(2,-3). This is also
75(5(1,1)+3·.002(2,-3)
). The .002 is the approximate value of
(2/7)5. So this vector points almost totally in the
direction of the eigenvector. Hey! The ellipses above will get
narrower and narrower very fast!
Material science, physics, stress, strain, and many other things I
don't know about
I mentioned that finding eignevalues and eigenvectors was important in
understanding the structure of materials. This went nowhere since I
got a number of questions and had to admit ignorance very soon. I went
to Google and found over 25,000 pages listed in response to
the query crystal structure eigenvalues. Oh well ...
I haven't exactly lied to you ...
Things don't have to be as nice as the behavior of the example I
analyzed. You won't always get a basis of eigenvectors. Here are two
simple examples.
#1
If A=
(2 17) (0 2)then det(A-
(0 17) (0 0)are non-zero multiples of (1,0) since 0x1+17x2=0 forces x2 to be 0.
#2
If A=
(0 -1) (1 0)then det(A-
My next example became the QotD since I was informed that the
poor chemical engineers had an example following the class. How they
suffer!
Anyway, I asked for eigenvalues and eigenvectors of the matrix
A=
(2 17) (0 3)
| The matrix A | The result of the
Maple command eigenvects(A) |
|---|---|
(5 2) (3 4) | [2, 1, {[1, -3/2]}], [7, 1, {[1, 1]}] |
(2 17) (0 2) | [2, 2, {[1, 0]}] |
(0 -1) (1 0) | [I, 1, {[1, -I]}], [-I, 1, {[1, I]}] |
(2 17) (0 3) | [3, 1, {[17, 1]}], [2, 1, {[1, 0]}] |
The Oxford English Dictionary lists the first appearance of paradigm in 1483 when it meant "an example or pattern", as it does today.
But you must know for the purposes of this course some standard computational methods of evaluating determinants. So I'll tell you about row operations and cofactor exponasions.
| Row operations and their effects on determinants | ||
|---|---|---|
| The row operation | What it does to det | |
| Multiply a row by a constant | Multiplies det by that constant | |
| Interchange adjacent rows | Multiplies det by -1 | |
| Add a row to another row | Doesn't change det | |
Examples
Suppose A is this matrix:
( -3 4 0 18 ) ( 2 -9 5 6 ) ( 22 14 -3 -4 ) ( 4 7 22 5 )Then the following matrix has determinant twice the value of det(A):
( -6 8 0 36 ) ( 2 -9 5 6 ) ( 22 14 -3 -4 ) ( 4 7 22 5 )because the first row is doubled.
( -3 4 0 18 ) ( 22 14 -3 -4 ) ( 2 -9 5 6 ) ( 4 7 22 5 )because the second and third rows are interchanged. Notice that you've got to keep track of signs, so that if we interchange, say, the second and fourth rows leaves the value of the determinant would not be changed.
( -3 4 0 18 ) ( 2 -9 5 6 ) ( 24 5 2 2 ) ( 4 7 22 5 )because I got it by adding the second row to the third row and placing the result in the third row.
Silly examples (?)
Look:
( 1 2 3 ) ( 2 3 4 ) det( 4 5 6 )=det( 3 3 3 ) (row2-row1) ( 7 8 9 ) ( 3 3 3 ) (row3-row2)Now if two rows are identical, the det is 0, since interchanging them both changes the sign and leaves the matrix unchanged. So since det(A)=-det(A), det(A) must be 0.
( 1 4 9 16 ) ( 1 4 9 16 ) ( 1 4 9 16 ) det( 25 36 49 64 )=det( 24 32 40 48 ) (row2-row1)=det( 24 32 40 48 ) ( 81 100 121 144 ) ( 56 64 72 80 ) (row3-row2) ( 32 32 32 32 ) (row3-row2) ( 169 196 225 256 ) ( 88 96 104 112 ) (row4-row3) ( 32 32 32 32 ) (row3-row2)so since the result has two identical rows, the deteminant of the original matrix must be 0.
There are all sorts of tricky things one can do with determinant evaluations, if you want. Please notice that the linear systems gotten from, say, the finite element method applied to important PDE's definitely give coefficient matrices which are not random: they have lots of structure. So the tricky things above aren't that ridiculous.
Use row operations to ...
One standard way of evaluating determinants is to use row operations
to change a matrix to either upper or lower triangular form (or even
diagonal form, if you are lucky). Then the determinant will be the
product of the diagonal terms. Here I used row operations (actually I
had Maple use row operations!) to change this random (well, the
entries were produced sort of randomly by Maple) to an
upper-triangular matrix.
[1 -1 3 -1] And now I use multiples of the first row to create 0's
[4 4 3 4] below the (1,1) entry. The determinant won't change:
[3 2 0 1] I'm not multiplying any row in place, just adding
[3 1 3 3] multiples of row1 to other rows.
[1 -1 3 -1] And now multiples of the second row to create 0's
[0 8 -9 8] below the (2,2) entry.
[0 5 -9 4]
[0 4 -6 6]
[1 -1 3 -1] Of course, multiples of the third row to create
[0 8 9 8] 0's below the (3,3) entry.
[0 0 -27/8 -1]
[0 0 -3/2 2]
[1 -1 3 -1 ] Wow, an upper triangular matrix!
[0 8 -9 8 ]
[0 0 -27/8 -1 ]
[0 0 0 22/9]
The determinant of the original matrix must be
1·8·(-27/8)·(22/9). Sigh. This should be -66,
which is what Maple told me was the value of the determinant
of the original matrix. And it is!
Minors
If A is an n-by-n matrix, then the (i,j)th minor of A is
the (n-1)-by-(n-1) matrix obtained by throwing away the
ith row and jth column of A.
For example, if A is
[1 -1 3 -1] [4 4 3 4] [3 2 0 1] [3 1 3 3]Then the (2,3) minor is gotten by deleting the second row and the third column:
>minor(A,2,3);
[1 -1 -1]
[3 2 1]
[3 1 3]Of course I had Maple do this, with the
appropriate command.
Evaluating determinants by cofactor expansions
This field has a bunch of antique words. Here is another. It turns out
that the determinant of a matrix can be evaluated by what are called
cofactor expansions. This is rather weird. When I've gone
through the proof that cofactor expansions work, I have not really
felt enlightened. So I will not discuss proofs. Here is the
idea. Suppose A is an n-by-n matrix. Each
(i,j) position in this n-by-n matrix has an associated minor which
I'll call Mij. Then:
Here: let's try an example. Suppose A is
[1 -1 3 -1] [4 4 3 4] [3 2 0 1] [3 1 3 3]as before. I asked Maple to compute the determinants of the minors across the first row.
> det(minor(A,1,1));
-3
> det(minor(A,1,2));
6
> det(minor(A,1,3));
-16
> det(minor(A,1,4));
-21
Remember that the first row is [1 -1 3 -1]
Now the sum, with the +/- signs, is
Recursion and strategy
You should try some examples, of course. This is about the only way I
know to learn this stuff. If I had to give a short definition of
determinant, and if I were allowed to use recursion, I think that I
might write the following:
Input A, an n-by-n matrix.
If n=1, then det(A)=a11
If n>1, then
det(A)=SUMj=1n(-1)j+1a1jdet(M1j)
where M1j is the (n-1)-by-(n-1) matrix obtaining by
deleting the first row and the jth column.
This is computing det(A) by repeatedly expanding along the first
row. I've tried to write such a program, and if you have the time and
want some amusement, you should try this also. The recursive nature
rather quickly fills up the stack (n! is big big
big) so this isn't too practical. But there are
certainly times when the special form of a matrix allows quick and
efficient computation by cofactor expansions.
More formulas
You may remember that we had a
A decision problem Given an n-by-n matrix, A, how can
we decide if A is invertible?
Here is how to decide:
A is invertible exactly when
det(A) is not 0.
Whether this is practical depends on the
situation.
There was also a
Computational problem If we know A is invertible, what is the
best way of solving AX=B? How can we create A-1
efficiently?
Well, this has an answer, too. The answer is on page 383 of the
text. The inverse of A is the constant (1/det(A)) multiplied by the
adjoint of A. I have to look this up. The adjoint is the
transpose (means: flip over the main diagonal, or, algebraically,
interchange i and j) of the matrix whose entries are
(-1)i+jdet(Mij).
I think this is hideous and the only example I have seen worked out in detail (enough to be convincing!) is n=2. So here goes:
A is (a b) and M11=d and M12=c and M21=b and M22=a
(c d)
Then the adjoint (put in +/- signs, put in transpose) is ( d -b)
(-c a).
Since the det is ad-bc, the inverse must be
( d/(ad-cd) -b/(ad-bc) )
(-c/(ad-cd) a/(ad-bc) )
If you mentally multiply this matrix by A you will get I2,
the 2-by-2 identity matrix. I hope! Check this, please!
So there will be times you might need to decide between using an algorithmic approach and trying to get a formula. Let me show you a very simple example where you might want a formula. This example itself is perhaps not too realistic, but maybe you can see what real examples might look like.
Suppose we need to understand the linear system
2x+7y=6
Qx+3y=Q
Well, if the parameter Q is 0, then (second equation) y=0 and
so (first equation) x=3. We could think of Q as some sort of
control or something. I tried inadequately to convey a sort of
physical problem that this might model, but the effort was perhaps not
totally successful. What happens to x and y when we vary Q,
for example, move Q up from 0 to a small positive number? I
don't think this is clear. But we can in fact find a formula for x and
y. This is sort of neat, actually. You may remember such a formula
from high school, even.
det( 6 7 ) det( 2 6 )
( Q 3 ) ( Q Q )
x= ---------- y= ----------
det( 2 7 ) det( 2 7 )
( Q 3 ) ( Q 3 )
so that x=(18-7Q)/(6-7Q) and
y=-4Q/(6-7Q). Now there are formulas, and I can ask
questions about them. What is the 6-7Q in the bottom? There's
must be some sort of trouble when Q is 6/7. What trouble is
there? On one level, hey, the trouble is that we aren't supposed to
divide by 0. On another level, the trouble is that the system
"collapses": the coefficient matrix is singular, not invertible, drops
down in rank from 2 to 1. So we shouldn't expect nice things to
ccur. But is Q is 0, and then increases a bit, you know we
could find out what happens to x (and y) by looking at dx/dQ
and dy/dQ etc. So there is a place for formulas.
Cramer's Rule
I think this is Theorem 8.23 (page 392) of the text. It discusses a
formula for solving AX=B where A is an n-by-n matrix with det(A) not
equal to 0, and B is a known n-by-1 matrix, and X is an n-by-1 matrix
of unknowns. Then xj turns out to be
det(Aj)/det(A), where Aj is the matrix obtained
by replacing the jth column of A by B.
Well, the QotD was computing part of an example when n=3 of this.
3x-5y+z=2
2x+5y-z=0
x-y+z=7
What is z? According to Cramer's Rule, z is
(3 -5 2)
det{2 5 0)
(1 -1 7)
------------
(3 -5 1)
det{2 5 -1)
(1 -1 1)
I think I computed the determinant on the top in several ways, once
with row operations, and once by cofactor expansions. Both gave
161. And, of course, there is this method:
>det(matrix(3,3,[3,-5,2,2,5,0,1,-1,7]));
161
The bottom determinant was what I asked people to compute. It is
> det(matrix(3,3,[3,-5,1,2,5,-1,1,-1,1]));
20
uhhhh ... twenty, yes, that's it, twenty. That's the answer to the
QotD. Or, actually, we can check another way:
> A:=matrix(3,4,[3,-5,1,2,2,5,-1,0,1,-1,1,7]);
[3 -5 1 2]
[ ]
A := [2 5 -1 0]
[ ]
[1 -1 1 7]
> rref(A);
[1 0 0 2/5]
[ ]
[ 29 ]
[0 1 0 -- ]
[ 20 ]
[ ]
[ 161]
[0 0 1 ---]
[ 20 ]
This is the augmented matrix corresponding to the original system, and
so z must be 161/20.
This class meeting itself seemed rather disorganized to me: lots of formulas. I apologize for not showing the formulas more effectively. I hope you will learn the more important ones, and remember that there are alternative ways of solving linear systems.
HOMEWORK
Please still read 8.4 and 8.5 and 8.7. Do these problems:
8.4: 25
8.5: 11-14, 21, 31
8.7: 1
Also, here are two problems for you
to do. You will get a prize!
| AX=B, where A is an n-by-n matrix | ||
|---|---|---|
considerations | ||
| Full rank; regular; non-singular; invertible | Singular | |
equation | AX=0 has only the trivial solution. | AX=0 has infinitely many solutions in
addition to the trivial solution. |
equations | AX=Y has a unique
solution for all Y. If you know A-1, then X=A-1Y | There are Y's for which AX=Y has no
solution; for all other Y's, AX=Y has infinitely many solutions |
There are really two problems here.
Algorithmically ...
Suppose A is an n-by-n matrix. We will augment the heck (??!) out of A
with an n-by-n identity matrix, In. Here In is
1 on the diagonal, and has 0 entries off the diagonal. Then we have
(A|In). Now run RREF on this. What I would like to see as
the end result is
(In|Some "stuff"). If this occurs, then A is
invertible, and Some
"stuff" is A-1, the inverse of A. If we can't get
In on the left, then A is not invertible.
How much work is computing A-1 this way? Here I used the word "work" in a rather elementary sense. I tried to convince people that a really rough bound on the number of arithmetic operations (add, multiply, divide, etc.) to find A-1 using this method is, maybe, 6n3. This actually isn't too bad. Finding A-1 this way is a problem which can be computed in polynomial time. Such problems are actually supposed to be rather nice computationally. In fact, the degree in n can actually be lowered substantially, I believe. People worry about this in the real world.
Well, this works. But there are alternate ways of thinking about the problem. Particularly, we can solve the decision probloem by computing the determinant of A, det(A). This is a number. If it is 0, then A is singular. If it is not 0, then A is invertible. If det(A) is not 0, it is then possible to write a formula for A-1, and we can also write a formula (called Cramer's rule) for finding the unique solution to AX=B. The problem is that the formulas needed are quite complicated.
First imagine that we have an n-by=n chessboard. Recall that a rook (the thing that looks like a castle) on a chessboard can move freely on rows and columns. (Recently published and not yet read by me: Birth of the Chess Queen which "sees the rise of female power throughout the centuries reflected in the history of the chess queen".) Anyway, I asked students for the largest number of rooks which could be put on a chessboard so that they don't attackone another. We thought for a while, and then decided that we could put one rook in each column and each row: thus a rook arrangement could have n rooks. In the diagrams below, I will use * for a rook placed on the board and 0 to indicate an empty position on the board.
How many different rook arrangements are there? Well, there are n
places to put a rook in the first column. Once a rook is placed there,
a whole row is eliminated for further rook placement. So there are n-1
places (non-attacking places!) to put a rook in the seoond column. And
there n-2 in the third column, etc. Some thought should convince you
that there are n! (n factorial) different rook arrangements. n! grows
very fast with n. Everyone should know, even just vaguely, the
Stirling approximation to n!. This says that n! is approximately
(n/e)nsqrt(2Pi n). In fact, Maple tells me
that 20! is exactly
2432 90200 81766 40000 while the Stirlling
approximation is
2422 78684 67611 33393.1 (about)
But I am not particularly interested in specific values of
factorials. The important fact is that the factorial function is
superexponential, and grows much faster, for example, than any
polynomial.
Each rook arrangement has a sign attached to it, either a + or -. This sign is gotten by computing (-1)# where what matters is the parity (even or oddness) of the number. What's the number? For each rook, look in the rook's "first quadrant", up and to the right. Count the rooks there. Then take the total or all of the "first quadrant" rooks for each of the rooks. That's the number, #. Here are two examples.
(* 0 0 0 0) First quadrant has 0 rooks. (0 0 0 0 *) First quadrant has 0 rooks. (0 0 * 0 0) First quadrant has 0 rooks. (0 0 0 * 0) First quadrant has 1 rook. (0 * 0 0 0) First quadrant has 1 rook. (* 0 0 0 0) First quadrant has 2 rooks. (0 0 0 0 *) First quadrant has 0 rooks. (0 * 0 0 0) First quadrant has 0 rooks. (0 0 0 * 0) First quadrant has 1 rook. (0 0 * 0 0) First quadrant has 1 rook. 1+1=2=#. 1+2+1=4=#.Since both of these #'s are even, the sign for both of these rook arrangements is +1. In general, it turns out that half of the rook arrangements have - signs and half have + signs.
Now for each rook arrangement, take the product of the terms in the matrix A which are in the rook places: the product of n entries of A. Then prefix this by the sign, (-1)# as mentioned above. And, then, finally, take the sum of this strange signed product over all n! rook arrangements. This sum is det(A).
I then worked out what the definition would be for 2-by-2 and 3-by-3 matrices. This turns out to be the same as the traditional formulas which I think students all know. How about 4-by-4? IMPORTANT I don't know any simple way to remember the definition in this case. I know no reason to try to remember the formula. The n=2 and n=3 cases are too darn simple! The formulas and scemes remembered from "childhood" will not work for n>3.
Determinants when n=2 The matrix A is
(a b) (c d)
| Formula for 2-by-2 determinants | ||
|---|---|---|
| Rook arrangement | (* 0) (0 *) | (0 *) (* 0) |
| # | ||
| Sign | ||
| Product with sign | ||
Determinants when n=3 The matrix A is
(a b c) (d e f) (g h i)
| Formula for 3-by-3 determinants | ||||||
|---|---|---|---|---|---|---|
| Rook arrangement | (* 0 0) (0 * 0) (0 0 *) |
(* 0 0) (0 0 *) (0 * 0) |
(0 * 0) (* 0 0) (0 0 *) |
(0 0 *) (* 0 0) (0 * 0) |
(0 * 0) (0 0 *) (* 0 0) |
(0 0 *) (0 * 0) (* 0 0) |
| # | ||||||
| Sign | ||||||
| Product with sign | ||||||
Determinants when n=4 (enough already!) Here is what Maple says:
> A:=matrix(4,4,[a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p]);
[a b c d]
[ ]
[e f g h]
A := [ ]
[i j k l]
[ ]
[m n o p]
> det(A);
a f k p - a f l o - a j g p + a j h o + a n g l - a n h k - e b k p +
e b l o + e j c p - e j d o - e n c l + e n d k + i b g p - i b h o -
i f c p + i f d o + i n c h - i n d g - m b g l + m b h k + m f c l -
m f d k - m j c h + m j d g
And this doesn't help me much.
There are lots and lots and lots of formulas for determinants. They all depend on various det properties. Here are some.
If you multiply the elements in one row of a matrix by a constant, then the determinant of that matrix is multiplied by that constant. That's because the entries in the sum for the det (see the n=4 examploe above) each have one peice from the one row, so we can factor out the constant.
Here is a more subtle property. If you interchange adjoining rows of a matrix, the determinant is multiplied by -1. This happens because the total # changes by 1 (either adds one or subtracts one) in every case, and then this factors out to make the sign change for the det.
Example 403.67
What is the determinant of the following matrix?
( 3 5 17 2 0 ) (-2 4 8 -1 4 ) ( 7 2 -4 -4 31 ) ( 6 2 8 8 12 ) ( 6 -12 -24 3 -12 )This is an example arranged by an instructor. Look at row 5. The det of this matrix is -3 multiplied by the det of the matrix
( 3 5 17 2 0 ) (-2 4 8 -1 4 ) ( 7 2 -4 -4 31 ) ( 6 2 8 8 12 ) (-2 4 8 -1 4 )(common factor of row 5). But the det of this is -1 multiplied by the det of
( 3 5 17 2 0 ) (-2 4 8 -1 4 ) ( 7 2 -4 -4 31 ) (-2 4 8 -1 4 ) ( 6 2 8 8 12 )(interchange rows 4 and 5). And then another - gets us to
( 3 5 17 2 0 ) (-2 4 8 -1 4 ) (-2 4 8 -1 4 ) ( 7 2 -4 -4 31 ) ( 6 2 8 8 12 )But now what? If we interchange rows 2 and 3, we keep the same matrix. The det changes by -1 but also stays the same. Hey, there is only one number like that, 0. So the determinant of the original matrix is 0. This is not obvious and is an arranged example!
Example 309.67
What is the determinant of the following matrix?
( 3 -2 7 8 99 6 ) ( 0 3 3/4 -1 Pi .7 ) ( 0 0 3 -9 77 .4 ) ( 0 0 0 3 -3 13 ) ( 0 0 0 0 3 -9 ) ( 0 0 0 0 0 3 )Hey! The only rook arrangement which doesn't have a 0 is the main diagonal, and that has #=0, so (-1)0=1. Therefore, the determinant of this upper triangular matrix is just the product of the main diagonal entries, or 36=729. Hey!
QotD
What is the determinant of
( 0 0 0 0 E ) ( 0 0 0 D 0 ) ( 0 0 C 0 0 ) ( 0 B 0 0 0 ) ( A 0 0 0 0 )This is ABCDE multiplied by a sign, and the # here is 4+3+2+1=10, so (-1)10=1, and the determinant is ABCDE.
HOMEWORK
What I am doing is generally not in the text. Please read the
textbook's relevant sections: 8.4 and 8.5 and 8.7.
Here is my version of the diagram in HTML:
For m linear equations in n unknowns AX=B
Two cases: B=0 and B not 0. Let rank(A)=r.
AX=0
|
|
|
\ /
v
-----------------------------------
| |
| |
| |
\ / \ /
v v
Unique sol'n: X=0 Infinite number of sol'ns.
rank(A)=n rank(A)<n, n-r
arbitrary parameters
in the sol'n
AX=0, B not 0
|
|
|
\ /
v
-----------------------------------
| |
| |
| |
\ / \ /
v v
Consistent Inconsistent
rank(A)=rank(A|B) rank(A)<rank(A|B)
|
|
|
\ /
v
----------------------------------
| |
| |
| |
\ / \ /
v v
Unique solution Infinite number of sol'ns
rank(A)=n rank(A)<n-r
arbitrary parameters
in the sol'n
Let try to offer a gloss on this diagram, which maybe looks simple but
covers so many different situations which you will enounter.
gloss 1. [Linguistics][Semantics] a. an explanatory word or phrase inserted between the lines or in the margin of a text.First, consistent means the system has solutions, and inconsistent means there are none. Here is a tabular listing of the alternatives, if you find this more palatable. The B=0 case, the homogeneous system, always has the trivial solution (used for, say, deciding linear independence). So the B=0 case is always consistent. Two alternatives can occur:
| AX=0: m equations in n unknowns; B=0 | |
|---|---|
| I | II |
| Unique sol'n: X=0 rank(A)=n |
Infinite number of solutions. rank(A)<n, n-r arbitrary parameters in the solutions |
When B is not zero then we've got:
| AX=0: m equations in n unknowns; B not 0 | ||
|---|---|---|
| Consistent rank(A)=rank(A|B) | Inconsistent rank(A)<rank(A|B) | |
| III | IV | V |
| Unique solution rank(A)=n |
Infinite number of solutions
rank(A)<n-r arbitrary parameters in the solutions |
No solutions |
By the way, I do not recommend that you memorize this information. No one I know has done this, not even the most compulsive. But everyone I know who uses linear algebra has this installed in their brains. As I mentioned in class, I thought that a nice homework assignment would be for students to find examples of each of these (in fact, there have already been examples of each of these in the lectures!). The problem with any examples done "by hand" is that they may not reflect reality. To me, reality might begin with 20 equations in 30 unknowns, or maybe 2,000 equations ....
So I just gave 6 examples which we analyzed in class. These examples are (I hope!) simple (m=number of equations; n=# of variables; r=rank(A), where A is the coefficient matrix):
( 2 3)~( 1 3/2)~( 1 0 ) (-5 7) ( 0 29/2) ( 0 1 )I think you could already have seen that the rows of this 2-by=2 matrix were linearly independent just by looking at it (don't try "just looking at" a random 500-by-300 matrix!), so r=2. This is case II. There is a unique solution, x=0 and y=0, the trivial solution.
( 2 3 | 1)~( 1 3/2 | 1/2)~( 1 0 | 1/2 - (3/2)·(9/29)) (-5 7 | 2) ( 0 29/2 | 9/2) ( 0 1 | 9/29 )we are in case III, with exactly one solution which row reduction has produced: x=1/2-(3/2)·(9/29)) and y=9/29.
( 2 3 | 1) ( 1 3/2 | 1/2) ( 1 0 | 1/2 - (3/2)·(9/29)) (-5 7 | 2)~( 0 29/2 | 9/2)~( 0 1 | 9/29 ) ( 4 5 | 3) ( 0 -1 | 1 ) ( 0 0 | 1-(9/29) )I am lazy and I know that 1-(9/29) is not 0, so the row reduction showed that rank(A)=2<rank(A|B)=3: case V, with no solutions.
Heuristic, the word
adj. 1. allowing or assisting to discover. 2. [Computing] proceeding to a solution by trial and error. "heuristic method"[Education] a system of education under which pupils are trained to find out things for themselves.heuristic gives 882,0000 hits on Google and adding engineering to that reduces the number to "only" about 181,000. Indeed.
Heuristic linear algebra (?)
When I had Maple create random 3-by 5 matrices for the RREF
samples I gave students last time, almost all of the matrices created
had rank 3. In fact, lots of experimentation shows that matrices
want to be the highest possible rank. There are reasons for
most examples created in courses or examples which occur in nature
which have lower than the highest possible rank. In fact, as I
remarked in class, if you measure a physical process at 17 different
points, and do this 300 times, and create a 300-by-17 matrix, and then
do row reduction, there should be a reason why the resulting rank is
not 17. (Of course, in reality, there's all sorts of sources of
measurement and analytic error, but ... I don't do reality.) Now
looking at the possible alternatives I through V for linear systems,
the most interesting occur when A is square and has maximal
rank. That's what I will concentrate on right now.
Another silly example
The system
3x+4y=1 5x+6y=0So let's RREF:
(3 4 | 1)~(1 4/3 | 1/3)~(1 0 | -3) (5 6 | 0) (0 -2/3 | -5/3) (0 1 | 5/2)and the unique solution is x=-3 and y=5/2.
And another
The system
3x+4y=0 5x+6y=1So let's RREF:
(3 4 | 0)~(1 4/3 | 0)~(1 0 | 2 ) (5 6 | 1) (0 -2/3 | 1) (0 1 | -3/2)and the unique solution is x=2 and y=-3/2.
More, even?
The system
3x+4y=578 5x+6y=394Enough with this RREF stuff already. We can get a solution by pure thought from what we have already done:
Solved 'em all, at least for this coefficient matrix!
The system
3x+4y=u 5x+6y=vThis system has solutions
( -3 2 )(u) ( 5/2 -3/2)(v)so knowing the matrix
( -3 2 ) ( 5/2 -3/2)allows us to solve easily every equation where the coefficient matrix is
( 3 4 ) ( 5 6 )My brain understands things better when it builds upon previously known patterns, and it seems that many other people share this property. Therefore we define:
Definition Suppse A is an n-by-n matrix. Then the inverse of A, usually written A-1, is an n-by-n matrix whose product with A is the n-by-n identity matrix, In (a square matrix with diagonal entries equal to 1 and offdiagonal entries equal to 0).
Now if
A=( 3 4 ) and, say, C= ( -3 2 ) you can check that AC=(1 0)=I2 ( 5 6 ) ( 5/2 -3/2) (0 1)so that C is A-1. Solving the linear system AX=B where
X=(x) and B=(u) (y) (v)can be done by multiplying AX=B by C on the left, and we get
An algorithm for finding inverses
If A is a square matrix then augment A by In, an identity
matrix of the same size: (A|In). Use row reduction to get
(In|C). Then C will be A-1. If row reduction is
not successful, A does not have an inverse (this can happen: rank(A)
could be less than n).
Vocabulary
A matrix which has no inverse is called singular. A matrix
which has an inverse is called invertible or
non-singular or regular.
A Math 250 exam problem, which was the QotD
I gave a problem very much like this on a Math 250 exam. So:
Suppose A is a 3-by-3 matrix and you know that A-1 is
(3 2 -1) (0 2 5) (7 3 7)and that Y=
( 2) (-1) ( 2).Find X solving AX=Y.
( 1) (13) (32)HOMEWORK
The exam comes back
I returned the first exam. In this course, I try to help you learn
in several different ways (lectures, QotD's, this diary, office hours,
e-mail). Another important aspect of what I do in the course is write
exams and then report the grades. I try to give exams which are
written and graded fairly. I would be very happy if everyone got A's,
especially because I could feel this is a partial consequence of my
own efforts. At the same time, I should report results corresponding
to actual student achievement. I hope you will look at the answers supplied and the remarks on grading and let me know if
you have any questions about the exam, the answers, or my grading.
A vector w is a linear combination of v1, v2, ..., vn if there are scalars a1, a2, ..., an so that v=SUMj=1najvj.
We study At(t+1)+B(t+2)(t+3)+C(t+4)(t+5)=t2. If this
equation is valid, then
(A+B+C)t2+(A+5B+9C)t+(6B+20C)=t2
Which leads to the system
1A+1B+1C=1 1A+5B+9C=0 0A+6B+20C=0Now I will write the augmented matrix and change the coefficient matrix to RREF:
( 1 1 1 | 1 ) ( 1 1 1 | 1 ) ( 1 0 -1 | 5/4 ) ( 1 0 0 | 46/32 ) ( 1 5 9 | 0 )~( 0 4 8 | -1 )~( 0 1 2 | -1/4 )~( 0 1 0 | -20/32 ) ( 0 6 20 | 0 ) ( 0 6 20 | 0 ) ( 0 0 8 | 6/4 ) ( 0 0 1 | 6/32 )Therefore the original system is row equivalent (which means, "has the same solutions as") to the system A=46/32 and B=-20/32 and C=6/32.
The answer to the original question is "Yes" and I am fairly confident
that
(46/32)t(t+1)+(-20/32)(t+2)(t+3)+(6/32)(t+4)(t+5)=t2.
Now I asked another question: can t be written as a linear combination of t(t+1) and (t+2)(t+3) and (t+4)(t+5)? I also asked if we could answer this question without any additional computation. In fact, the answer is "Yes". All we need to do is change the column augmenting the coefficient matrix so that it looks like
0 1 0instead of
1 0 0. The row operations will all still work, and we just carry along the last column. The resulting system will again be eA=something1 and B=something2 and C=something3. Therefore t is a linear combination of the three given polynomials.
Now I asked another question: are the three polynomials t(t+1) and (t+2)(t+3) and (t+4)(t+5) linearly independent? Here we consider the question: if At(t+1)+B(t+2)(t+3)+C(t+4)(t+5)=0, must A and B and C all be 0? Again, row reduction tells me that A=0 and B=0 and C=0 since row operations on a column with all 0 entries leave the column all 0's, so that, yes, indeed, these polynomials are linearly independent.
Problem 2
Are the functions cos(t) and [cos(t)]2 and
[cos(t)]3 linearly independent?
The vectors v1, v2, ..., vn are linearly independent if whenever SUMj=1najvj=0 then all of the aj's must be 0.
So we need to study
A cos(t)+B[cos(t)]2+C[cos(t)]3=0
Now it isn't totally clear what to do. In the previous case, we
actually relied upon 1 and t and t2 as a "natural" way to
look at polynomials, and used this way to obtain a system of linear
equations. Now one way to get a system of linear equations is to
"specialize" (?) the functional equation by evaluating it at various
t's and hope there will be enough information to make some conclusion
about the question.
If we let t=Pi/2 then the equation becomes A·0+B·0+C·0=0. But for any values of A and B and C, this is 0=0, so we get no information!
Now t=0 gives A+B+C=0. And t=Pi gives -A+B-C=0. And t=Pi/4 gives
(1/sqrt(2))A+(1/2)B+(1/[2sqrt(2)])C=0. And t=2Pi gives the same
equation as t=0 (because of 2Pi periodicity of cosine). Etc. and
etc. How long should we do this? How many t's, and how to choose them?
Well, so far we have this linear system:
A+B+C=0
-A+B-C=0
(1/sqrt(2))A+(1/2)B+(1/[2sqrt(2)])C=0
If we convert the coefficient matrix to RREF and get what we want (a
diagonal matrix with 1's) then we know that the functions are linearly
independent. I wouldn't think of working with fewer than three
equations for this reason. I can also hope that working with these
three equations will give me enough information. Of course, I will
admit honestly, if I didn't know these functions too well, I could
have chosen t=0 and t=2Pi and t=4Pi to get a linear system, and the
resulting RREF would certainly not have enough information for
me to decide. Oh well. So here we go (I don't need a column of 0's for
augmentation since the row reduction won't change them at all):
( 1 1 1 ) ( 1 1 1 ) ( 1 0 1 ) ( 1 0 0 ) ( -1 1 -1 )~( 0 2 0 )~( 0 1 0 )~( 0 1 0 ) ( 1/sqrt(2) 1/2 1/[2sqrt(2)] ) ( 0 (1/2)-(1/sqrt(2)) -1/[2sqrt(2)] ) ( 0 0 -1/[2sqrt(2)] ) ( 0 0 1 )I was actually lucky about the values of t suggested by students since the pivoting and row reduction were so easy. The resulting RREF is of course an abbreviation of the system A=0 and B=0 and C=0 so the answer to the original question is, "Yes, the functions cos(t) and [cos(t)]2 and [cos(t)]3 are linearly independent."
I remarked in class that I could have asked if the three functions
[cos(t)]2 and [sin(t)]2 and cos(2t) are linearly
independent. Of course, this example is a bit silly, but I would like
to illustrate what could happen. If I then write the
equation
A[cos(t)]2+B[sin(t)]2+Ccos(2t)=0
and from there, by specializing at t=blah and t=blahblah etc., deduce
a system of linear equations and try to show that the only solution
is the trivial solution (following the example above) I will
not be successful. Any such system will have rank (number of
non-zero rows in its RREF) at most 2. I need rank 3 to conclude that
A=0 and B=0 and C=0. This all happens because, in fact, the functions
[cos(t)]2 and [sin(t)]2 and cos(2t) are linearly
dependent. One of the early trig formulas (double angle stuff) tells us
that
1[cos(t)]2-1[sin(t)]2-cos(2t)=0
I want to be honest with you and remark that the logic and
computations supporting the logic can get complicated.
Problem 3
Are the vectors (4,3,2) and (3,2,3) and (-4,4,3) and (5,2,1) in
R3 linearly independent? Now I wrote the vector
equation:
A(4,3,2)+B(3,2,3)+C(-4,4,3)+D(5,2,1)=0 (this is (0,0,0) for this
instantiation of "linear independence") which gives me the system:
4A+3B-4C+5D=0 (from the first components of the vectors)
3A+2B+4C+2D=0 (from the second components of the vectors)
2A+3B+3C+1D=0 (from the third components of the vectors)
and therefore would need to row reduce
( 4 3 -4 5 ) ( 3 2 4 2 ) ( 2 3 3 1 )I started to do this, but then ... thought a bit. My goal was to get the RREF of this matrix, and use that to argue about whether the original system had solutions other than the trivial solution.
What can these RREF's look like? Let me write all of the RREF's possible whose first column (as here) has some entry which is not zero.
( 1 0 0 * ) ( 1 0 * 0 ) ( 1 0 * * ) ( 1 * 0 0 ) ( 1 * 0 * ) ( 1 * * 0 ) ( 1 * * * ) ( 0 1 0 * ) ( 0 1 * 0 ) ( 0 1 * * ) ( 0 0 1 0 ) ( 0 0 1 * ) ( 0 0 0 1 ) ( 0 0 0 0 ) ( 0 0 1 * ) ( 0 0 0 1 ) ( 0 0 0 0 ) ( 0 0 0 1 ) ( 0 0 0 0 ) ( 0 0 0 0 ) ( 0 0 0 0 )In all of these 3 by 4 matrices, the entry * stands for something which could be any number, zero or non-zero. I hope I haven't missed one! In every one of the matrices above, there will be non-trivial solutions to the related homogeneous system. For example, in the first matrix, D is free to be any value, and the equations can be made correct by selecting the correct values of A and B and C. In the second matrix, D=0 certainly (because of the last row) but C can be any value, and A and B can be selected to make the other two equations correct. In each row where there are *'s, those variables are free, and the leading 1 in the row represents a variable whose value can be chosen to make the corresponding equation correct. Therefore all of these RREF's represent homogeneous systems with non-trivial solutions. And notice that if the first column had been all 0's then A could have any value. So, in fact, a homogeneous system having 4 variables and 3 equations will always have a non-trivial solution.
| A homogeneous system with more variables than equations always has an infinite number of non-trivial solutions. |
HomilyThe students in this class are mostly juniors and seniors, and know the flaws and features of a Rutgers education. No matter how well-intentioned or skilled your instructors have been, by now you should know that your best teachers will be yourselves, using your own skills and efforts. That will almost surely continue for the rest of your lives. Most of your instruction will come through your own practice. Students cannot rely upon instructors to do everything, nor can students anticipate exams (or jobs!) which only test abilities that have been acquired casually, abilities that are either dimly remembered or invented on the spot. Most students in the class have considerable time and experience, and must do much more themselves to learn this material than they already have. |
The QotD
I gave students individualized 3 by 5 matrices whose entries were
"random" integers created by Maple in the range from -3 to
3. I told students that the matrices should be converted to RREF, and
that students doing this successfully would have 5 points added to
their first exam score. The results showed that some students did not
know what RREF was (that's after five hours of class time
relying on RREF). Many other students seemed to have serious
difficulty correctly completing a limited amount of rational number
arithmetic. My homily above would have included more
excoriation if I had known these results ahead of time.
/excoriate/ 1. a. remove part of the skin of (a person etc.) by abrasion. b. strip or peel off (skin). 2. censure severely. /homily/ 1. a sermon. 2. a tedious moralizing discourse.HOMEWORK
I began by writing the following on the side board, so that I would not mess up things again.
|
A linear combination of vectors is a sum of scalar multiples of the
vectors.
A collection of vectors is spanning if every vector can be written as the linear combination of vectors in the collection. A collection of vectors is linearly independent if, whenever a linear combination of the vectors is the zero vector, then every scalar coefficient of that linear combination must be zero. |
I wanted to suffer no further obloquy in this class. My online dictionary gives me this as a definition:
/obloquy/ n. 1. the state of being generally ill spoken of. 2. abuse, detraction.
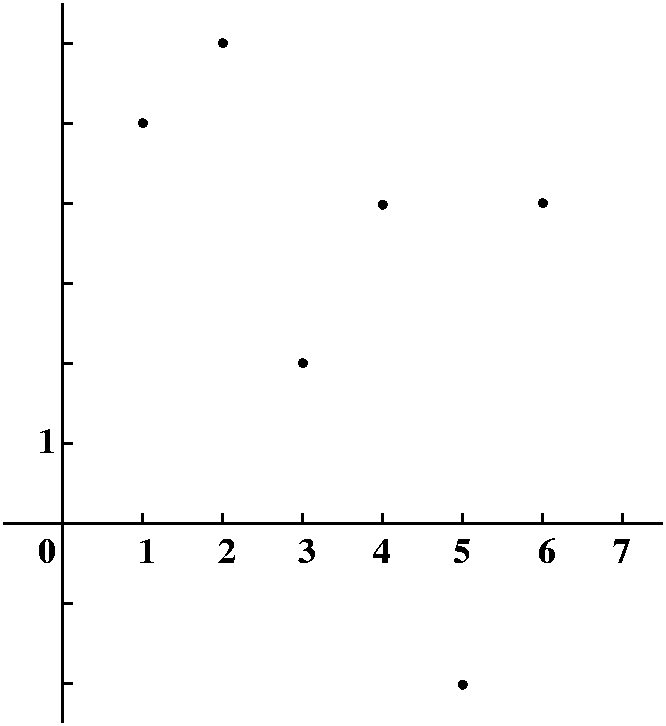
The language and ideas of linear algebra are used everywhere in applied science and engineering. Basic calculus deals fairly nicely with functions defined by formulas involving standard functions. I asked how we could understand more realistic data points. I will simplify, because I am lazy. I will assume that we measure some quantity at one unit intervals. Maybe we get the following:
| Tabular presentation of the data | Graphical
presentation of the data | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
We could look at the tabular data and try to understand it, or we could plot the data because the human brain has lots of processing ability for visual information. But a bunch of dots is not good enough -- we want to connect the dots. O.k., in practice this means that we would like to fit our data to some mathematical model. For example, we could try (not here!) the best fitting straight line or exponential or ... lots of things. But we could try to do something simpler. We could try to understand this data as just points on a piecewise linear graph. So I will interpolate the data with line segments, and even "complete" the graph by pushing down the ends to 0. The result is something like what's drawn to the right. I will call the function whose graph is drawn F(x). |
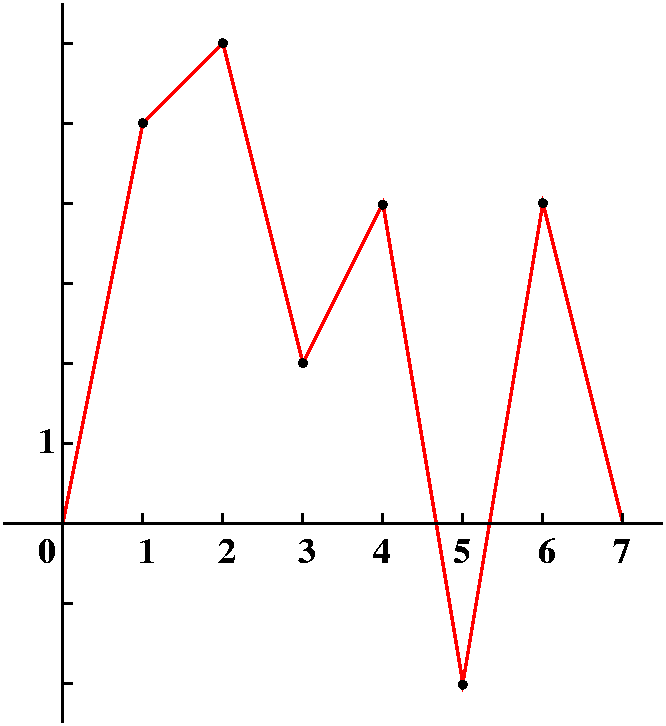
|
Meet the tent centered at the integer j
First,
here is complete information about the function Tj(x) which
you are supposed to get from the graph of Tj(x): (j
should be an integer)
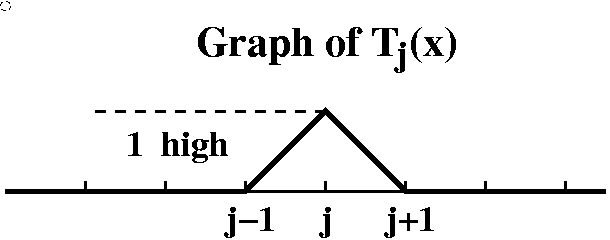
This is a peculiar function. It is 0 for x<j-1 and for x>j+1. It has height 1 at j, and interpolates linearly through the points (j-1,0), (j,1), and (j+1,0). I don't much want an explicit formula for Tj(x): we could clearly get one, although it would be a piecewise thing (but as several students observed, Tj(x) could be written quite easily in Laplace transform language!).
We can write F(x) in terms of these Tj(x)'s fairly
easily. Moving (as we were accustomed in Laplace transforms!) from
left to right, we first "need" T1(x). In fact, consider
5T1(x) and compare it to F(x). I claim that these functions
are exactly the same for x<=1. Well, they are both 0 for
x<=0. Both of these functions linearly interpolate between the
points (0,0) and (1,5), so in the interval from 0 to 1 the graphs must
be the same (two points still do determine a unique line!). Now
consider 5T1(x)+6T1(x) and F(x) compared for x's
less than 2. Since T2(x) is 0 for x<1, there is no chain
in the interval (-infinity,1]. But between 1 and 2, both of the
"pieces" T1(x) and T2(x) are non-zero. But the
sum of 5T1(x)+6T1(x) and F(x) match up at (1,5)
and (2,6) because we chose the coefficients so that they would. And
both of the "tents" are degree 1 polynomials so that their sum is
also, and certainly the graph of a degree 1 polynomial is a straight
line, so (again: lines determined by two points!) the sum
5T1(x)+6T1(x) and F(x) totally agree in the
interval from 1 to 2. Etc. What do I mean? Well, I mean that
F(x)= 5T1(x)+6T1(x)+2T1(x)+4T1(x)+
-2T1(x)+4T1(x).
These functions agree for all x.
Linear combinations of the tents span these piecewise linear
functions
If we piecewise linearly interpolate data given at
the integers, then the resulting function can be written as a linear
combination of the Tj's. Such linear combinations can be
useful in many ways (for example, the definite integral of F(x) is the
sum of constants multiplied by the integrals of the Tj(x),
each of which has total area equal to 1!). The Tj(x)'s are
enough to span all of these piecewise linear functions.
But maybe we don't need all of the Tj's. What if someone
came up to you and said, "Hey, you don't need T33(x) because:"
T33(x)=53T12(x)-4T5(x)+9T14(x)
Is this possibly correct? If it were correct, then the function
T33(x) would be redundant (extra, superfluous) in our
descriptions of the piecewise linear interpolations, and we wouldn't
need it in our linear combinations. But if
T33(x)=53T12(x)-4T5(x)+9T14(x)
were correct, it should be true for all x's. This means we can
pick any x we like to evaluate the functions, and the resulting
equation of numbers should be true. Hey: let's try x=33. This is not
an especially inspired choice, but it does make T33's value
equal to 1, and the value of the other "tents" in the equation equal
to 0. The equation then becomes 1=0 which is currently
false.
Therefore we can't throw out
T33(x). In fact, we need every Tj(x) (for each
integer j) to be able to write piecewise linear interpolations.
We have no extra Tj(x)'s: they are all
needed.
Let me rephrase stuff using some linear algebra language. Our "vectors" will be piecewise linear interpolations of data given at integer points, like F(x). If we consider the family of "vectors" given by the Tj(x)'s, for each integer j, then:
I emphasized that one reason I wanted to consider this example first is because we use linear algebra ideas constantly, and presenting them in a more routine setting may discourage noticing this. My second major example does, however, present things in a more routine setting, at least at first.
My "vectors" will be all polynomials of degree less than or equal to 2. So one example is 5x2-6x+(1/2). Another example is -(Pi)xx2+0x+223.67, etc. What can we say about this stuff?
I claim that every polynomial can be written as a sum of 1 and x and
x2 and the Kadakia polynomial,
K(x)=3x2-9x+4 (well, it was something like
this). Since the class showed signs of irritation (perhaps because the
instructor is from the planet Zornix, where conversations are done
with odors), I offered to verify that, say, the polynomial
17x2+44x-98 could indeed be written as a sum of 1 and x and
x2 and the (fabulous) Kadakia polynomial,
K(x)=3x2-9x+4. Thus I need to find numbers filling
the empty spaces in the equation below, and the numbers should make
the equation correct.
17x2+44x-98=[ ]1+[ ]x+[ ]x2+[ ]K(x)
Indeed, through great computational difficulties I wrote
17x2+44x-98=-781+91x+2x2+5K(x)
(I think this is correct, but again I am relying upon carbon-based
computation, not silicon-based computation!)
We discussed this and concluded that the span of 1 and x and
x2 and K(x) is all the polynomials of degree less
than or equal to 2. But, really, do we need all of these? That is, do
we need the four numbers (count them!) we wrote in the equation above,
or can we have fewer? Well, 1 and x and x2 and K(x)
are not linearly independent. They are, in fact, linearly
dependent. There is a linear combination of these four which is
zero. Look:
1K(x)+-3x2+-44x+981=0.
so that
K(x)=3x2+44x+-981
and we can "plug" this into the equation
17x2+44x-98=-781+91x+2x2+5K(x)
to get
17x2+44x-98=-781+91x+2x2+5(3x2+44x+-981
)
Groucho Marx declared:
| A child of five would understand this. Send someone to fetch a child of five. |
Some weird polynomials to change our point of view
Look at these polynomials of degree 2:
P(x)=x(x-1)
Q(x)=x(x-2)
R(x)=(x-1)(x-2)
Why these polynomials? Who would care
about such silly polynomials?
Are these polynomials linearly independent?
This was the QotD. I remarked that I was asking students to
show that if
A P(x)+B Q(x)+C R(x)=0
for all x, then the students would need to deduce that A=0 and B=0 and
C=0. I also remarked that I was interested in the logic which was used
more that any thing else.
1A+1B+1C=0
-1A-2B-3C=0
2C=0
and then I row reduced (by hand!) the coefficient matrix:( 1 1 1 ) ( 1 1 1 ) ( 1 0 1 ) ( 1 0 0 ) (-1 -2 -3 )~( 0 -1 -2 )~( 0 1 2 )~( 0 1 0 ) ( 0 0 2 ) ( 0 0 2 ) ( 0 0 2 ) ( 0 0 1 )This shows that the original system was row equivalent to the system A=0 and B=0 and C=0 (remember that "row equivalent"<==>"same solution set"), therefore there are no solutions to the equation A P(x)+B Q(x)+C R(x)=0 except the trivial solution. And therefore P(x) and Q(x) and R(x) are linearly independent: none of them are "redundant".
But can I describe all of the deg<=2 polys this way?
I assert that every polynomial of degree less than or equal to
2 can be described as a linear combination of P(x) and Q(x) and
R(x). How would I verify this claim? Please note that
I am more interested in the logic than the computational details
here!
I should be able to write x2 as sum of P(x) and Q(x) and
R(x). This means I should be able to solve the equation
A P(x)+B Q(x)+C R(x)=x2.
Just as above, this leads to an augmented matrix which looks like:
( 1 1 1 | 1 ) ( 1 0 0 | FRED ) (-1 -2 -3 | 0 )~~~( 0 1 0 | STANLEY ) ( 0 0 2 | 0 ) ( 0 0 1 | MARISSA )I know this is true, since I already did the row operations above. Right now I am not totally interested in the values of FRED and STANLEY and MARISSA but I know that the row operations just involve adding and multiplying and interchanging, so there must be such numbers. And therefore there are numbers which satisfy the equation:
( 1 1 1 | 0 ) (-1 -2 -3 | 1 ) ( 0 0 2 | 0 )and just as before there will be solutions, and so x is in the span of P(x) and Q(x) and R(x). And so is 1. Since the linear combinations of x2 and x and 1 are all of the polynomials of degree 2 or less, and each of x2 and x and 1 is a linear combination of P(x) and Q(x) and R(x), I know that the span of P(x) and Q(x) and R(x) is all polynomials of degree 2 or less. So each of P(x) and Q(x) and R(x) is needed and there are "enough" of them. Notice that all I needed to do was verify that the RREF of the matrix above was in the 1 0 0 etc. form. Then everything automatically followed!
|
|
So P(x) and Q(x) and R(x) are a basis of the polynomials of degree less than or equal to 2.
Why would we look at P(x) and Q(x) and
R(x)?
Suppose again I have data points, let's say (0,13) and (1,-78) and
(2,37). I could linearly interpolation as we did above. If I want to be
a bit more sophisticated, and get maybe something smoother, I could
try to get a polynomial Ax2+Bx+C which fits these data
points. Here is the polynomial:
[37/2]P(x)+[-78/-1]Q(x)+[13/2]R(x). How was this remarkable
computation done? Well, I know certain function values
| The function | Its values when x=0 and x=1 and x=2 | ||
|---|---|---|---|
| P(x) | 0 | 0 | 2 |
| Q(x) | 0 | -1 | 0 |
| R(x) | 2 | 0 | 0 |
so when I "plug in" x=0 and x=1 and x=2 in the linear combination A P(x)+B Q(x)+C R(x) and I want to get 13 and -78 and 37, respectively, the structure of the table makes it very easy to find A and B and C. If we want to interpolate quadratically, I would get a function defined by a simple formula using this basis. In fact, these functions are very useful in quadratic interpolation, and in the use of splines, a valuable technique for numerical approximation of solutions of ordinary and partial differential equations.
HOMEWORK
Please read the textbook: chapter 7.6 and the first sections of
chapter 8.
3x1+2x2+x3-x4=A
4x1-1x2+5x3+x4=B
2x1+5x2-3x3-3x4=C
These questions will be important:
(3 2 1 -1 | A) (4 -1 5 1 | B) (2 5 -3 -3 | C)The vertical bar is used to distinguish between the two sides of the equations. It is useful to change the collection of linear equations so that the system becomes easier to understand. These changes should all be reversible, so that these equivalent systems will have the same set of solutions. What sorts of "tricks" can we do to the equations? Basically there turn out to be three tricks. And they are called
There are all sorts of things one can do with elementary row operations, but one very useful goal is to change the coefficient matrix into reduced row echelon form, RREF. This means:
3 by 4 2 by 7 (1 0 0 0) (1 0 0 0 0 4 4) (0 0 1 5) (0 0 0 0 1 2 3) (0 0 0 0)And here is essentially a complete list of all possible 3 by 3 RREF matrices:
(1 0 0) (1 0 *) (1 * *) (1 0 0) (0 1 0) (0 0 1) (0 0 0) (0 1 0) (0 1 *) (0 0 0) (0 0 1) (0 0 1) (0 0 0) (0 0 0) (0 0 1) (0 0 0) (0 0 0) (0 0 0) (0 0 0) (0 0 0) (0 0 0)The entries * may be any number, 0 or non-zero. There aren't very many and they are easy to understand. Notice that each of these is essentially different from the others: they represent coefficient matrices with very different solution sets.
I then tried to use row operations on the augmented matrix of my system of linear equations so that the coefficient matrix was in RREF. I did this by hand. What follows is taken from a Maple session (I did remove my errors!). Maple does have a rref command, but it also allows row operations one at a time. I will comment in this manner about each command.
>with(linalg):
This loads the linear algebra package.
>M:=matrix(3,5,[3,2,1,-1,A,4,-1,5,1,B,2,5,-3,-3,C]);
[3 2 1 -1 A]
[ ]
M := [4 -1 5 1 B]
[ ]
[2 5 -3 -3 C]
This command just creates a matrix of specified size
with the listed entries.
>mulrow(M,1,1/3);
[1 2/3 1/3 -1/3 A/3]
[ ]
[4 -1 5 1 B ]
[ ]
[2 5 -3 -3 C ]
Multiply row 1 by a third. Creates an initial 1.
>addrow(%,1,2,-4);
[1 2/3 1/3 -1/3 A/3 ]
[ ]
[ 4 A ]
[0 -11/3 11/3 7/3 - --- + B]
[ 3 ]
[ ]
[2 5 -3 -3 C ]
Add -4 times row 1 to row 2. This "pivots" and makes the
(2,1) entry of the coefficient matrix 0.
>addrow(%,1,3,-2);
[1 2/3 1/3 -1/3 A/3 ]
[ ]
[ 4 A ]
[0 -11/3 11/3 7/3 - --- + B]
[ 3 ]
[ ]
[ 2 A ]
[0 11/3 -11/3 -7/3 - --- + C]
[ 3 ]
Add -2 times row 1 to row 3. So the (3,1) entry becomes 0.
>mulrow(%,2,-3/11);
[1 2/3 1/3 -1/3 A/3 ]
[ ]
[ -7 4 A 3 B]
[0 1 -1 -- --- - ---]
[ 11 11 11 ]
[ ]
[ 2 A ]
[0 11/3 -11/3 -7/3 - --- + C]
3
Makes another leading 1.
>addrow(%,2,1,-2/3);
[ A 2 B]
[1 0 1 1/11 ---- + ---]
[ 11 11 ]
[ ]
[ -7 4 A 3 B ]
[0 1 -1 -- --- - --- ]
[ 11 11 11 ]
[ ]
[ 2 A ]
[0 11/3 -11/3 -7/3 - --- + C ]
[ 3 ]
Makes the (1,2) entry equal to 0.
>addrow(%,2,3,-11/3);
[ A 2 B ]
[1 0 1 1/11 ---- + --- ]
[ 11 11 ]
[ ]
[ -7 4 A 3 B ]
[0 1 -1 -- --- - --- ]
[ 11 11 11 ]
[ ]
[0 0 0 0 -2 A + B + C]
And now the (3,2) entry is 0. The coefficient matrix
is now in RREF.
Well, this went a heck of a lot better than when I did it in class. I
will try, as I said, to avoid doing very much row reduction in
class. I am totally inept at it.
Now back to the questions:
What if I know -2A+B+C=0? Let's choose some values of A and B and C which will make this true. How about A=7 and B=34 and C=-20. Then -2A+B+C=-2(7)+34-20=0 (I hope). The RREF system then becomes (inserting these values of A and B and C [I did this in my head so there may be ... errors]):
[ 75 ]
[1 0 1 1/11 ---- ]
[ 11 ]
[ ]
[ -7 74 ]
[0 1 -1 -- - ---- ]
[ 11 11 ]
[ ]
[0 0 0 0 0 ]
Then the first equation (unabbreviated) is
x1+x3+(1/[11])x4=([75]/[11]) so thatBe sure to look carefully at the signs, to check on what I've written. The equations have been written this way so that you can see that x3 and x4 are free. That is, I can give any values for these variables. Then the other variables (x1 and x2) will have their values specified by what is already given. So: we select A and B and C satisfying the compatibility condition. Then there will be a two-parameter family of solutions to the original system of linear equations. Notice that we get solutions exactly when the compatibility condition is satisfied: there are solutions if and only if (as math folks might say) the compatibility condition is correct.
The logic here is actually "easy". Since all the computational steps we performed are reversible, I know that the assertions I just made are correct. What is more wonderful is that the general situation will always be much like this.
What RREF does in general
Take your original augmented matrix, and put
the coefficient matrix into RREF. Then you get something like
(BLOCK OF 1's & 0's WITH| JJJJJJ UU UU NN N K K | Linear stuff ) (THE 1's MOVING DOWN AND| JJ UU UU N N N KK | from original) (TO THE RIGHT. | JJJJ UUUUUU N NN K K | right sides ) (--------------------------------------------------------------------) ( MAYBE HERE SEVERAL | More such ) ( ROWS OF 0'S | linear stuff )Please observe that the lower right-hand corner now plays the part of the compatibility conditions which must be satisfied. All of those linear "fragments" must be equal to 0 if the original system has solutions. Now if these are 0, we can "read off" solutions in much the same manner as the example. The block labeled JUNK in fact tells us with its width how many free parameters there are in the solutions. Notice that the JUNK block could have size 0 (for example, consider the silly system x1=567,672, already in RREF!) and in that case the system would have only one solution.
I then started to look at the vocabulary of linear algebra, and made a few dreadful mistakes. My idea was to give examples of some fundamental definitions, and show how considering candidates for examples satisfying the definitions turns out to be studying systems of linear equations. Well, what follows is what I should have done, maybe.
Linear combinations
First, I asked if w=(3,1,2,3) was equal to a sum of scalar
multiples of the vectors v1=(3,3,-1,2) and
v2=(5,2,-3,2) and v3=(-2,4,5,6). So now:
|
|
In this case, the vector equation
w=a1v1+a2v2+a3v3.
For the vectors listed above, we can look at each of the components of
the vectors in R4 and get a system of linear equations:
3a1+3a2-2a3=3 (from the first
components)
1a1+3a2+4a3=1 (from the second
components)
2a1-1a2+5a3=2 (from the third
components)
3a1+2a2+6a3=3 (from the fourth
components)
If this system has a solution, then w is equal to a linear combination
of v1 and v2 and v3. If this system
does not have a solution, then w is not equal to such a linear
combination.
|
|
|
|
/redundant/
1. superfluous; not needed.
2. that can be omitted without any loss of significance.
5sin(t-4) is a linear combination of sin(t) and cos(t), with scalars equal to 5cos(-4) and 5sin(-4). How can we systematize this idea of redundancy, or the idea of not being redundant?
|
|
The functions sin(t) and cos(t) and 5sin(t-4) are linearly dependent
since
5cos(-4)sin(t)+5sin(-4)cos(t)+-15sin(t-4)=0.
The scalar coefficients are 5cos(-4) and 5sin(-4) and -1.
Here is a more routine example, in some sense. Consider the following
vectors in R5: v1=(2,3,4,5,7) and
v2=(8,2,3,3,4) and v3=(-2,7,-3,5,5) and
v4=(0,9,9,1,1). Are these vectors linearly dependent? We
are asking for solutions to
a1v1+a2v2+a3v3+a4v4=0
so that not all of the aj's are 0.
We can translate that vector equation in R5 into a system
of 5 linear equations:
2a1+8a2-2a3+0a4=0 (from
the first components)
3a1+2a2+7a3+9a4=0 (from
the second components)
4a1+3a2-3a3+9a4=0 (from
the third components)
5a1+3a2+5a3+1a4=0 (from
the fourth components)
7a1+4a2+5a3+1a4=0 (from
the fifth components)
This is a homogeneous system of equations and we want to know if there is a non-trivial solution (where at least one of the variables is not 0).
|
|
It is not difficult to see if the example I just wrote is linearly dependent. Look:
> with(linalg):
Warning, the protected names norm and trace have been redefined and
unprotected
> M:=matrix(5,4,[2,8,-2,0,3,2,7,9,4,3,-3,9,5,3,5,1,7,4,5,1]);
[2 8 -2 0]
[ ]
[3 2 7 9]
[ ]
M := [4 3 -3 9]
[ ]
[5 3 5 1]
[ ]
[7 4 5 1]
> rref(M);
[1 0 0 0]
[ ]
[0 1 0 0]
[ ]
[0 0 1 0]
[ ]
[0 0 0 1]
[ ]
[0 0 0 0]
Since the RREF of the coefficient matrix has no JUNK block, I know
that the linear system I wrote is row equivalent to the system
a1=0 and a2=0 and a3=0 and
a4=0 and the only solution of that system is the trivial
solution of all 0's. More on linear independence and dependence next
time.
The QotD
I asked if tsome odd number is a linear combination of
various teven number's. I expected a solution using simple
symmetry: switching t to -t for any non-zero t leads to a
contradition.
Here is a more explicit solution. I asked if t67 could be
written as a linear combination of t2, t16,
t34, t98, and t112. If we can
write
t67=At2+Bt16+Ct34+Dt98+Et112
for some constants A, B, C, D, and E, then consider:
t=1:1=A+B+C+D+E
t=-1:-1=A+B+C+D+E
which would imply 1=-1. Therefore the original assumption is
incorrect.
HOMEWORK
Please read the first sections of chapter 8. Hand in the following
problems on
Tuesday:
8.1: 19, 23, 29 and 8.2: 11, 15. Also, are the functions
et and e2t and e3t linearly
independent? Explain your answer, please.
I will try to get the solutions back to you by Thursday.
I will go to a lecture on Monday from 3 to 4 but will be in my office
for office hours after 4.
| Goals Students should know the definition of the Laplace transform. They should be able to compute simple Laplace transforms "by hand" and should be able to use a table of Laplace transforms to solve initial value problems for constant coefficient ODE's. They should be able to write "rough" data in terms of Dirac and Heaviside functions. They should be able to recognize and use simple results regarding Laplace transforms. |
I hope that students can do problems covering this material, especially since
|
Today begins the portion of the course related to linear algebra. I tried to give some idea of the importance of this material. One way was to list the math department courses devoted to linear algebra. Another way I tried was to give a comparative description of linear algebra in various settings appropriate to engineering.
|
|
|
|
|
|
|
|
Wassup?
I will first examine how to strip
irrelevancies from systmes of linear equations. I will want a way to detect
essential aspects of these systems (RREF: reduced row echelon
form). Then I'll need to describe these "essential" aspects. I will
also want to discuss how to invert matrices in several ways. Another
topic which is wonderfully useful is diagonalization of matrices,
which will provide great computational efficiencies when it can be
used.
Vocabulary
There are a bunch of terms which students should learn. Included are:
homogeneous, inhomogeneous, consistent, inconsistent, basis, linear
independence, linear combination, spanning, subspace, dimension, rank,
eigenvalue, eigenvector, matrix addition and matrix multiplication,
symmetric, diagonalization. I will certainly ask for definitions
of some of these on exams.
Silly linear algebra questions
We discussed these questions. I hope that after we are done, students
will be able to find, understand, and support (say, in writing!)
answers to these questions.
We discussed, debated, and perhaps did not bet about answers to these questions. This was difficult, although a number of students carefully slept through it.
I discussed how to get a matrix, and how substituting solutions of a linear system, one into the other, leads to the definition of matrix multiplication. The definition of matrix multiplication did not occur without many examples. The abbreviations I use are now generally accepted, principally because they are needed in practice. We reviewed how to get the matrix product.
Matrix addition is both commutative and associative. Matrix multiplication, however, is associative and, since products in different orders might matter, we need to be careful that we don't use commutativity because
The QotD
Find two 2-by-2 matrices A and B so that AB is not the same as BA.
(This turns out not to be too difficult since almost any A and B will
work, but not, as we remarked, an A whose entries are all 0's.)
Homework
Look at the syllabus. Start to read chapter 8.
Maintained by greenfie@math.rutgers.edu and last modified 9/4/2004.